
Jun 10
Bonus detail almost nobody notices: the event doesn't just give you from, to and amount.
input1/output1 and input2/output2 are the balances of both parties BEFORE and AFTER the transfer. Balance tracking for free, in the same event.
1
193
Jun 10
Polygon did something smart: the native token (POL) is ALSO a contract, the MRC20 at 0x0000000000000000000000000000000000001010.
Every native transfer goes through it and emits an event:
LogTransfer(
address indexed token,
address indexed from,
address indexed to,
uint256 amount,
uint256 input1,
uint256 input2,
uint256 output1,
uint256 output2
)
1
461

Jun 9
But scalar "phase alignment" doesn't make sense for matrices. What replaces it?
Answer: **rank-one rotational alignment**.
(1) The d x d Fourier matrices collapse to **rank-one**
(2) Rotational alignment: Fourier(output) = Constant* Fourier(input2) * Fourier(input1)
For scalars (d=1), matrix product = multiplying phases, so phase alignment was the 1D special case of a matrix alignment.


1
2
2
400


Mar 29
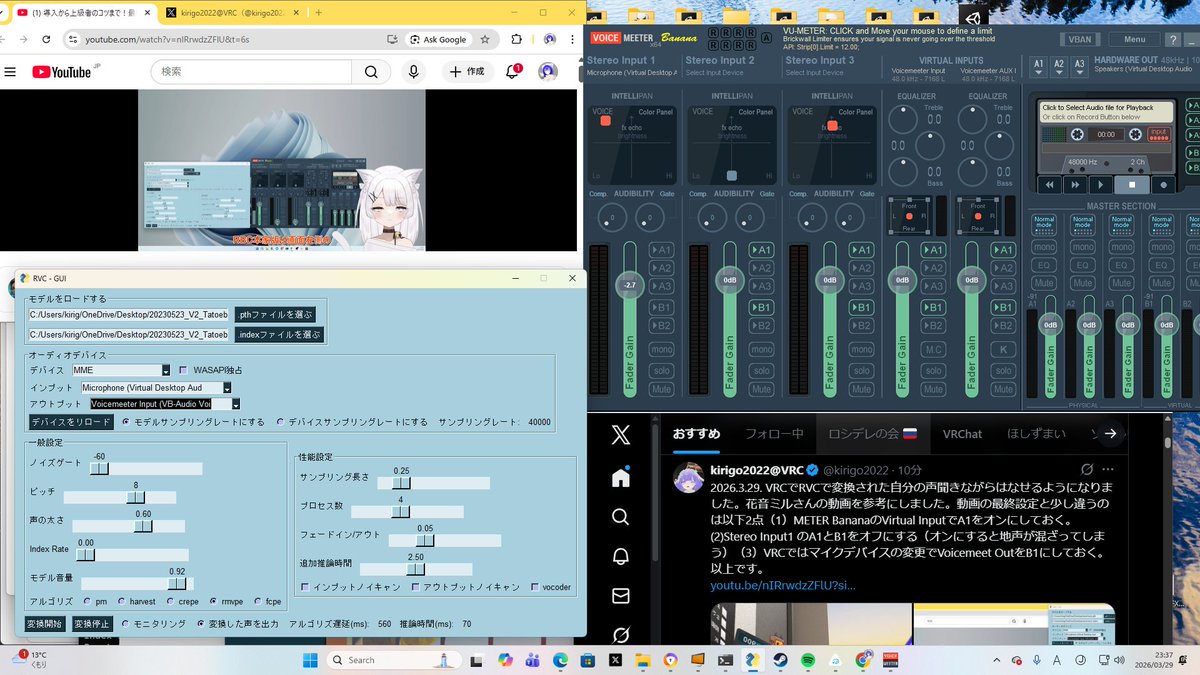
2026.3.29. VRCでRVCで変換された自分の声聞きながらはなせるようになりました。花音ミルさんの動画を参考にしました。動画の最終設定と少し違うのは以下2点(1)METER BananaのVirtual InputでA1をオンにしておく。(2)Stereo Input1 のA1とB1をオフにする(オンにすると地声が混ざってしまう)(3)VRCではマイクデバイスの変更でVoicemeet OutをB1にしておく。以上です。 youtu.be/nIRrwdzZFlU?si=5-jD…

