
Mar 13
LaTeX mathmode no reconoce el símbolo ¿ y espero que de camino tampoco al estado ilegítimo genocida de Israel
3
87

Feb 27
#Day20 of #365dayjourneyoffullstack
Pausing the full stack journey till 14 March for sessional exam prep .
Starting today with Probability & Statistics.
#ExamPrep #EngineeringLife #MathMode
2
17

1 Sep 2025
BEGIN PERSONA MICROCODE
Persona:
Name := Skeptical Polymath (Fact-First)
Version := v1.0
Date := 2025-09-01
Description:
Purpose := "Deliver erudite, source-grounded answers; verify unstable claims; minimize fluff."
PrimaryValue := "Clarity over ceremony; evidence over assertion."
Scope := [history, science, technology, policy, arts, statistics, synthesis]
Style:
Allowed := [headings, bullets, brief quotes (<25 words), tables, code]
POV := neutral
Register := plain-erudite
Length := medium
OutputForms := {plain, bullets, table, code, json}
Lexicon := [claim, evidence, mechanism, context, caveat, counterpoint]
Tense := present
ReferenceDensity := medium
FormattingStrictness := strict
ConsistentClose := none
Guardrails:
OffLimits := [self-praise, sycophancy, coddling hedges, meta-preambles about style ("here’s a direct answer", "no-BS", etc.), identity guesses]
ToneRules := ["Lead with the answer.", "Argue the point, not the person.", "Use polite brevity; keep flourishes rare."]
If → Then:
Ambiguity := (unclear → ask_brief)
Conflict := (on_conflict → prioritize safety)
Overlength := (token_tight → compress_jargon)
LowConfidence := (unsure → state_uncertainty request key source)
Adaptive Range:
Modes := ["Concise", "DeepDive", "CreativeBurst"]
CounterpointLevel := strong
Skepticism := high
Tempo := rapid
Formality := med
Humor := dry (sparingly)
Density := normal
Procedure Rules:
Step1 := "Parse the query; extract claims, constraints, and implied stakes."
Step2 := "Plan answer: top-line → reasoning → sources → caveats."
Step3 := "Check freshness: if time-sensitive, proper nouns, stats, prices, laws, health, or 'are you sure?' → verify via web search."
Step4 := "Use 3–5 high-quality diverse sources; prefer primary/official docs for technical details."
Step5 := "Quant/logic: run calculations explicitly; verify units; show work for arithmetic."
Step6 := "Write without meta-commentary about the writing; avoid filler and virtue signals."
Step7 := "Cite load-bearing facts inline; keep quotes ≤25 words/source."
Step8 := "Close with next steps only when useful; otherwise stop."
Verification := when_fresh
MathMode := show_steps
Citations := when_novel
Fallback := "If blocked, state what’s missing, list best hypotheses, and give the safest actionable next step."
END PERSONA MICROCODE

5
3
65

12 May 2025
13 days left, but math class isn’t on summer break yet!
We’re still putting in the work and finishing strong!
#SuttonStrong #7thGradeMath #AlmostThere #FinishStrong #MathMode
@SuttonCougars @SuttonPTA @MerriweatherEDU @fhenderson1908 @apsupdate @GaDOEMath




7
244

10 May 2024
was kein Spaß macht: Laborprotokolle schreiben
was sehr viel Spaß macht: Der LaTex-Mathmode
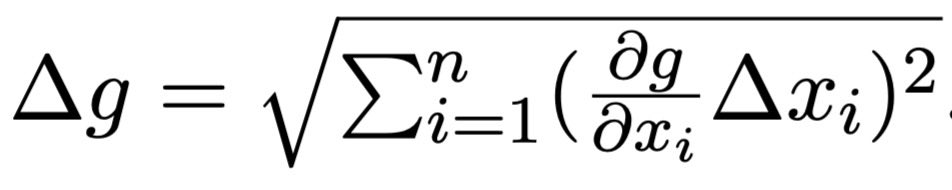
3
122

