
@Google I am getting redirects on Google Search Console that should not be happening as the submitted URLs have been tested and have 0 redirects per httpstatus
6

Errors are a separate concern, modeled by the error dialect — and the first tell is the mechanism: a deny is a return value ({ allowed: false, code }).
Whereas an error is thrown. Different semantics.
Every thrown error extends one BaseError kernel carrying: domain · code · kind · httpStatus · meta
1
12



May 13
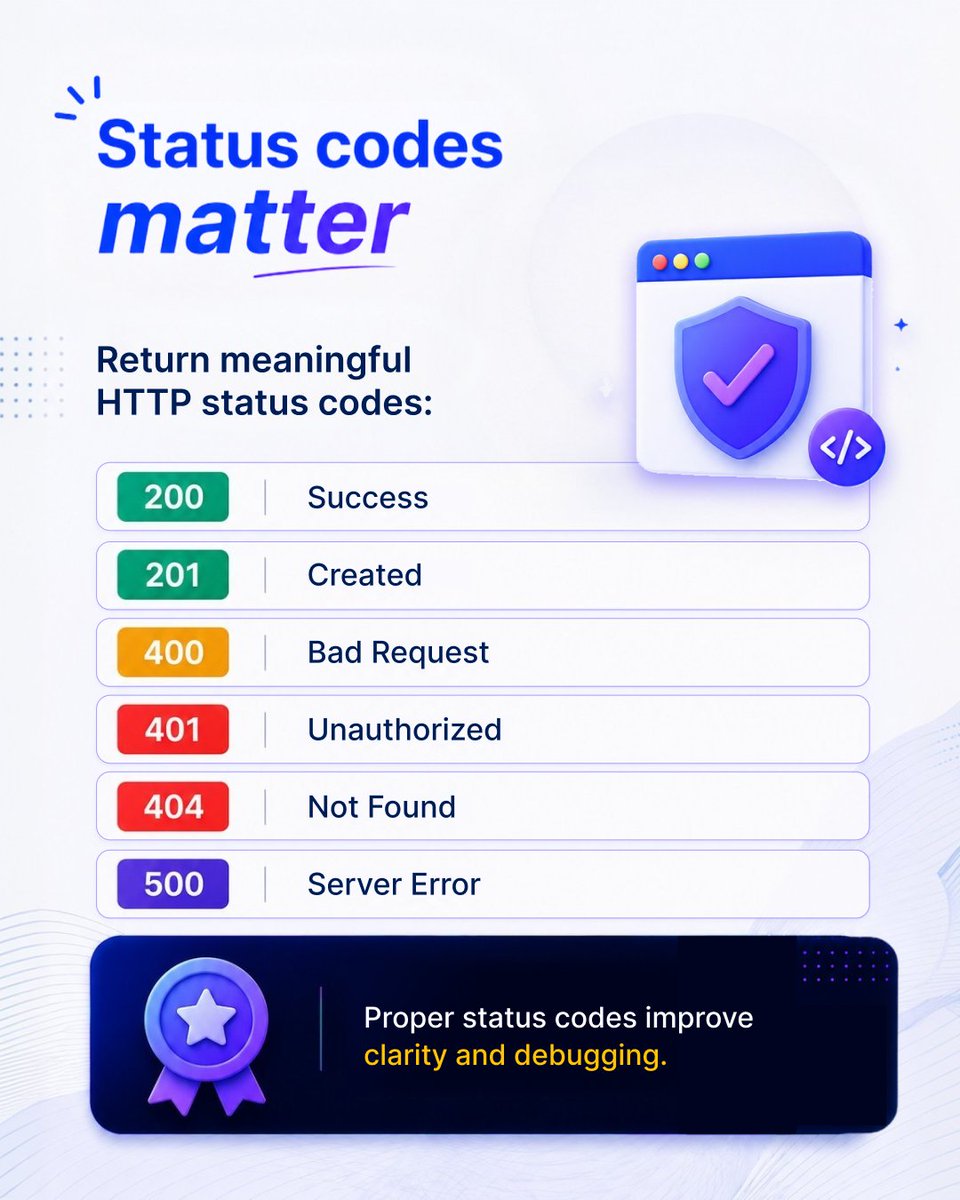
Good APIs communicate clearly even when something goes wrong.
Use meaningful status codes to improve API clarity 👇
#RESTAPI #HTTPStatus #Backend
1
7

Apr 28
I'm trying out a new experimental API for ai-retry
It's built on two basic primitives: `error()` and `result()`
These can be composed into higher-level conditions like `httpStatus(529, 'overloaded')` or finishReason('content-filter')
Each condition ends in `switch` or `retry`

