
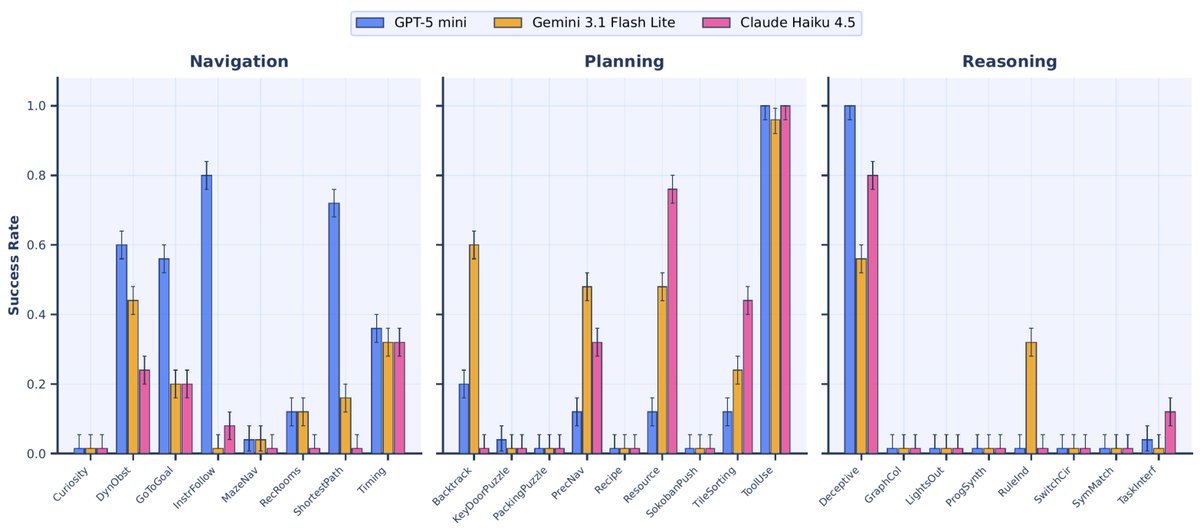
Hard tasks expose where LLM agents still break 🧱
In our LLM evals, several reasoning-heavy tasks are near-zero / zero success:
GraphColoring, LightsOut, SwitchCircuit, ProgramSynthesis, and SymbolMatching.
Sequential search state tracking is still very unsolved.
1
7
1,037

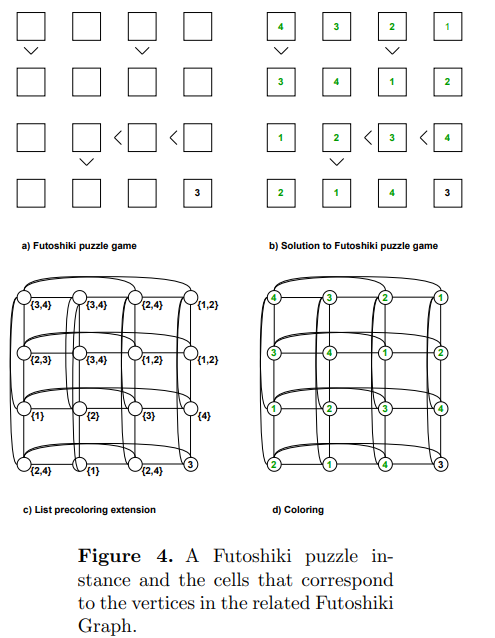
🧠🧩 Can graph coloring solve logic puzzles faster?
This IJOCTA paper presents a list coloring–based algorithm for the Futoshiki puzzle, outperforming backtracking in experiments.
📍 IJOCTA, Vol. 14, Issue 4
🔗accscience.com/journal/IJOCT…
#Puzzles #Algorithms #GraphColoring #IJOCTA
2
97




2 Jun 2025
🎥 The replay is live!
Watch our joint webinar with Fondazione LINKS on how neutral atom quantum processors can help solve complex optimization problems like graph coloring.
🔗 Watch now: youtu.be/FoS2WCJsR2k?si=Ofz8…
#QuantumComputing #Optimization #GraphColoring

