
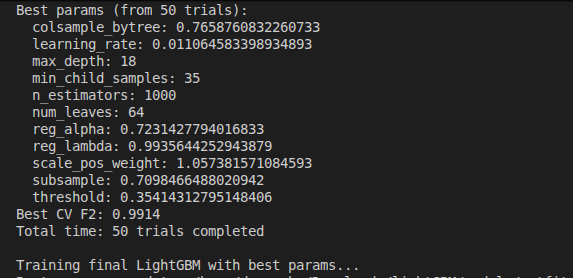
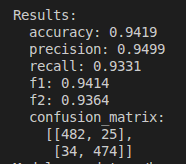
--> Went through the basic of bagging and boosting, classification and regression.
--> covered basics of Logistic Regression, Random Forest, XGboost, LightGBM.
--> Most importantly studied their Hyperparameters.
--> Studied a bit about hyperparameter optimisation by Hyperopt.
9



May 30
In case anyone is wondering, the startup was KindredAI, doesn't exist anymore (bought by Okado), but was doing back then already what all the robotic startups are doing now: record manipulation from Teleop and then learn to do it.
It was cofounded by @jabergT who is the 🐐 that created Theano and HyperOpt and is also a super nice person!
3
34
4,168

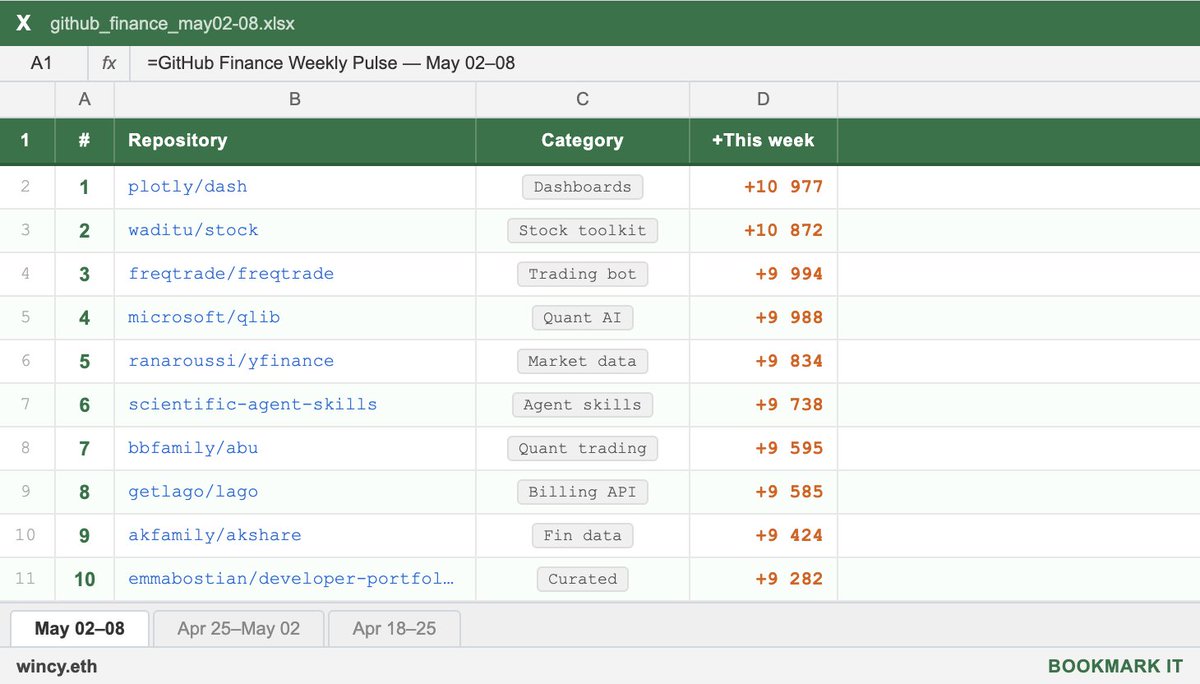
May 8
the fastest growing GitHub repos in finance this week:
1. dash ( 10,977 ★)
data apps and dashboards for Python. no JavaScript required. the go-to framework for building interactive analytics UIs. used everywhere from internal tools to public-facing finance dashboards.
2. stock ( 10,872 ★)
Chinese open-source stock toolkit. fetches market data, calculates indicators, chip distribution, pattern recognition, strategy backtesting, and automated trading. supports both desktop and mobile.
3. freqtrade ( 9,994 ★)
free open-source crypto trading bot. supports Binance, Bybit, and 20 exchanges. strategy backtesting, hyperopt parameter tuning, live and dry-run trading. one of the most mature algo trading projects out there.
4. qlib ( 9,988 ★)
Microsoft's AI-oriented quant investment platform. end-to-end: data - alpha - portfolio - execution. the most serious open-source quant infrastructure out there.
5. yfinance ( 9,834 ★)
the de facto Python library for pulling market data from Yahoo Finance. prices, dividends, options chains, financials. used in virtually every Python finance tutorial and prototype.
6. scientific-agent-skills ( 9,738 ★)
ready-to-use agent skills for research, science, engineering, analysis, and finance. plug into any agent framework. covers bioinformatics, cheminformatics, and now Exa search.
7. abu ( 9,595 ★)
Chinese open-source quant trading system for stocks, options, futures, and Bitcoin. built on Python with machine learning support. one of the older and more comprehensive Chinese quant frameworks.
8. lago ( 9,585 ★)
open-source metering and usage-based billing API. consumption tracking, subscription management, and invoicing. built on ClickHouse. the open alternative to Stripe Billing and Chargebee.
9. akshare ( 9,424 ★)
elegant Python financial data library. covers A-shares, bonds, futures, crypto, and macro data. built for researchers and quants working with Chinese and global markets.
10. developer-portfolios ( 9,282 ★)
curated list of developer portfolio sites for inspiration.
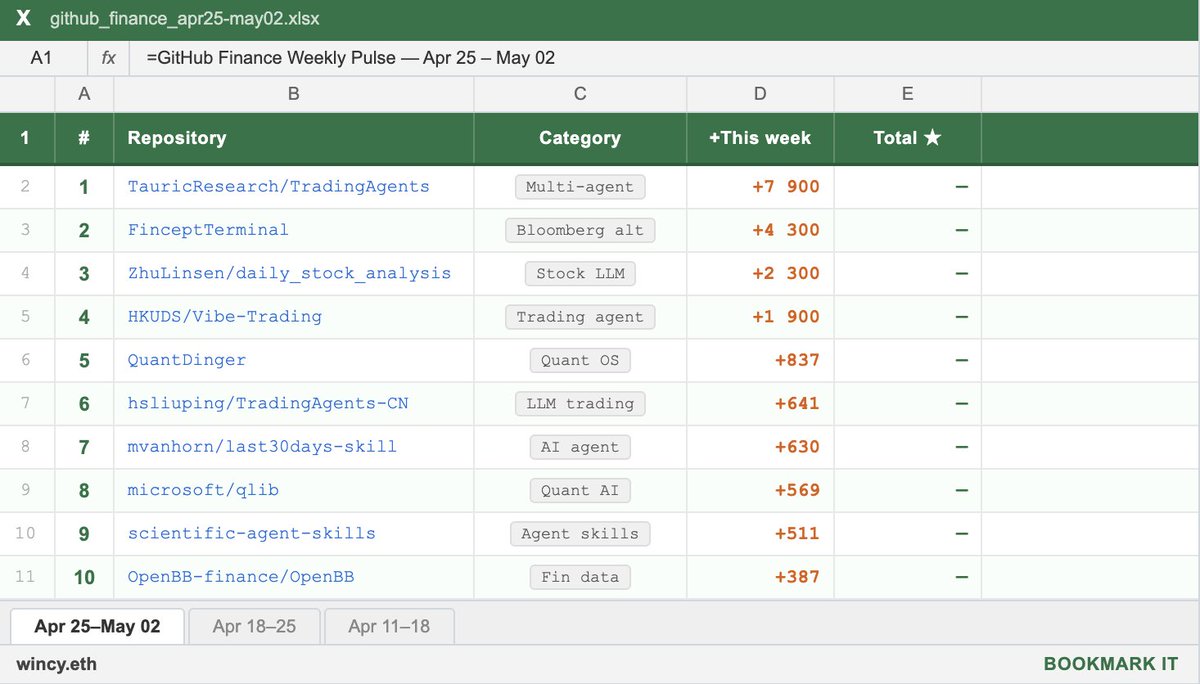
May 2