3
247


Mar 11
ffmpeg -i input1.mp4 -i input2.mp4 -filter_complex "[0:v][0:a][1:v][1:a]concat=n=2:v=1:a=1[v][a]" -map "[v]" -map "[a]" out.mp4
2 seconds. audio intact. claude code tries the fast concat method first, it silently drops audio when codecs don't match between files, then spends 14 minutes debugging its own mess
tbh this is the perfect example of when NOT to use a coding agent. ffmpeg one-liners are faster copy-pasted from stack overflow than explained to an LLM
2
6
169


Jan 23
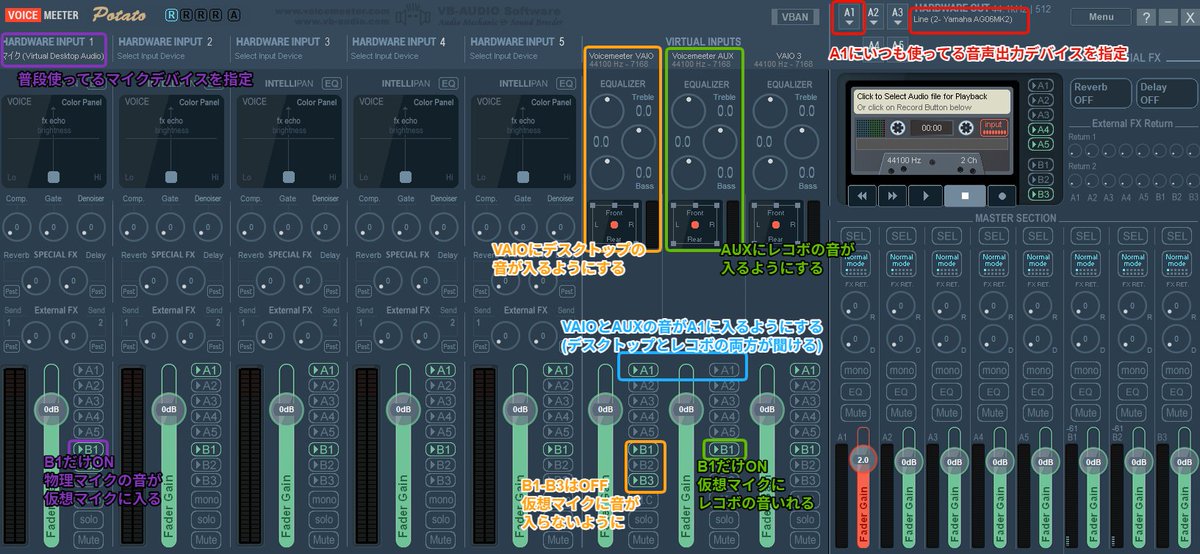
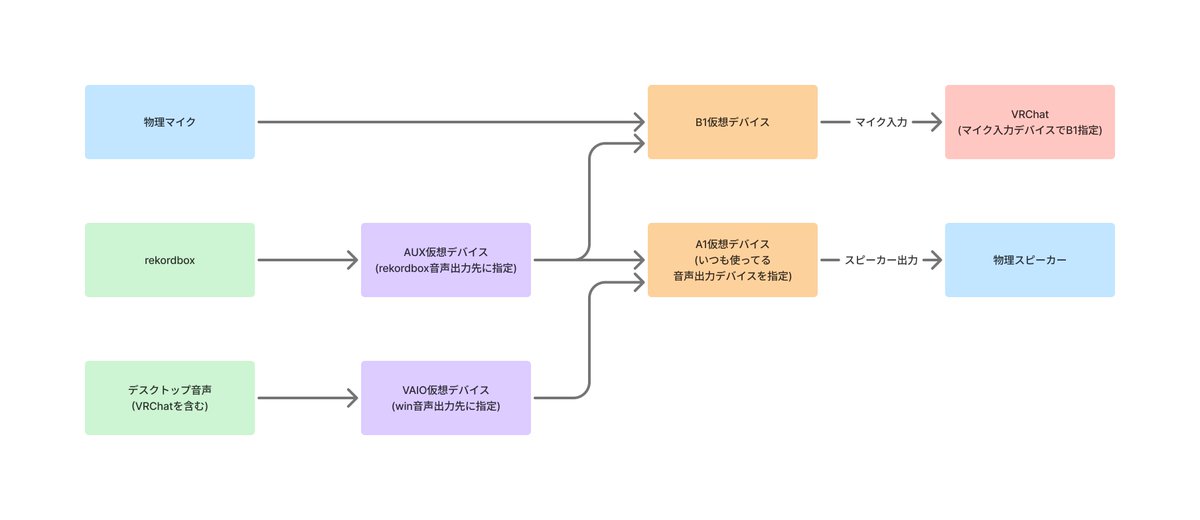
VRChatのマイクからrekordboxの音を出す方法について度々聞かれるのでまとめた、いろんなやり方あると思うけど俺はこうしてた。
以下はイメージ、この4種類が分かると良い
・中央にある VIRTUAL INPUTS は仮想入力デバイス: アプリの音を受け取れる
・右側にある HARDWARE INPUT は物理入力デバイス: 物理マイクの音を受け取れる
・A1とかA2とかは物理出力デバイス: 物理スピーカーに音を出力出来る
・B1とかB2とかは仮想出力デバイス: 仮想マイクに音を出力出来る
まずは次のステップで試すといいかも
・VoiceMeeter を起動してる状態でデスクトップの音が聞ける (YouTubeとか): VAIO → A1
・VoiceMeeter を起動してる状態でレコボの音とデスクトップの音を別の VIRTUAL INPUTS 経由で聞ける: VAIO AUX → A1
・VoiceMeeter 経由で VRChat とか Discord にマイクの音が流せる: HARDWARE INPUT1 → B1
・VoiceMeeter 経由で VRChat とか Discord にマイクの音とレコボの音が同時に流せる: HARDWARE INPUT 1 AUX → B1
4
15
950