4
382

Apr 27
今のプロジェクト
バックエンドで純正常系の想定内エラーが発生した場合でもHttpStatusを200で返却するように設計してるんですけど微妙すぎません?
※プロジェクトの指針の話ではなく設計方針として
3
687

Apr 27
Your connection works, but the provider rejected a test request. Often a model-access or quota issue.
Details
message: Gateway returned HTTP 404
httpStatus: 404
endpoint: cf-api.derouter.ai/
checkedAt: 2026-04-27T01:26:20.047Z 你好,刚充值完,报 404 是啥原因呢🤔这是 claude 客户端返回的报错
95

Apr 14
This is going to be big! 🤯
HttpStatus MCP Server by @domainerplus 👇
MCP enabled API tools for mocking, testing, monitoring
Check the hunted.space/calendar for more!
ift.tt/Xxl52aK
1
1
35



Curious about HTTP 204 Status Code? Learn what it means, how it works, and why it’s important for websites in this beginner-friendly guide.
#WebDevelopment #HTTPStatus #WebHosting #bodHOST
bodhost.com/kb/what-is-204-s…
1
11

Vigilance.fr #Vulnerability of #Asterisk Open Source: Cross Site Scripting via /httpstatus. #security vigilance.fr/vulnerability/A…
5

Vigilance.fr #Vulnérabilité de #Asterisk Open Source : Cross Site Scripting via /httpstatus. #sécurité vigilance.fr/vulnerabilite/A…
10

Apr 4
昔Firefoxのバグを回避できず最終手段としてAPIサーバーからはレスポンスボディーにHTTPSTATUSを返すようにしてクライアント側でHTTPSTATUSを無視してボディーのHTTPSTATUSで判定するようにしたのを思い出しました・・・
1
1,346

Mar 30
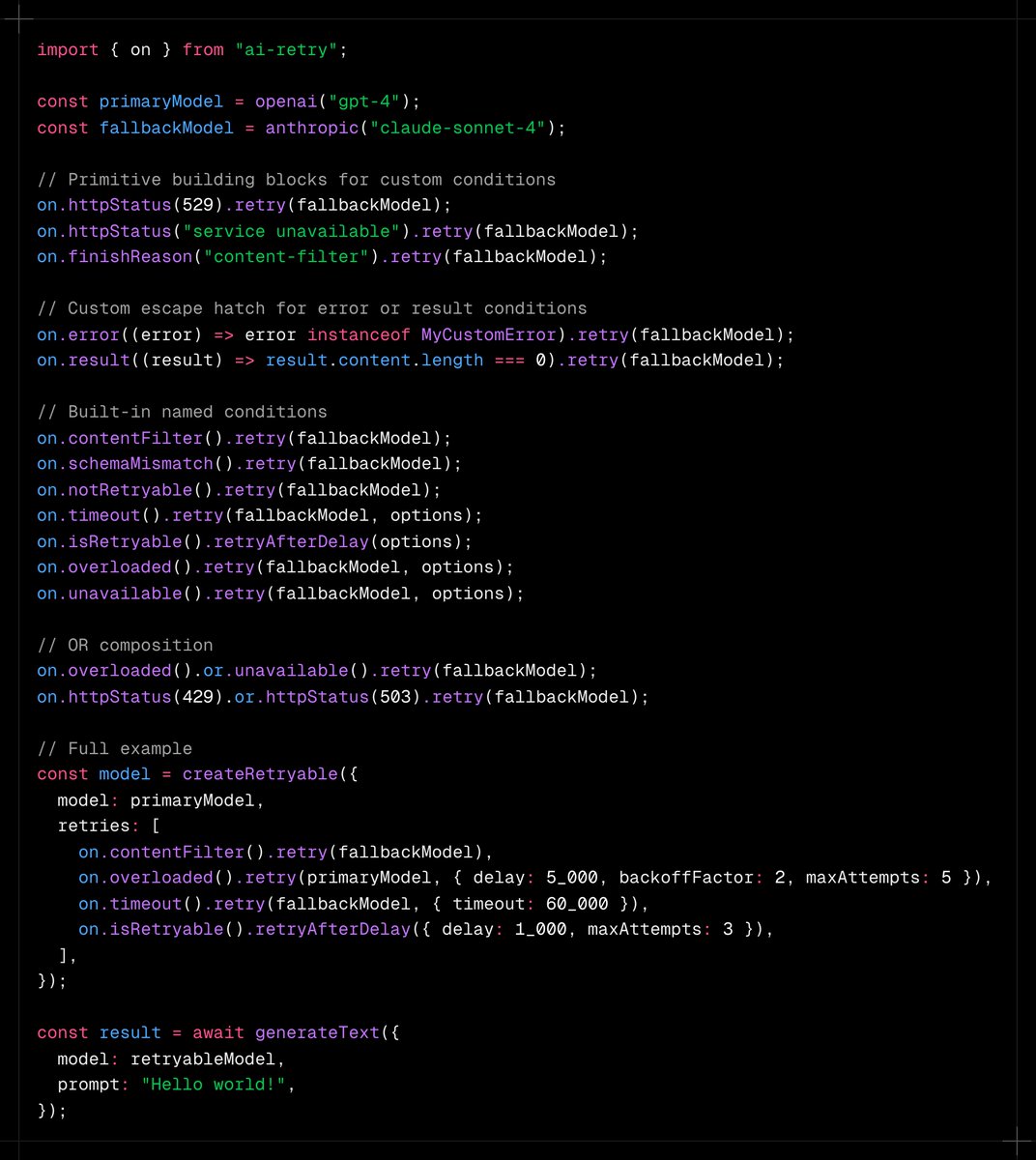
I'm thinking about refactoring `ai-retry` for @aisdk with a fluent API:
- start with a condition like finishReason, httpStatus, timeout, …
- chain options like delay, backoff, max attempts, ...
- finalize the chain with retry(fallbackModel)
I explored this idea with Claude and it suggested an Chai-like `on` condition as entry point
It's nice that typing `on.` would trigger autocomplete for all conditions
I'm not sure yet if this is a simplification over the current API with single retryable functions
4
249