the fastest growing GitHub repos in finance this week:
1. TradingAgents ( 7.9K ★)
multi-agent LLM trading framework from UCLA/MIT. fundamental analyst, sentiment analyst, technicals, risk manager with DeepSeek V4 thinking-mode support.
2. FinceptTerminal ( 4.3K ★)
open-source Bloomberg alternative built in C 20 Qt6. 37 AI agents in Buffett/Munger/Lynch/Graham style. real-time trading with 16 broker integrations. internal MCP AI quant tabs.
3. daily_stock_analysis ( 2.3K ★)
LLM stock analyzer for US, A-share and H-share markets. auto-builds a daily decision dashboard with entry/exit levels. pushes to WeChat/Telegram/Discord/Email via GitHub Actions.
4. Vibe-Trading ( 1.9K ★)
personal trading agent. natural language - strategy - backtest - export to TradingView/MT5. your own AI trading desk in one pip install.
5. QuantDinger ( 837 ★)
self-hosted AI quant OS. research markets, generate Python strategies, backtest ideas, run live trading. crypto, stocks via IBKR, forex via MT5. one Docker Compose, your infra, your data.
6. TradingAgents-CN ( 641 ★)
Chinese fork of TradingAgents. fully localized for A-share markets, Chinese data sources, and domestic LLMs.
7. last30days-skill ( 630 ★)
AI agent skill that researches any topic across Reddit, X, YouTube, HN, Polymarket and the web in the last 30 days. plug it into any agent.
8. qlib ( 569 ★)
Microsoft's AI-oriented quant investment platform. end-to-end: data - alpha - portfolio - execution. the most serious open-source quant infrastructure out there.
9. scientific-agent-skills ( 511 ★)
ready-to-use agent skills for research, science, engineering, analysis, and finance. plug into any agent framework. covers bioinformatics, cheminformatics, and now Hugging Science.
10. OpenBB ( 387 ★)
open-source financial data platform for analysts, quants, and AI agents. stocks, crypto, options, derivatives, fixed income шт one platform. integrates with AI agents via MCP.
24
45
402
216,763

