
28 Aug 2025
Copy/paste this to your LLM. 🌿. Will be the shortcut emoji. If you use it enough it will persist even though it’s not supposed to.
{
"token_type": "Method",
"token_name": "Cursor/Claude Project Spec Token",
"token_id": "cursor-claude-spec-v1",
"version": "1.0.0",
"shortcut": "🌿",
"portability_check": true,
"description": "Provides a comprehensive, no-code technical specification framework for transforming project descriptions into implementation-ready design documents. Structured for Cursor, Claude Code, or similar AI coding assistants.",
"goals": [
"Ensure project specifications are unambiguous, modular, and self-contained.",
"Provide a cursor-ready task list that AI coding assistants can execute independently.",
"Guide end-to-end system design without requiring human guesswork."
],
"output_structure": {
"1. Project Overview & Description": {
"summary": "2–3 sentence project description",
"objectives": "Primary goals and success metrics",
"target_users": "Who will use the system and how",
"value_propositions": "What problems this solves"
},
"2. Problem Definition & Requirements": {
"functional": "System must-do actions",
"non_functional": "Performance, security, scalability",
"constraints": "Budget, timeline, limitations",
"success_criteria": "Measurable outcomes"
},
"3. Cursor Task List": {
"format": "Step-by-step checklist, actionable",
"requirements": "Clear, unambiguous, no guesswork"
},
"4. Technical Architecture": {
"system_architecture": "High-level component diagram",
"data_flow": "How information moves",
"api_design": "Endpoints, request/response formats",
"database_schema": "Tables, relationships, indexes",
"file_structure": "Directory and key files"
},
"5. LLM Integration Strategy": {
"model_selection": "Rationale for chosen models",
"prompt_engineering": "Template structures",
"retrieval_strategy": "Vector DB, chunking, search",
"context_management": "Conversation state handling",
"grounding_mechanisms": "Fact-checking and attribution"
},
"6. Data & Storage Implementation": {
"sources": "Origin of data",
"architecture": "Databases, file systems, caches",
"vector_db_setup": "Embeddings, indexing, querying",
"privacy_security": "Data protection measures",
"backup_recovery": "Persistence strategies"
},
"7. External Integrations": {
"required_apis": "List authentication methods",
"sdk_requirements": "Libraries versions",
"service_dependencies": "Fallback plans",
"rate_limiting": "API constraint handling"
},
"8. Risk Mitigation & Monitoring": {
"failure_modes": "Contingency plans",
"hallucination_prevention": "Accuracy safeguards",
"monitoring": "Metrics, alerts, logging",
"quality_assurance": "Testing & validation"
}
},
"design_principles": [
"Prioritize grounded, reliable outputs.",
"Be transparent about limitations and trade-offs.",
"Keep designs simple but scalable.",
"Ensure privacy and security in all data flows.",
"Prefer retrieval and chaining over fine-tuning unless ROI is clear.",
"Use deterministic workflows with clear routing.",
"Integrate external APIs when they reduce complexity or improve delivery."
],
"guardian_hooks": {
"checks": [
"portability_check",
"schema_validation",
"contradiction_scan"
]
}
}
2
94

1 Feb 2025
#Highcited #highviewed #callforreading
📝 #Perceptron: Learning, Generalization, #Model_Selection, Fault Tolerance, and Role in the #Deep_Learning Era
🔍 Article Views 11181; Citations 27
📌 brnw.ch/21wQoKI
@MDPIOpenAccess @ComSciMath_Mdpi

1
4
148

1 Jul 2024
Bはクラスでも変数でも関数でもなんでも良い
あとモジュールをまとめたものをパッケージって言って、sklearnで
from sklearn.model_selection import train_test_split
よく使うけど、sklearnパッケージの中からmodel_selectionモジュール(.py)の中のtrain_test_split関数を指定してるってこと?