Mar 21
10 Free tools for technical SEO that can replace $500 monthly subscription:
1. PageSpeed Insight
2. Screaming Frog SEO Spider
3. Google Lighthouse
4. HTTPStatus 10
5. GA4
6. Robots.txt Tester
7. Pingdom Website Speed Test
8. WebPageTest
9. SEOlyzer
10. W3 Validator
1
2
54

Mar 15
SEO Tips!
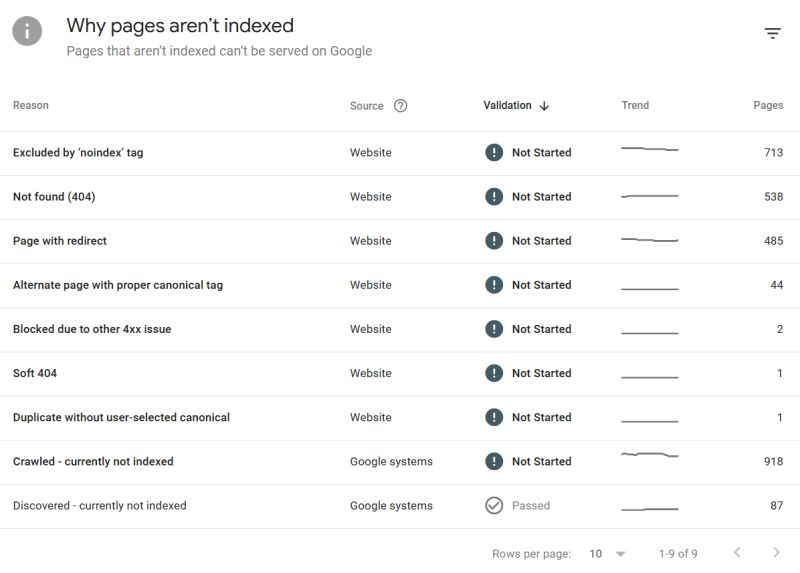
If you are in SEO and you are unsure on how to deal with non indexed page reasons & getting to know search console - here are some things that may help you.
Lesson 1: How to use performance tools in Google Search Console
lnkd.in/eiAevtww
Lesson 2: How to use URL Inspection tool in Google Search Console
lnkd.in/efC6TArw
Lesson 3: Google Discover - what is it?
lnkd.in/eXsHNmyW
Lesson 4: An introduction to Page Indexing / Non Indexed Pages in Search Console
lnkd.in/ezzhkVZT
Lesson 5: Alternative Page with Proper Canonicals
lnkd.in/edYu4hdP
Lesson 6: Page with Redirect
lnkd.in/e7cGzw6c
I will be recording more videos for other non indexed page reasons - this should get you started.
Below is further guidance:
PRIORITY ITEMS:
➡️ CRAWLED / DISCOVERED CURRENTLY NOT INDEXED
Generally, this is content that Google no longer deems to be of value and therefore it is not indexed. Crawled/Discovered are the "same thing" in respect of content perception, it's just the route of URL finding was different.
Things to note:
> Not all URLS reported will be valid (HTTP 200) - always http status check
> Some URLS will be erroneous, malformed or random/parameter driven
> Generally, THIN content / low or non value pages tend to end up here
> Pages that have content where there is no demand can end up here
> Pages that are poorly linked can end up here
Generally - you'll want to clean these URLS up.
> Delete dead content (check for internal and external links)
> Clean up parameters (robots.txt management) subject to parameter checks i.e. you wouldn't block a parameter path that is contributory in other ways
> Filter down to HTTP 200 URLS - this will help you get a much clearer view of what is not indexed but is active
➡️ DUPLICATE WITHOUT USER-SELECTED CANONICAL
Basically, these are URLS Google considers to be duplicate of other URLS where a canonical hasn't been provided to direct Google to the parent URL.
You don't want these, always ensure if there ARE techincal issues or reasons why URLS must exist where they are very similar, specify a canonical parent.
IDEALLY, you shouldn't have a website that facilitates duplicate content, cull / consolidate.
➡️ BLOCKED DUE TO OTHER 4XX ISSUE
High priority, BUT, generally quicker to check, you just need to ensure the URLS Google has tried to access are valid to be blocked (check which 4XX issue you get via httpstatus(.)io
QUICK AND EASY WINS!
➡️ NOT FOUND 404
Crawl site, find internal links, eliminate 404s. Check NOT FOUND 404S in GSC, you may find URLS that are not on the crawl, these may be random or legacy URLS.
Tip! Export the URLS and put them into AHREFS BATCH ANALYSIS to see if any of them have external links (if they do, 301 to preserve link equity)
➡️ SOFT 404
Just double check the pages, generally it's when Google interprets a page that looks like a not found page but returns a HTTP 200 status code.
#SEO
9
38
176
13,456