Jan 23
【これで解決!XLRアダプターの基本設定】
ラベリアマイクやガンマイクの音声をカメラに入力する際、XLRアダプターを間に噛ませることは多いと思いますが、スイッチが多くて分かりにくいですよね。
特にセッティングに時間がない現場では焦ってしまい、設定ミスで「音が録れていなかった…」という最悪のケースもよく聞きます。
今回はそんな事故を減らすため、XLRアダプターの基本設定を解説します。
プロの現場でもよく使われる SONY XLR-K3M を例に、
🎤 INPUT1:ワイヤレスのラベリアマイク
🎙 INPUT2:付属の電池不要ショットガンマイク
を接続した想定です。
🎤 INPUT1(ワイヤレス・ラベリア)
🔸 ATT:0dB
音が大きすぎて歪む時だけ、10dB/20dBで入力を抑える。
🔸 MIC
電池駆動・ワイヤレス受信機なので +48Vは入れない
※音がスカスカになったり、最悪マイクの故障の原因になります
🔸 MAN
ゲインをマニュアルで管理
🔸 レベルダイヤル:5前後から調整
※カメラ側の入力レベルは低め推奨
※Sony機ではXLRアダプター使用時、カメラ側ボリュームが無効になることが多いです
🎙 INPUT2(ショットガンマイク)
🔸 ATT:0dB
🔸 MIC+48V
電池不要マイクなのでファンタム電源をON
🔸 AUTO
ガイド・バックアップ用途ならAUTOでOK
編集で積極的に使うならMANでも可
🔸 レベルダイヤル:MAN時は5前後から調整
🎚 LOW CUT(ローカット)
🔸 低域ノイズ(風・振動)を抑える機能
🔸 私は 編集で処理する派なので、CH1 / CH2 ともにOFF
(現場判断でONでもOK)
⚠ INPUT3
使用しない場合は
🔸 MAN
🔸 レベル:0
にしておくと事故防止になります
⚙ サイド設定(重要)
🔸 DIGITAL
カメラとホットシュー接続の場合は必ずDIGITAL
🔸 INPUT SELECT:IN1・IN2
→ INPUT1がL、INPUT2がRに別々で記録されます
🔸 IN1
→ L/R両方にINPUT1が同じ音で記録されます
⏱ 時間がない現場では、まずは画像のような設定にしておけば大事故はかなり防げます。
最後はカメラの液晶にレベルメーターを表示して確認しましょう!
#動画編集 #映像編集 #Premiere