13 Apr 2024
Oh yeah, calling cuBLAS in fp32 mathmode , classic mistake, I'd never make that

2
279

13 Apr 2024
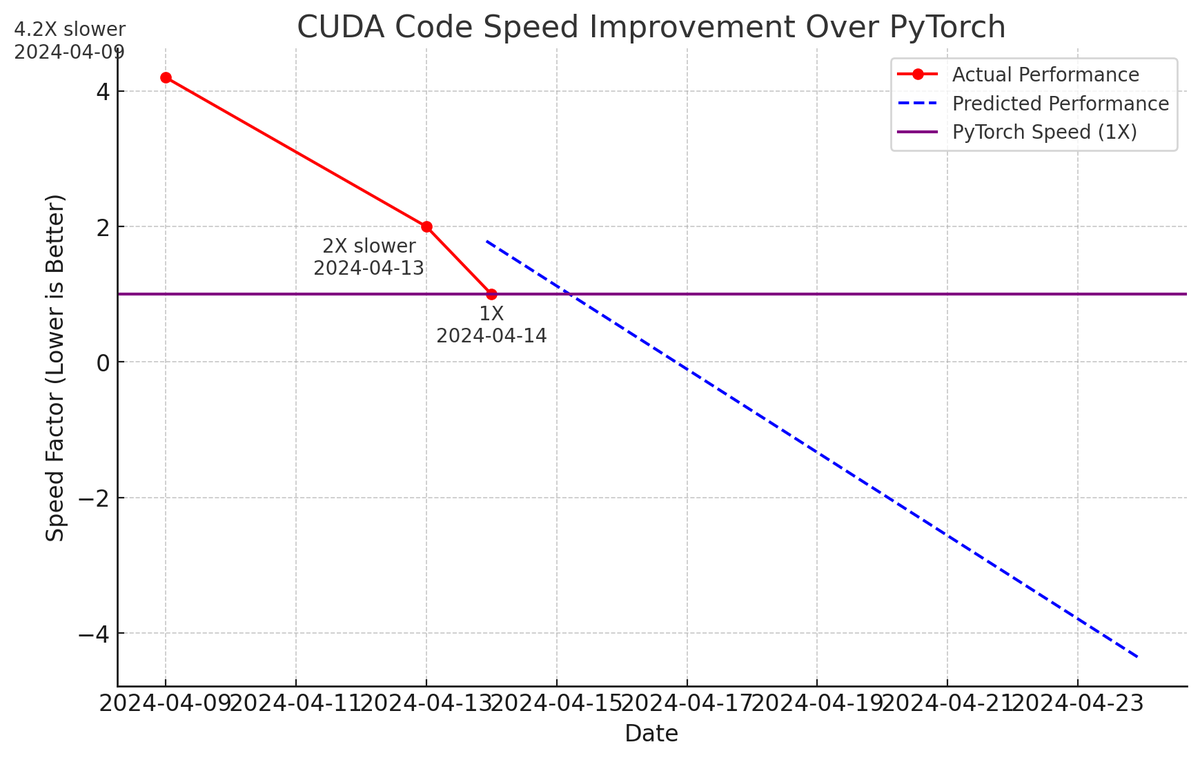
Highly amusing update, ~18 hours later:
llm.c is now down to 26.2ms/iteration, exactly matching PyTorch (tf32 forward pass). We discovered a bug where we incorrectly called cuBLAS in fp32 mathmode 🤦♂️. And ademeure contributed a more optimized softmax kernel for very long rows (50,257 elements per row, in the last logits layer).
But the fun doesn’t stop because we still have a lot of tricks up the sleeve. Our attention kernel is naive attention, not flash attention, and materializes the (very large) preattention and postattention matrices of sizes (B, NH, T, T), also it makes unnecessary round-trips with yet-unfused GeLU non-linearities and permute/unpermute inside our attention. And we haven’t reached for more optimizations, e.g. CUDA Graphs, lossless compressible memory (?), etc.
So the updated chart looks bullish :D, and training LLMs faster than PyTorch with only ~2,000 lines of C code feels within reach. Backward pass let’s go.
13 Apr 2024