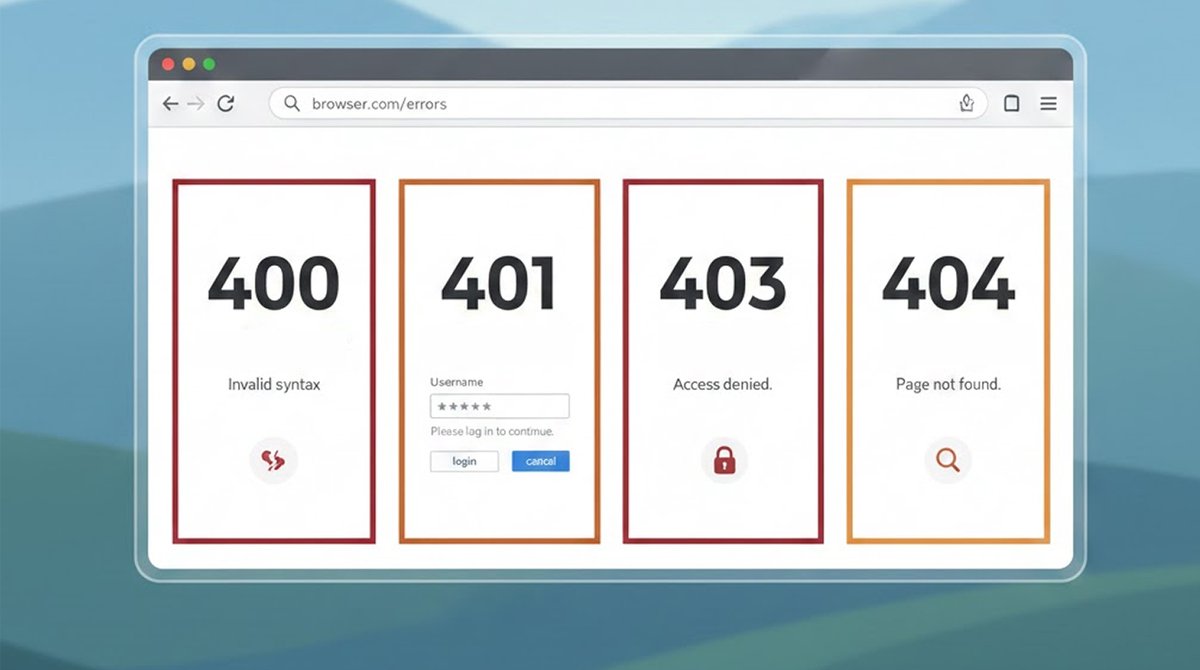
An explanation of 400 Bad Request, 401 Unauthorized, 403 Forbidden, 404 Not Found , what they mean, common causes, real examples, and security/testing implications.
redsecuretech.co.uk/blog/pos…
#HTTPStatus #WebDev #CyberSecurity #APIDebug #TechTips #WebSecurity
1
1
23