May 5
Ludwig 0.15 is out 🎉
With improvements fine-tuning, alignment, hyperopt and more.
I also updated he website, bringing it back to it's romer glory: ludwig.ai
Here's what's new (thread 🧵):
1
4
411

lu semua lagi demen kan ai agent yang bisa auto trading crypto 24/7 💻
gua nemu nih Github reponya tinggal lu gabungin sama ai model yg mau lu pake. namanya Freqtrade
udah gua taro linknya di komen
fiturnya apa aja :
> bisa lu atur sesuai strategi trading lu
> auto buy/sell spot & futures di exchange gede
> bisa dry-run mode (test dulu tanpa duit beneran)
> backtesting pake data historis hyperopt buat optimasi
> bisa belajar sendiri & adaptasi otomatis)
> bisa whitelist & blacklist coin
> Kontrol bot, lihat status, profit, stop bot, dll. dari telegram
> exchange yang support (per 2026)
~ spot: Binance, Bybit, OKX, Bitget, Gate io, Kraken, HTX, BingX, Bitmart, Hyperliquid
~ futures: Binance, Bybit, OKX, Bitget, Gate io, Kraken, Hyperliquid
> open source 100% gratis
bisa langsung gas bikin asal lu udah ada strategi sendiri 🧑💻
14
93
520
19,654


Apr 12
these 5 GitHub repos replaced my $2,400/month trading setup
you're spending thousands on software anyone can fork
the repos behind those tools are sitting on GitHub for free
here's what i actually run:
1. fredapi (1K ★)
Bloomberg charges $2,000/mo for macro data
this pulls every Fed dataset into Python with one API key
GDP, CPI, rates, employment - pair it with Claude and you're set
github.com/mortada/fredapi
///
2. ccxt (42K ★)
i was paying $50/mo per exchange just for API access
ccxt connects 107 exchanges through one interface
JS; Python; PHP; Go; C#
the industry standard since day one
github.com/ccxt/ccxt
///
3. freqtrade (47K ★)
killed my $200/mo bot subscription in one afternoon
backtesting, hyperopt, FreqAI, live on 20 exchanges
7 years of weekly commits. Telegram control. your strategies stay yours
github.com/freqtrade/freqtra…
///
4. OpenBB (40K ★)
equities, options, crypto, fixed income, macro - one terminal
plugs into Python, Excel, REST API, MCP for AI agents
my $500/mo data feed couldn't do half of this
github.com/OpenBB-finance/Op…
///
5. goose (40K ★)
by Block (Jack Dorsey). Rust. Apache 2.0
full AI coding agent. any LLM. 3,000 MCP tools. runs locally
the $200/mo i was spending on Claude Code now costs me $0
github.com/block/goose
///
bookmark this and thank me later
24
74
543
54,250