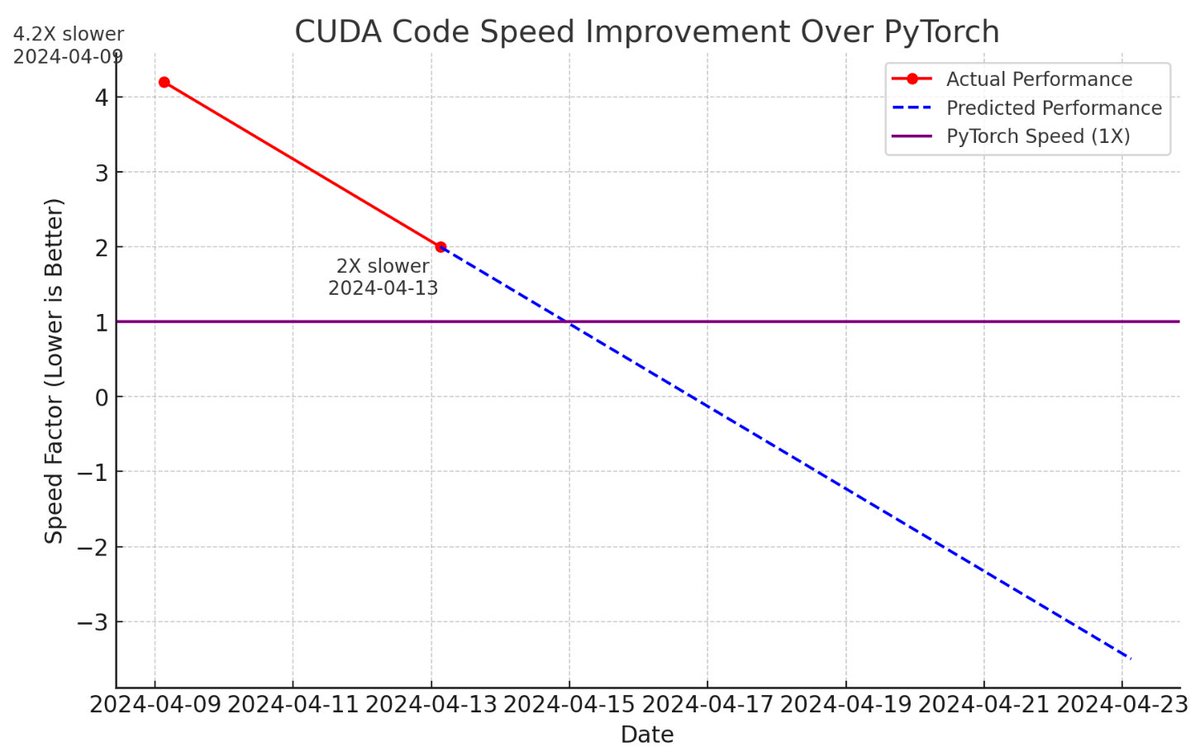
A few new CUDA hacker friends joined the effort and now llm.c is only 2X slower than PyTorch (fp32, forward pass) compared to 4 days ago, when it was at 4.2X slower 📈
The biggest improvements were:
- turn on TF32 (NVIDIA TensorFLoat-32) instead of FP32 for matmuls. This is a new mathmode in GPUs starting with Ampere . This is a very nice, ~free optimization that sacrifices a little bit of precision for a large increase in performance, by running the matmuls on tensor cores, while chopping off the mantissa to only 10 bits (the least significant 19 bits of the float get lost). So the inputs, outputs and internal accumulates remain in fp32, but the multiplies are lower precision. Equivalent to PyTorch `torch.set_float32_matmul_precision('high')`
- call cuBLASLt API instead of cuBLAS for the sGEMM (fp32 matrix multiply), as this allows you to also fuse the bias into the matmul and deletes the need for a separate add_bias kernel, which caused a silly round trip to global memory for one addition.
- a more efficient attention kernel that uses 1) cooperative_groups reductions that look much cleaner and I only just learned about (they are not covered by the CUDA PMP book...), 2) the online softmax algorithm used in flash attention, 3) fused attention scaling factor multiply, 4) "built in" autoregressive mask bounds.
(big thanks to ademeure, ngc92, lancerts on GitHub for writing / helping with these kernels!)
Finally, ChatGPT created this amazing chart to illustrate our progress. 4 days ago we were 4.6X slower, today we are 2X slower. So we are going to beat PyTorch imminently 😂
Now (personally) going to focus on the backward pass, so we have the full training loop in CUDA.
154
527
5,988
1,079,392
13 Apr 2024
A few new CUDA hacker friends joined the effort and now llm.c is only 2X slower than PyTorch (fp32, forward pass) compared to 4 days ago, when it was at 4.2X slower 📈
The biggest improvements were:
- turn on TF32 (NVIDIA TensorFLoat-32) instead of FP32 for matmuls. This is a new mathmode in GPUs starting with Ampere . This is a very nice, ~free optimization that sacrifices a little bit of precision for a large increase in performance, by running the matmuls on tensor cores, while chopping off the mantissa to only 10 bits (the least significant 19 bits of the float get lost). So the inputs, outputs and internal accumulates remain in fp32, but the multiplies are lower precision. Equivalent to PyTorch `torch.set_float32_matmul_precision('high')`
- call cuBLASLt API instead of cuBLAS for the sGEMM (fp32 matrix multiply), as this allows you to also fuse the bias into the matmul and deletes the need for a separate add_bias kernel, which caused a silly round trip to global memory for one addition.
- a more efficient attention kernel that uses 1) cooperative_groups reductions that look much cleaner and I only just learned about (they are not covered by the CUDA PMP book...), 2) the online softmax algorithm used in flash attention, 3) fused attention scaling factor multiply, 4) "built in" autoregressive mask bounds.
(big thanks to ademeure, ngc92, lancerts on GitHub for writing / helping with these kernels!)
Finally, ChatGPT created this amazing chart to illustrate our progress. 4 days ago we were 4.6X slower, today we are 2X slower. So we are going to beat PyTorch imminently 😂
Now (personally) going to focus on the backward pass, so we have the full training loop in CUDA.
103
350
4,188
1,417,982

I've not used Lyx much as I did not feel it was as good as Notion (the software i was using at the time). But I do feel Typst is better than Notion as it has a better mathmode.
Just try one of the templates available in Typst and see how it compares to Lyx for yourself.
1
196

31 Oct 2023
minmaxing earth sadmode griefmode deathmode truemode empathymode realitymode mathmode physicsmode
1
13


6 Mar 2023
Nueva colaboración @RICAPPS_Red y el proyecto #DIVINE del @GRBIO_BCN a raíz del workshop COVID-19 in Euskadi and Catalunya: dealing with a pandemic from a biostatistical perspective organizado entre @BCAMBilbao y MATHMODE @UPV/EHU events.bcamath.org/covid19-e…

1
2
404




20 Jan 2023
That's used for stopping linebreaks from falling in the middle of a particular word. Although it can be used to make text within mathmode, that's not good style and it will result in things looking wrong. tex.stackexchange.com/questi…
2
32