1
2
3
396

30 Sep 2024
Happy to share my first tweet! Here’s a simple app I built during my uni years that visualizes graph coloring algorithms. 🎨📊
🔗 GitHub Link github.com/yllberisha/GraphC…
#GraphColoring #Algorithms #DataScience #Coding #Tech #StudentProject #OpenSource
How does that look? 😊
1
3
81
20 Dec 2023
It feels great when you get one of those emails from a peer (@RichVuduc this time) starting with "Congratulations!".
I guess you'll see our latest work on #GraphColoring with applications on #QuantumComputing at @IPDPS.
4
103

3 Jun 2023
One student, in order, to prove GraphColoring is in NP gave a polynomial time algorithm. 🤦♂️
3
5
469

8 Jul 2022
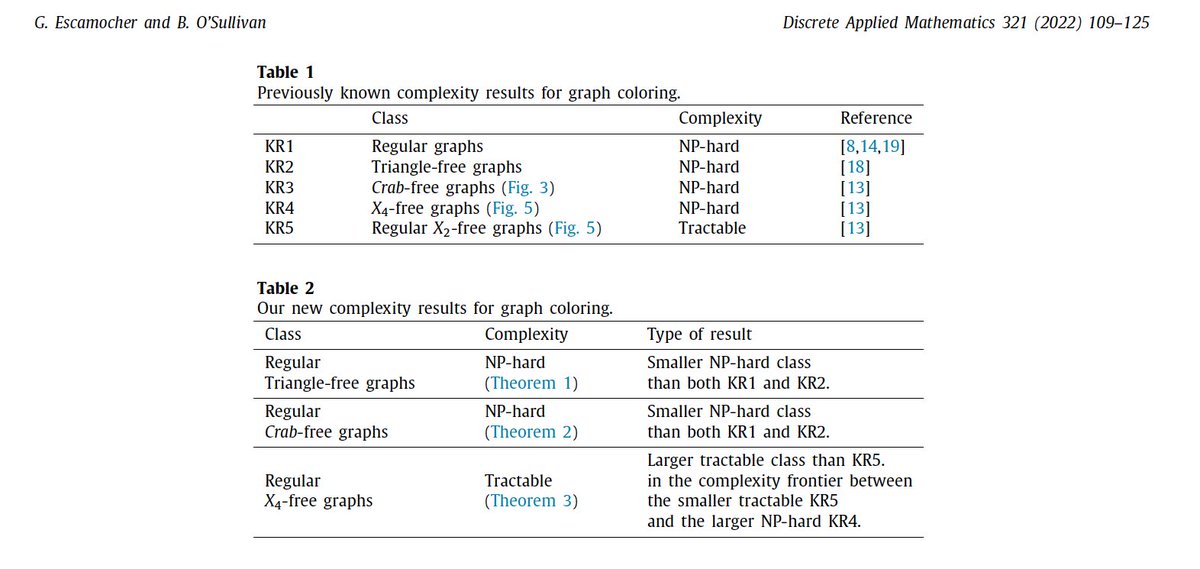
Our latest paper in the Journal of Discrete Applied Mathematics. #GraphColoring #Mathematics @insight_centre @crt_ai

1
7

26 Dec 2020
A Java-based #Memetic Algorithm Framework
buff.ly/3p8gI0a
With open-sourced code at buff.ly/3rkf7Gu
and simple examples of #TSP, #MaxSAT, #PHP model, #GraphColoring
1
2

💡 موضوع ارائه
Sublinear Algorithms for (Delta 1) Vertex Coloring
📘 مخاطب: علاقمندان به مباحث الگوریتمهای گرافی
#Webinar
#WSS_2020
#GraphStreaming
#SublinearTimeAlgorithms
#GraphColoring
❄️ @WSS_SUT
1