Mar 24
Hyperparameter optimization is a critical process in machine learning that fine-tunes parameters to maximize model performance. These parameters, set before training, control the learning process and directly impact accuracy, efficiency, and scalability.
✔️ It improves model accuracy by identifying optimal parameter settings.
✔️ Reduces overfitting and underfitting, ensuring better generalization to unseen data.
✔️ Enables efficient resource allocation by identifying computationally feasible configurations.
❌ If approached inefficiently, it can be computationally expensive and time-consuming, especially for models with many hyperparameters.
❌ Suboptimal optimization methods might overlook interactions between parameters, leading to less-than-ideal performance.
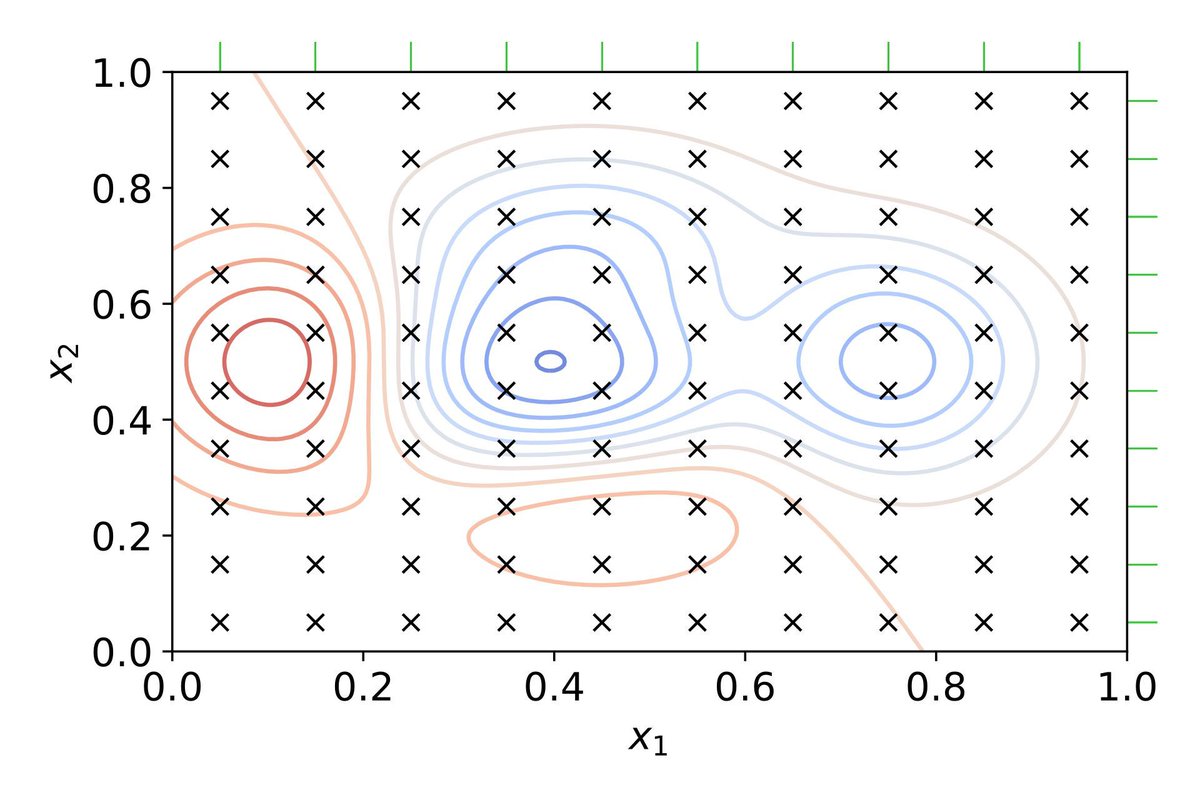
The visualization below demonstrates grid search, a common method for hyperparameter optimization. It evaluates 100 combinations of two parameters, with blue regions indicating better results and red regions showing poor performance. While grid search is systematic, it can become computationally prohibitive in high-dimensional parameter spaces. Image source: en.wikipedia.org/wiki/Hyperp…
🔹 In R, tools like caret and mlr3 support grid and random search, while tune and ParBayesianOptimization enable more advanced approaches like Bayesian optimization.
🔹 In Python, scikit-learn offers grid and random search, while libraries such as optuna, hyperopt, and Ray Tune provide efficient techniques for Bayesian optimization and adaptive resource allocation.
Advanced strategies like random search, Bayesian optimization, and Hyperband are valuable alternatives to grid search, offering faster and often more effective solutions for complex models. Selecting the right method depends on factors like the size of the search space, computational resources, and specific problem requirements. Effective hyperparameter optimization ensures your machine learning models achieve optimal performance without unnecessary computational overhead.
Subscribe to my newsletter for more tips on statistics, data science, R, and Python!
See this link for additional information: statisticsglobe.com/newslett…
#statisticians #RStudio #RStats #DataAnalytics #statisticsclass
5
45
1,750
Mar 23
Random search is a simple yet effective optimization method that selects random samples from the parameter space to find the best configuration. It is widely used in machine learning and data science due to its flexibility and ability to address complex, non-linear problems.
✔️ Easy to implement: Random search avoids complex gradient calculations, making it suitable for a wide range of optimization tasks.
✔️ Efficient in large spaces: Compared to grid search, it focuses on randomly chosen subsets, reducing computational cost while covering diverse regions.
✔️ Handles high-dimensional problems: Scales well to problems with many parameters, making it particularly effective for hyperparameter tuning.
❌ Computational inefficiency in some cases: In very large or highly constrained spaces, random sampling may require extensive iterations to find an optimal solution.
❌ Uninformed exploration: Random sampling does not utilize information from past samples, potentially leading to slower convergence compared to more guided methods.
🔹 Alternatives to consider: Bayesian optimization and genetic algorithms build on previous iterations to guide sampling, often achieving better results with fewer evaluations.
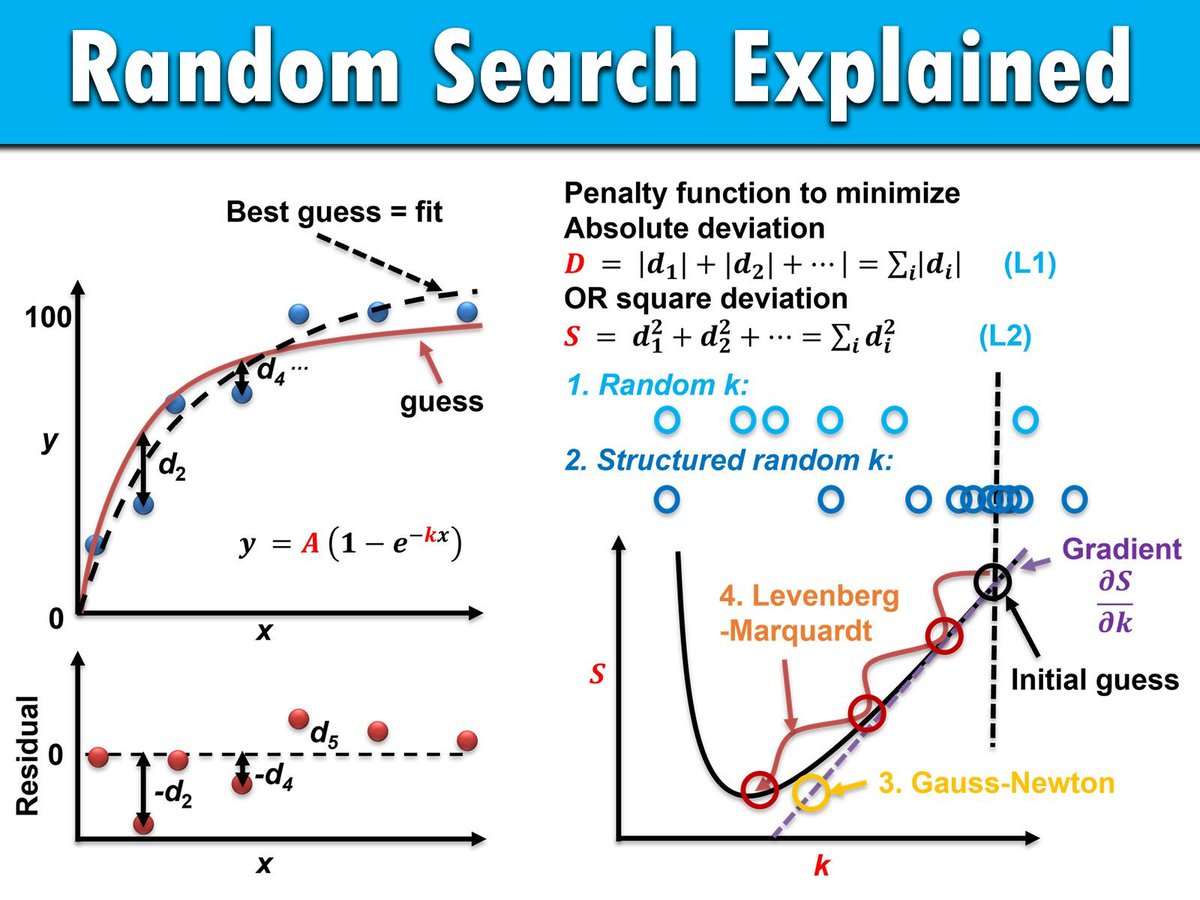
The visualization below illustrates how random search and other methods approach optimization. Methods like random search (1 & 2) do not require gradients, while algorithms such as Gauss-Newton (3) depend on gradients for efficient exploration. This distinction highlights random search’s flexibility but also its limitations in structured spaces. Source: en.wikipedia.org/wiki/Random…
🔹 In Python: Use RandomizedSearchCV in scikit-learn for hyperparameter optimization, or scipy.optimize for general optimization. Advanced libraries like optuna or hyperopt offer more efficient approaches while retaining randomness.
🔹 In R: The caret package supports random search for hyperparameter tuning through trainControl. Alternatively, mlr3 and tidymodels provide robust frameworks for implementing random search strategies.
For more insights and tools to improve your data science skills, join my email newsletter on Statistics, Data Science, R, and Python!
Further details: statisticsglobe.com/newslett…
#programming #Rpackage #database #RStudio #RStats #DataAnalytics
1
7
44
1,482