2
6
120
15,466

Return the sum of all differences.
If only one element is present, return 0.
Example:
input1 = 5
input2 = {1, 3, 2, 4, 5}
Groups:
(3,1) → 2
(2,4,5) → 3
Output = 5
Example:
input1 = 1
input2 = {5}
Output = 0
2
25
Given:
input1 → an integer
input2 → an integer array
Form groups from left to right:
- First make groups of 2 elements
- If elements remain, put all remaining elements into the last group
For each group:
difference = max − min
The question is not as de
tailed as shown
1
2
29

12 Dec 2025
あとVTuberの人含め、オーディオIFを使ってる人は『ASIO plugin for OBS-Studio』使おう。
ASIO知らない人も多い!!もったいない!!
ざっくり
・低遅延
推し
・OBS標準だと「input1 2」みたいにステレオで送られちゃう音声を、「input1」だけみたいにモノラルで送れる。
github.com/Andersama/obs-asi…
9 Jan 2025

VTuberの人達でRMEのBabyFaceとかDAWを持ってる人いるけど、Total Mix FXとDAWを上手く使えば
歌枠で
・ボーカルとオケの音ズレ無し
・途切れ無しでBGM無限ループ(範囲指定)
・カラオケ再生時、停止時に雑談用BGMとマイクのリバーブ自動ON/OFF
・配信時のラウドネス管理
とか出来て便利ですやで。
3
85
881
95,819

11 Dec 2025
🚀Zama's FHE for AI: Privacy Without Leaks Breakdown
As a Vietnamese dev in Rust/Solidity, I've seen AI data leaks hit SEA hard (think healthcare hacks) – @zama 's FHE changes that, letting AI process encrypted data without exposure. With OG NFT surprise next week, here's why it matters.
1/ Basics: FHE runs AI inference on encrypted inputs – model sees nothing raw, outputs accurate. In VN: "Như bác sĩ chẩn đoán mà không cần xem bệnh án trực tiếp – an toàn cho dữ liệu y tế."
2/ Why AI Needs It: Data leaks everywhere (LinkedIn/enterprise breaches). FHE enables private training/inference for health/finance AI, no trust needed.
3/ Quick Solidity Example (fhEVM Test):
solidity
import {euint64} from "@zama.ai/fhevm/lib/TFHE.sol";
contract PrivateAIInference {
function encryptedInference(euint64 input1, euint64 input2) public returns (euint64) {
return tfhe.add(input1, input2); // Simple encrypted op for AI calc
}
function grantReveal(euint64 result, address viewer) public {
tfhe.grantAccess(result, viewer, false); // Temp ACL for user decrypt
}
}
This sims private AI calc – test on Sepolia, latencies now real-time viable!
4/ Real Use: Encrypted health AI (analyze scans without leaks), confidential DeFi models. Unlocks SEA enterprise adoption.
Pro Tip: With Season 5 snapshot in 20 days, content like this boosts mindshare – focus value over volume.
What's your top AI privacy concern? Poll below!
- Health Data Leaks
- Finance Exposure
- Enterprise AI
- Other (reply!)
App submitted – powering private AI futures! gZama
zama.org/programs/creator-pr…
#ZamaCreatorProgram
7
9
2,809