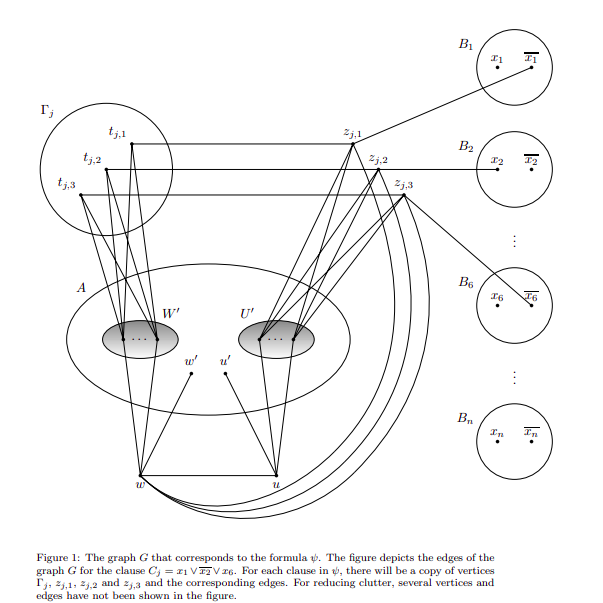
Excited to share that Sriram Bhavyarapu, @sbjoshi, @subruk, and @swamikare extended version of the paper “On Tractability of (k, i)-coloring” got accepted in Discrete Applied Mathematics.
Paper Link: arxiv.org/pdf/1802.03634.pdf
#cseiith #graphcoloring #graphs
1
14

10 Jul 2019
BioDecoded Daily Digest | July 10, 2019
biodecoded.com/2019/07/10/da…
#AI #art #genomics #biomarker #ReinforcementLearning #GraphColoring



2
2
10 Jul 2019
Coloring Big Graphs with AlphaGoZero | arXiv
arxiv.org/abs/1902.10162
#ReinforcementLearning #GraphColoring
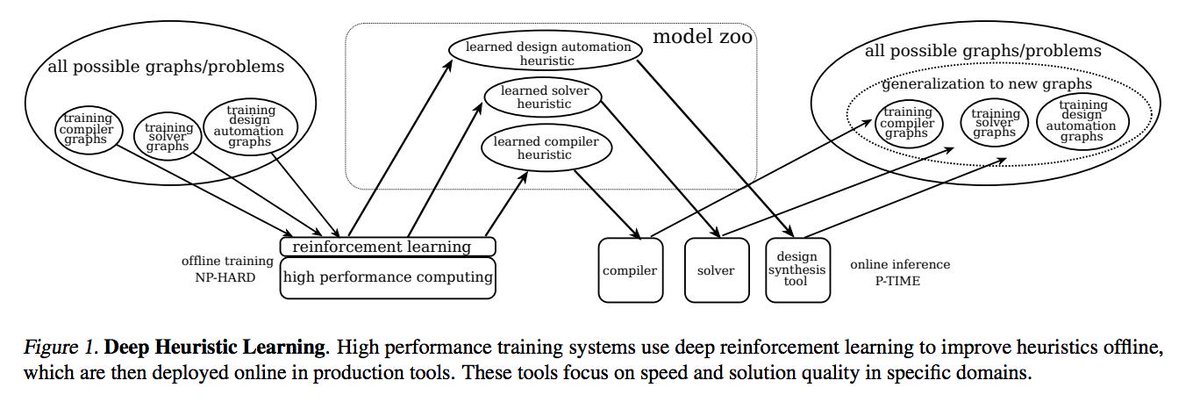