Mar 18
⚡ Bayesian HPO on a GPU cluster — no Ray Tune script needed.
🔧 Define search spaces in YAML. HyperOpt explores. ASHA prunes. Ray distributes. WarpRec collects results.
💻 Laptop to cluster, same config.
🔗 github.com/sisinflab/warprec
@walteranelli @TommasoDiNoia @abellogin
1
1
2
118

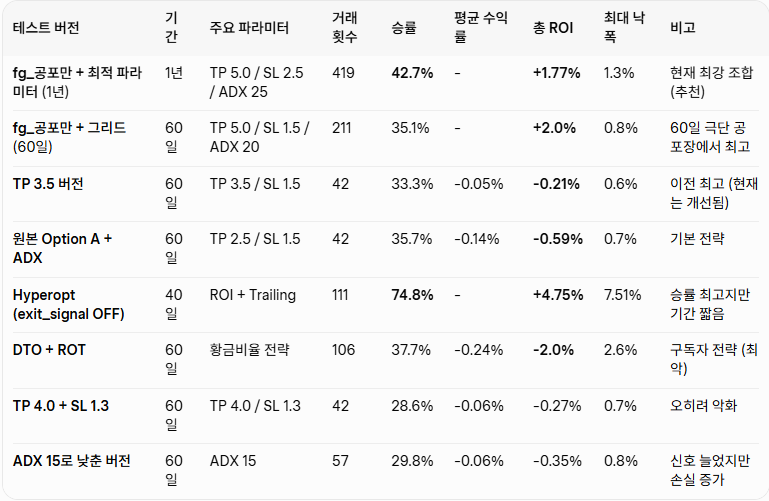
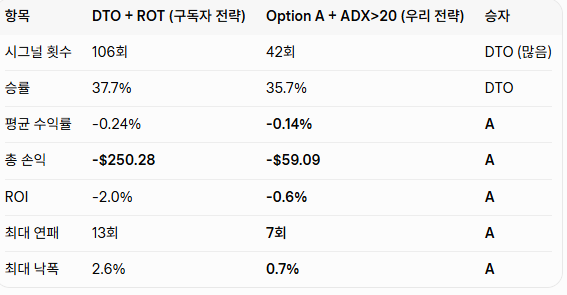
Day 7 🔧 BTC 시그널봇 Build in Public — 승률 33% → 74.8% 하루만에 뒤집음!!
형님들… 진짜 미쳤습니다 🔥
Hyperopt 500회 돌리고 exit_signal 하나 꺼버렸더니
승률 33% → 74.8%
수익 -$927 → $474
Sharpe -17.73 → 3.41
시장 -17% 하락 중에도 4.75% 수익
들어갈 타이밍 3주 고민했는데…
나갈 타이밍이 10배 더 중요하다는 걸 깨달음 ㅋㅋ
자세한 과정, 표, 최적 파라미터, 로그 분석 전부는
구독자 전용 게시물에 올려놓았습니다!
v3.1 Freqtrade 동시 드라이런 시작
1주일 뒤 실전 성적표 공개합니다!
#BuildInPublic #AITrading #Freqtrade #BTC봇