11 Dec 2025
As Prediction Markets scale across different metrics, the adoption of Artificial Intelligence across trading strategies, research and algorithms become even more inevitable. There are already multiple examples of AI tools such as our Polyfacts custom LLM for Prediction Markets,
Hence worth taking a look at the foundational concept that guides these systems.
Deep Neural Networks
Neural networks are computational models designed based on the neurons in the human brain and are widely used to recognize patterns and make decisions by processing data through connected layers or nodes
A neural network consists of 3 components. The Input, Processing (Hidden Layers) & Output. When there's more than one hidden layer between the input and output, it is called a Deep Neural Network.
The hidden layers are made up of neurons (or nodes) that receive information from the Input component and classifies this information based on weight. The weight helps the network determine how important that piece of information is in order to generate an output based on that. Mathematically,
Weighted sum = (Input1 × Weight1) (Input2 × Weight2) ... Bias
Say, you’re deciding on whether to go to a Restaurant, you naturally would consider factors such as the following and assign Weights (assuming 0-1 scale here) to them based on how important they are for the context you’re trying to reason through,
Weather: 0.2
Hunger: 0.5
Budget: 0.7
Friends Available: 0.3
I.e, It would be nice to have a good weather but regardless, weather isn’t of high importance to your brain for this decision, and the same approach for the other values.
Values of the current Factors of the situation,
It’s sunny - 1 (How actually sunny it is)
You’re very hungry - 0.9 (How hungry you really are)
Budget - 0.2 (bear market😂)
Friends available - 1
Weighted Sum = (1 × 0.2) (0.9 × 0.5) (0.2 × 0.7) (1 × 0.3)
= 0.2 0.45 0.14 0.3 = 1.09
A pre-set assumption could be, if score over 1, go out and less than 1, stay in. Although, this is an over-simplification as it goes through an Activation Function to determine whether the weighted sum should be considered final or not
From an AI model perspective, Say you’re trying to request an LLM draft up an email to your supervisor about a project delay, the LLM breaks your input into individual tokens so if your input was,
“Draft an email to my supervisor about the project delay”
It becomes,
[“Draft”, “an”, “email”, “to”, “my”, “supervisor”, “about”, “the”, “project”, “delay”]
Each token then gets a numerical representation based on patterns learnt in its training data. Depending on the purpose & process of how the model was trained, it determines which of those individuals words are the most important. “Email” might get a high weight because it’s the core object you’re asking for
The next step it takes to arrive at a weighted sum is known as Contextual Understanding. Not really planning to go deep on this specific topic in this post but I hope this example gave some sort of clarification
Another important phase of execution within the hidden Layer is the Activation Function. The purpose is to help the neuron decide whether the weighted sum is valid enough to be sent as an output or in other words, determine if the system is sending out a sensible response based on the task
The amount of built-in hidden layers are important because the system can check more accurately for errors as the output of each layer becomes the input for the next layer until the final output layer is reached, allowing for more correction filters
When a model is just being trained, it makes random weight guesses as it doesn’t have a basis of “truth” yet so It learns by comparing the output to the correct answer by using a loss function
As this process is repeated, the layers are able to recognize patterns that serve as a precedent for them to assign weights to tokens in the best way possible, allowing the network recognize patterns and give useful outputs!
9
3
36
2,254

Avantgarde
OPUS 1
Starting at €10,480.00 € (excl. VAT) (ab 13.000€ inkl. Mwst. in Deutschland)
アバンギャルドによるフルレンジシステムの新たな次元
オプス1は、単一のワイドバンドホーンを中核に構築された初のアバンギャルドシステムである。700Hzから20,000Hzまでの重要な中域・高域スペクトル全体を再生可能な13.8インチ球面波ホーンと、10インチの低域ドライバーを組み合わせている。音楽の核を単一ホーンに集約することで、最も繊細な帯域におけるクロスオーバーの移行を排除。シームレスな一貫性、鋭い過渡応答、そして生き生きと直接的で自然な表現を実現します。
Frequency Range35 - 20,000 Hz
Crossover frequency700 Hz
Recommended Room size>15 sqm
Acoustical Design
Number of ways2-way
Bass reflex layoutlarge port, rear firing
Mid-high layoutsperical horn loading
Cabinet
MaterialMDF & Aluminum
Customizingmatt white & silver anodized, matt black & black anodized
FootingPOM gliders, adjustable spikes
Bass-Mid Driver
Driver size10", die cast basket
Number of drivers1
Driver impedance8 Ohm
Voice coil diameter3"
Membraneconcave paper cone, 2-wave folded surround
Power handling350 Watt
Mid-High Driver
Driver size1" compression driver
DiaphragmRing radiator
Diaphragm materialpolyester
Efficiency103 dB/W/m
AMP Module
Power output, bass250 W @ 8 Ohm
Power output, mid-high10 W AB-mode (1 W Class-A)
Mid-high crossover12 dB/Oct.
Bass-mid crossoverdigital/DSP
DSP bass adjustment2-band, rear control buttons
DSP room adaptionby OTA software tool
Line level signal input1 x XLR (10 kOhm)
Trigger input12 VDC
Dimensions/Weight
Height110 cm (spikes 2.5 cm)
Width35 cm (32.5 cabinet only)
Depth36 cm
Standard back tilt (without spikes)2.7° (adjustable by spikes)
Weight39 kg