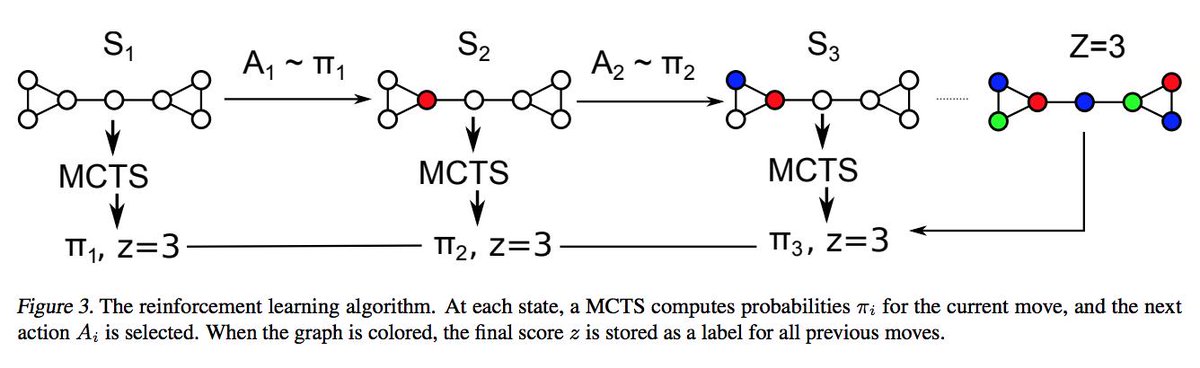
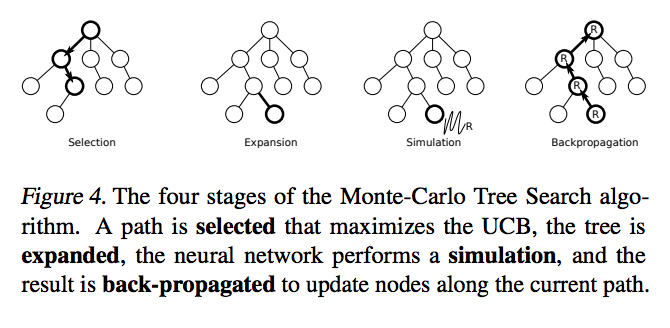
2
1

18 Jun 2019
1
10 Mar 2019
BioDecoded Daily Digest | March 10, 2019
biodecoded.com/2019/03/10/da…
#AI #art #genomics #biomarker #ReinforcementLearning #GraphColoring