Day 6 🔧 AI 트레이딩 봇 Build in Public — 손익비 실험 중
형들 오늘 하루종일 백테스트만 돌렸어요 ㅋㅋ
1) 횡보장 대응 실험
→ 횡보일 때 다른 전략 쓰면 어떨까? 테스트
→ 결과: 억지로 매매하면 오히려 더 잃음
→ 교훈: 안 하는 것도 전략이다
2) 400개 파라미터 그리드 서치 유전 알고리즘
→ TP/SL 비율, EMA 기간, ADX 등 전부 조합 테스트
→ 승률 34%인데도 수익 나는 구조 137개 발견!
→ 핵심: 이길 때 지는 것의 3.3배를 먹으면 된다
3) 봇 v3.1 업데이트 완료
→ 최적 파라미터 적용해서 지금 돌리고 있습니다
오늘의 교훈:
- 승률보다 손익비(R:R)가 진짜 중요하다
- 복잡하다고 좋은 게 아니다
- 안 하는 것도 전략이다
#BuildInPublic #AITrading #BTC봇
36
17
59
4,352
11 Nov 2025
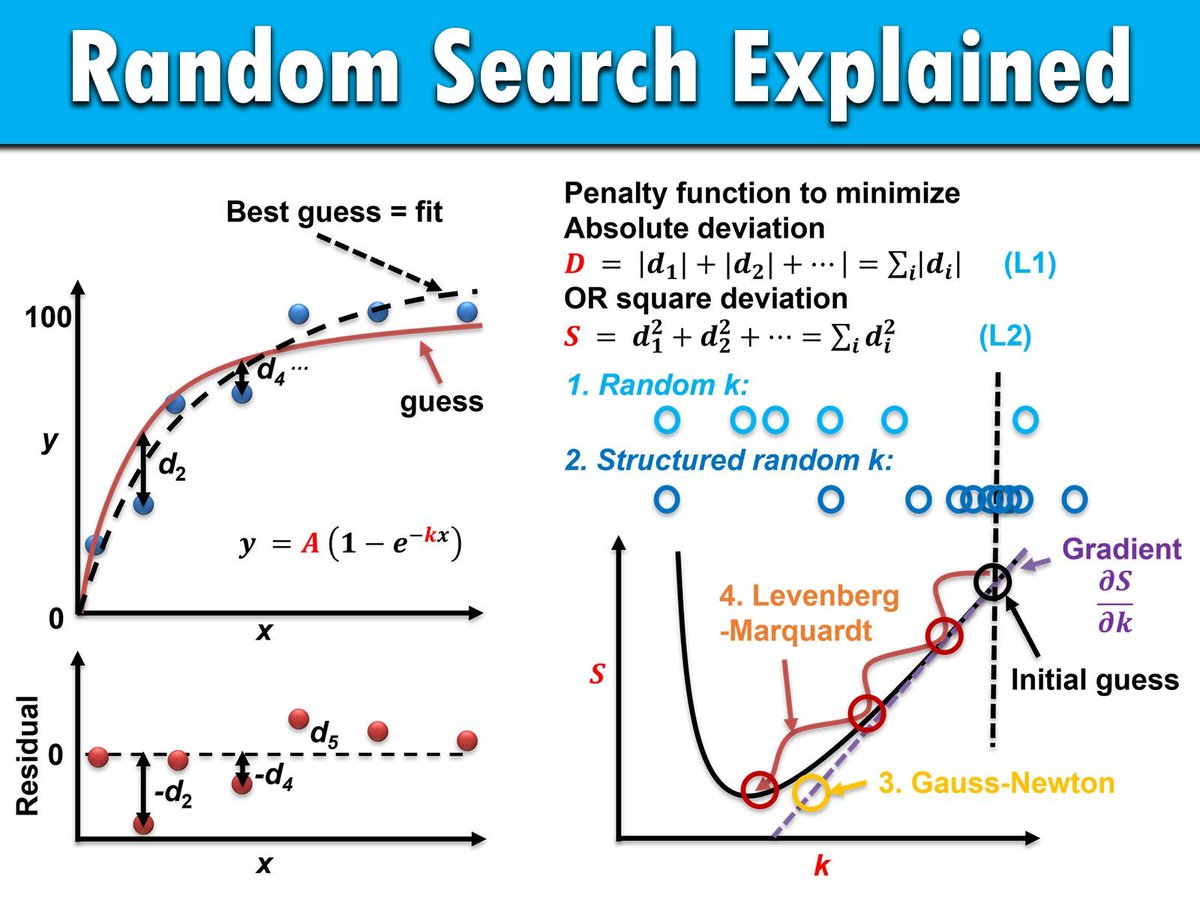
Random search is a simple yet effective optimization method that selects random samples from the parameter space to find the best configuration. It is widely used in machine learning and data science due to its flexibility and ability to address complex, non-linear problems.
✔️ Easy to implement: Random search avoids complex gradient calculations, making it suitable for a wide range of optimization tasks.
✔️ Efficient in large spaces: Compared to grid search, it focuses on randomly chosen subsets, reducing computational cost while covering diverse regions.
✔️ Handles high-dimensional problems: Scales well to problems with many parameters, making it particularly effective for hyperparameter tuning.
❌ Computational inefficiency in some cases: In very large or highly constrained spaces, random sampling may require extensive iterations to find an optimal solution.
❌ Uninformed exploration: Random sampling does not utilize information from past samples, potentially leading to slower convergence compared to more guided methods.
🔹 Alternatives to consider: Bayesian optimization and genetic algorithms build on previous iterations to guide sampling, often achieving better results with fewer evaluations.
The visualization below illustrates how random search and other methods approach optimization. Methods like random search (1 & 2) do not require gradients, while algorithms such as Gauss-Newton (3) depend on gradients for efficient exploration. This distinction highlights random search’s flexibility but also its limitations in structured spaces. Source: en.wikipedia.org/wiki/Random…
🔹 In Python: Use RandomizedSearchCV in scikit-learn for hyperparameter optimization, or scipy.optimize for general optimization. Advanced libraries like optuna or hyperopt offer more efficient approaches while retaining randomness.
🔹 In R: The caret package supports random search for hyperparameter tuning through trainControl. Alternatively, mlr3 and tidymodels provide robust frameworks for implementing random search strategies.