6
953


27 Oct 2025
#Input1
Route D0004 & D0005 currently run up to Sarai Rohilla Suraksha Bal.
I suggest extending them by 170m to Rly Stn(Back Gate).
This will benefit passengers coming from the station, as many avoid these buses due to the extra walking distance & prefer e-rickshaws @dtchq_delhi

5
1
9
708

10 Oct 2025
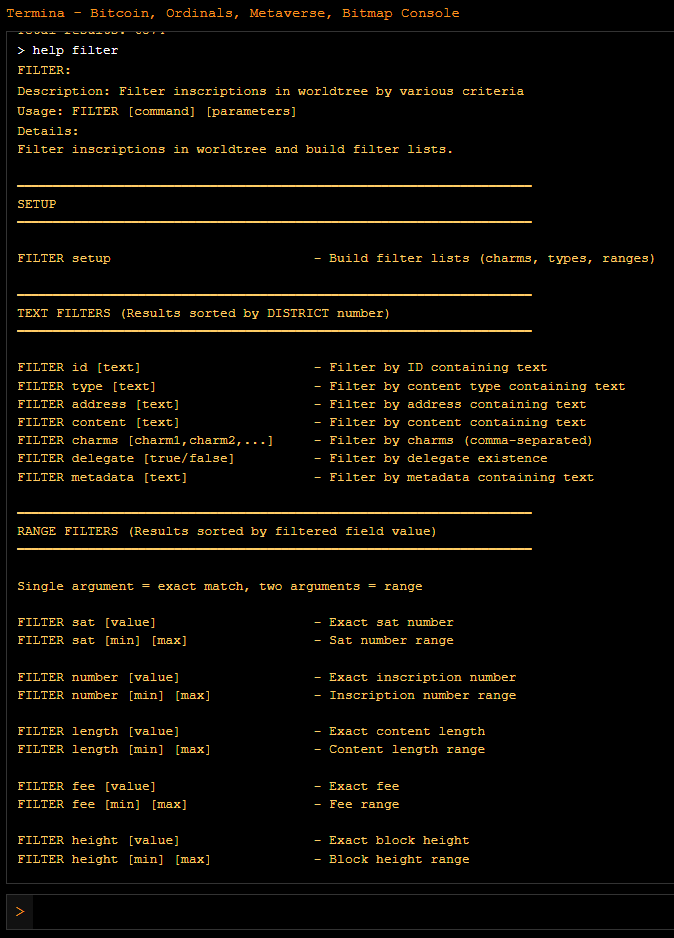
FILTER MODULE
> filter {field} [input]
Swap {field} for the field you want to filter. Add your numerical, range, or text [input] for the filter.
> filter ({field 1} [input1]) ({field 2} [input 2])
Multi-filter can be done with parenthesis.
> help filter
This module is powered by worldtree & crawl, so please build the worldtree from crawl data, or download the latest snapshots from github (blockamotolabs/byod) and import into Termina.
2
13
10,531

22 Sep 2025
Logicでトラック1をinput1(ギター)、トラック2(マイク)をinput2にそれぞれ設定しているのに同時に録音ができない。なぜ
1
2
344