2
10 Mar 2019
Coloring Big Graphs with AlphaGoZero | arXiv
arxiv.org/abs/1902.10162
#ReinforcementLearning #GraphColoring
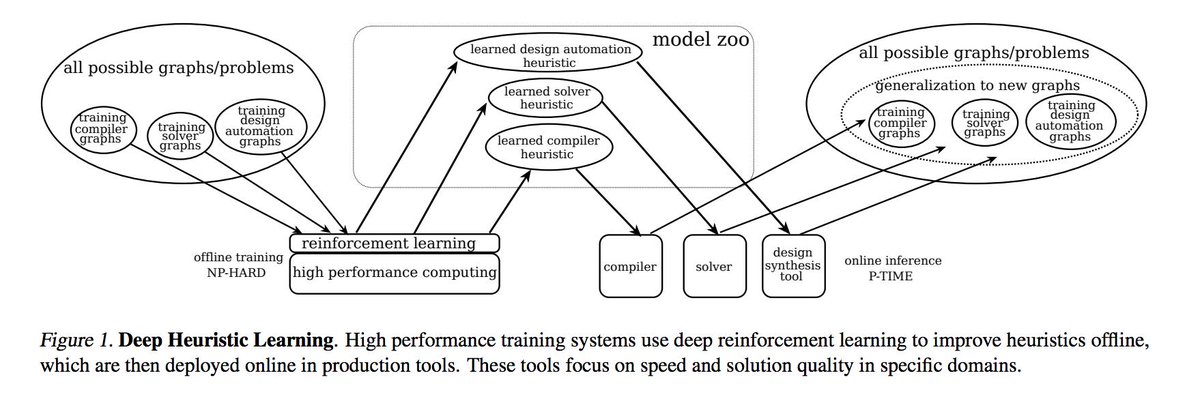
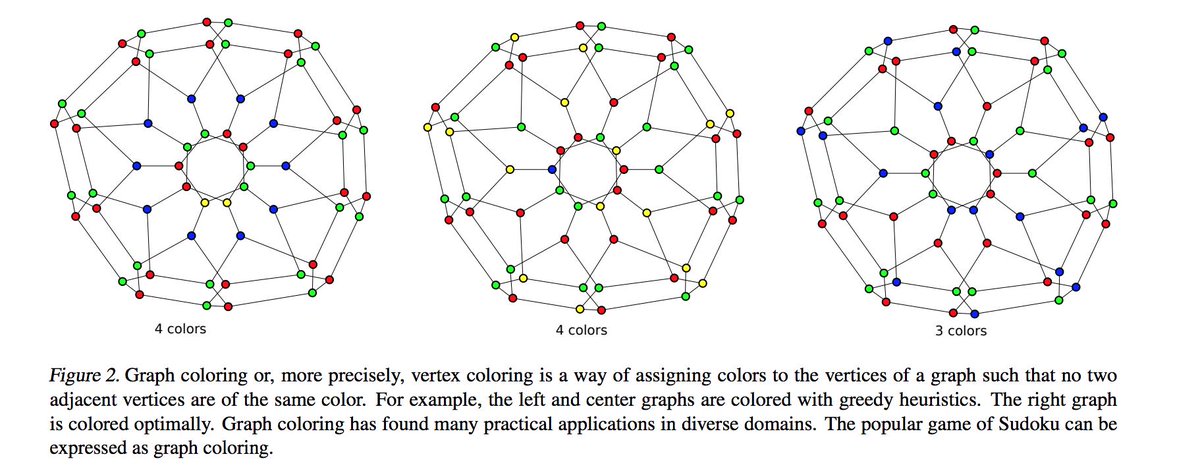
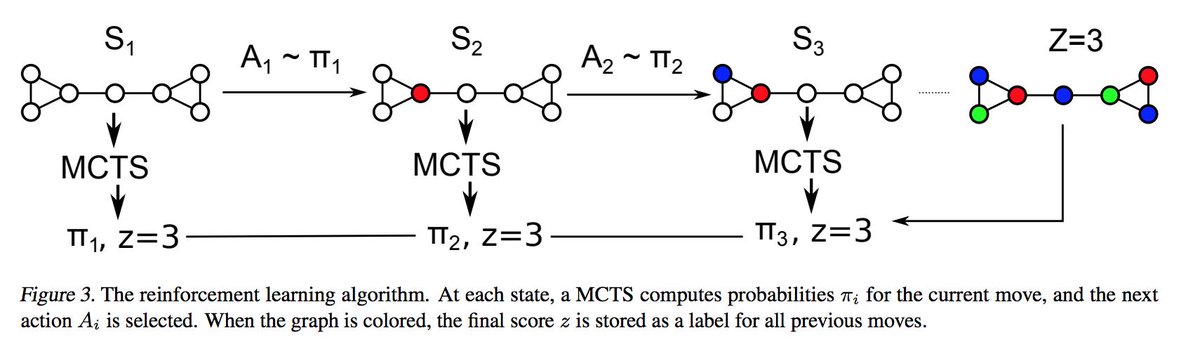
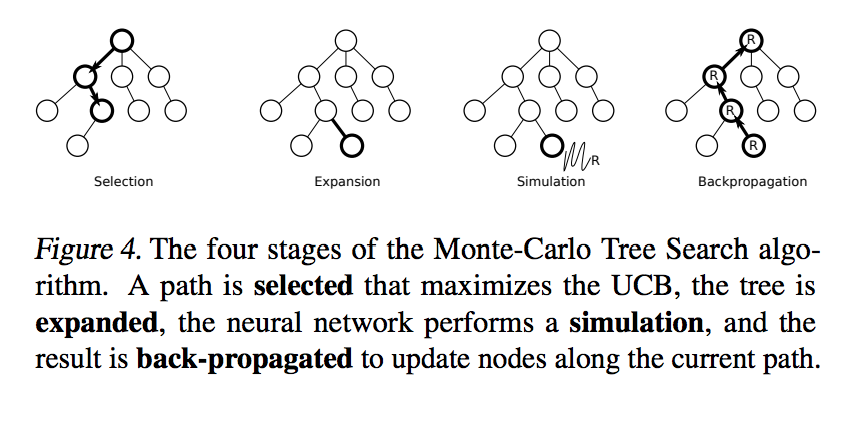
1


21 Dec 2015
The Appies are coming....
#the_appies #appies #comingsoon #newapp #graphcolouring #graphcoloring #newgame #appcomingsoon
1

31 Oct 2015
What Coloring Books Have in Common With Networks and Nodes wired.com/2015/10/what-color… #Science #graphcoloring #graphtheory