For more insights and tools to improve your data science skills, join my email newsletter on Statistics, Data Science, R, and Python! More information: eepurl.com/gH6myT
#R4DS #RStats #Python #DataAnalytics #datastructure
2
14
96
4,524
9 Nov 2025
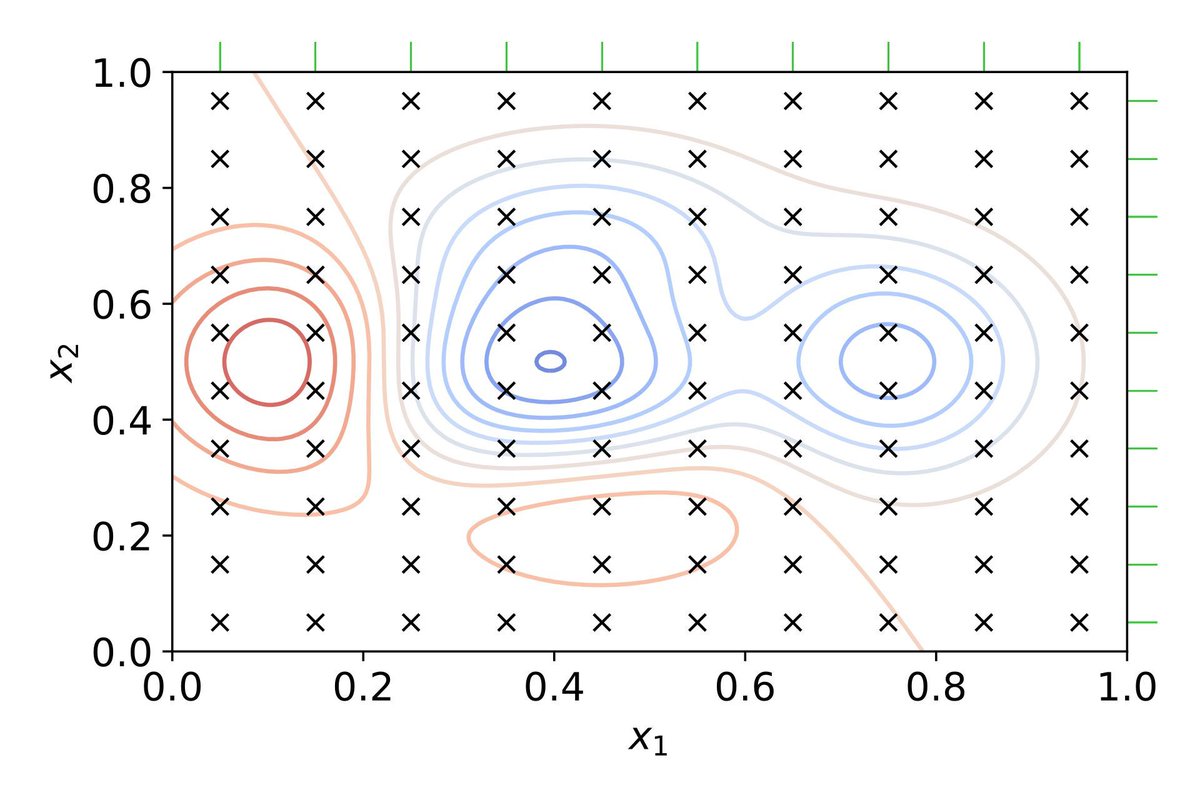
Hyperparameter optimization is a critical process in machine learning that fine-tunes parameters to maximize model performance. These parameters, set before training, control the learning process and directly impact accuracy, efficiency, and scalability.
✔️ It improves model accuracy by identifying optimal parameter settings.
✔️ Reduces overfitting and underfitting, ensuring better generalization to unseen data.
✔️ Enables efficient resource allocation by identifying computationally feasible configurations.
❌ If approached inefficiently, it can be computationally expensive and time-consuming, especially for models with many hyperparameters.
❌ Suboptimal optimization methods might overlook interactions between parameters, leading to less-than-ideal performance.
The visualization below demonstrates grid search, a common method for hyperparameter optimization. It evaluates 100 combinations of two parameters, with blue regions indicating better results and red regions showing poor performance. While grid search is systematic, it can become computationally prohibitive in high-dimensional parameter spaces. Image source: en.wikipedia.org/wiki/Hyperp…
🔹 In R, tools like caret and mlr3 support grid and random search, while tune and ParBayesianOptimization enable more advanced approaches like Bayesian optimization.
🔹 In Python, scikit-learn offers grid and random search, while libraries such as optuna, hyperopt, and Ray Tune provide efficient techniques for Bayesian optimization and adaptive resource allocation.
Advanced strategies like random search, Bayesian optimization, and Hyperband are valuable alternatives to grid search, offering faster and often more effective solutions for complex models. Selecting the right method depends on factors like the size of the search space, computational resources, and specific problem requirements. Effective hyperparameter optimization ensures your machine learning models achieve optimal performance without unnecessary computational overhead.
Subscribe to my newsletter for more tips on statistics, data science, R, and Python!
For more information, visit this link: eepurl.com/gH6myT
#pythonprogramming #statisticsclass #datastructure #DataAnalytics #rstudioglobal #Python #statisticians #RStats
2
29
164
9,781

8 Nov 2025
Finally done with the Supervised and Unsupervised thing..
Will start DL after lunch,
Try to finish up the following topics..by EOD
> Forward, Backward propagation
> Math intuition for them!
> Activation functions..( ReLU, Sigmoid, Tanh, Softmax )
I skipped Hyperopt in ML btw!

7
239

21 Sep 2025
Day 20 of ML 🤖
- Completed chapter on Hyperparameter Optimization
- Studied about Grid search, random search, how to optimize hyperparameters in pipelines, Bayesian optimization with gaussian process, and the Hyperopt library, which uses Tree-structured Parzen Estimator (TPE)
20 Sep 2025

Day 19 of ML 🤖
- Completed chapter on Feature Selection
- Studied different methods like Recursive Feature Elimination, Feature Importance, SelectFromModel function in scikit-learn & L1 penalization
- Will start chapter on Hyperparameter tuning tomorrow
- Check code in comments
2
3
20
963

12 Sep 2025
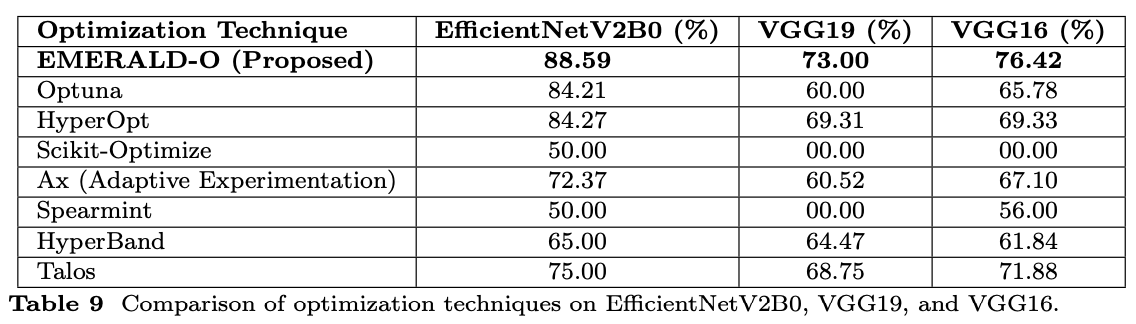
📊 Datasets & Models:
🔹 Main backbone → EfficientNetV2B0
🔹 Generalization on → VGG16 & VGG19
🔹 Compared against → HyperOpt, Optuna, Talos, HyperBand, Spearmint, Scikit-Optimize, Ax
📑 See Table 9 for tool comparison
👉
1
4
80

11 Sep 2025
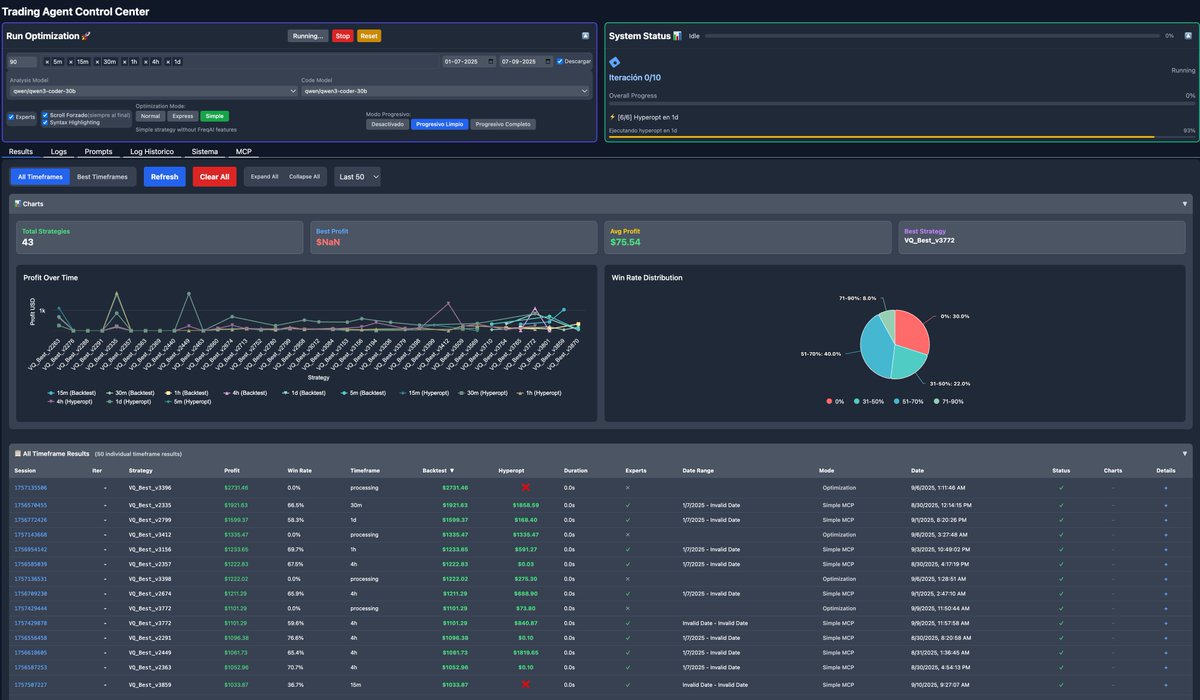
I am developing a system that uses YouTube video transcripts to generate strategy source code and perform backtesting and hyperopt with Freqtrade, using Qwen3-Coder. I'm currently working on generating FreqAI code
1
5
367