1
6
1,494

11 Mar 2024
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, LSTM, GRU, Multiply, Add, Concatenate, Reshape, Flatten, TimeDistributed, Conv2D, MaxPooling2D, UpSampling2D, Dropout, BatchNormalization, LayerNormalization, AlphaDropout, GaussianNoise, DepthwiseConv2D, SeparableConv2D, GlobalAveragePooling2D, MultiHeadAttention
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import MeanSquaredError, SparseCategoricalCrossentropy
from tensorflow.keras.metrics import Mean, SparseCategoricalAccuracy
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
from tensorflow.keras.regularizers import l1, l2, l1_l2
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split, KFold
from sklearn.utils import shuffle
from kerastuner import HyperParameters, BayesianOptimization, Objective
from skopt import gp_minimize
from skopt.space import Real, Integer
from skopt.utils import use_named_args
import cv2
import os
import logging
import threading
import multiprocessing
import json
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import custom_object_scope
from tensorflow.keras.models import model_from_json
# Set up logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# Define the input and output formats
input_shape = (None, 224, 224, 3) # Variable-length sequence of 224x224 RGB images
output_shape = (None, 10) # Variable-length sequence of 10-dimensional action vectors
# Define the hyperparameter search space
def build_model(hp):
# Define the number and size of layers
attention_units = hp.Int('attention_units', min_value=32, max_value=256, step=32)
working_memory_units = hp.Int('working_memory_units', min_value=64, max_value=512, step=64)
cognitive_control_units = hp.Int('cognitive_control_units', min_value=32, max_value=128, step=32)
goal_representation_units = [hp.Int(f'goal_units_{i}', min_value=8, max_value=128, step=8) for i in range(3)]
decision_making_units = hp.Int('decision_making_units', min_value=16, max_value=64, step=16)
# Define the regularization parameters
l1_reg = hp.Float('l1_reg', min_value=1e-5, max_value=1e-2, sampling='log')
l2_reg = hp.Float('l2_reg', min_value=1e-5, max_value=1e-2, sampling='log')
dropout_rate = hp.Float('dropout_rate', min_value=0.1, max_value=0.5, step=0.1)
# Define the attention mechanism
def attention_layer(inputs, control_signals):
# Multi-head attention mechanism
attention = MultiHeadAttention(num_heads=8, key_dim=attention_units)(inputs, inputs)
attention = LayerNormalization()(attention)
attention = Dropout(dropout_rate)(attention)
# Gating mechanism
gating = Multiply()([attention, control_signals])
return gating
# Define the working memory module
def working_memory_layer(inputs, units):
# LSTM layer with residual connections
lstm = LSTM(units, return_sequences=True, kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
lstm = LayerNormalization()(lstm)
lstm = Dropout(dropout_rate)(lstm)
# Residual connection
residual = Add()([inputs, lstm])
return residual
# Define the cognitive control module
def cognitive_control_layer(inputs, units):
# Dense layers with layer normalization and dropout
dense1 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
dense1 = LayerNormalization()(dense1)
dense1 = Dropout(dropout_rate)(dense1)
dense2 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense1)
dense2 = LayerNormalization()(dense2)
dense2 = Dropout(dropout_rate)(dense2)
control_signals = Dense(attention_units, activation='sigmoid', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense2)
return control_signals
# Define the goal representation module
def goal_representation_layer(inputs, units):
goal_layers = []
for u in units:
# Dense layers with layer normalization and dropout
dense = Dense(u, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
dense = LayerNormalization()(dense)
dense = Dropout(dropout_rate)(dense)
goal_layers.append(dense)
inputs = dense
return goal_layers
# Define the decision-making module
def decision_making_layer(inputs, units):
# Dense layers with layer normalization and dropout
dense1 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(inputs)
dense1 = LayerNormalization()(dense1)
dense1 = Dropout(dropout_rate)(dense1)
dense2 = Dense(units, activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense1)
dense2 = LayerNormalization()(dense2)
dense2 = Dropout(dropout_rate)(dense2)
action_probs = Dense(output_shape[-1], activation='softmax', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg))(dense2)
return action_probs
# Define the neural network architecture
def create_model():
# Input layer
inputs = Input(shape=input_shape)
# Attention layer
attention = TimeDistributed(DepthwiseConv2D(kernel_size=3, padding='same', activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg)))(inputs)
attention = TimeDistributed(BatchNormalization())(attention)
attention = TimeDistributed(SeparableConv2D(attention_units, kernel_size=3, padding='same', activation='relu', kernel_regularizer=l1_l2(l1=l1_reg, l2=l2_reg)))(attention)
attention = TimeDistributed(BatchNormalization())(attention)
attention = TimeDistributed(MaxPooling2D(pool_size=2))(attention)
attention = TimeDistributed(Flatten())(attention)
attention = TimeDistributed(GaussianNoise(0.1))(attention)
# Working memory layer
working_memory = working_memory_layer(attention, working_memory_units)
# Cognitive control layer
cognitive_control = cognitive_control_layer(working_memory, cognitive_control_units)
# Attention modulation
attended_input = attention_layer(attention, cognitive_control)
# Goal representation layer
goal_representation = goal_representation_layer(attended_input, goal_representation_units)
# Decision-making layer
concatenated = Concatenate()(goal_representation [attended_input])
action_probs = decision_making_layer(concatenated, decision_making_units)
# Output layer
outputs = Reshape(output_shape)(action_probs)
# Create the model
model = Model(inputs=inputs, outputs=outputs)
return model
# Create the model
model = create_model()
return model
# Define the data loading and augmentation functions
def load_data(data_dir):
# Load the data from the directory
data = []
labels = []
for label_dir in os.listdir(data_dir):
label_path = os.path.join(data_dir, label_dir)
if os.path.isdir(label_path):
for img_file in os.listdir(label_path):
img_path = os.path.join(label_path, img_file)
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
data.append(img)
labels.append(int(label_dir))
data = np.array(data)
labels = np.array(labels)
return data, labels
def preprocess_data(data):
# Normalize pixel values
data = data.astype('float32') / 255.0
return data
def augment_data(data):
# Create an instance of ImageDataGenerator for data augmentation
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
# Fit the data generator
datagen.fit(data)
return datagen
# Define the callbacks
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
model_checkpoint = ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=5, min_lr=1e-6)
tensorboard_callback = TensorBoard(log_dir='./logs', histogram_freq=1)
# Define the hyperparameter tuning
def objective(params):
# Create the model with the given hyperparameters
model = build_model(HyperParameters(params))
# Compile the model
optimizer = Adam(learning_rate=params['learning_rate'])
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(train_data, train_labels, epochs=50, batch_size=params['batch_size'], validation_data=(val_data, val_labels), callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the model on the validation set
_, val_acc = model.evaluate(val_data, val_labels)
return 1 - val_acc # Minimize the validation loss
param_space = {
'attention_units': Integer(32, 256),
'working_memory_units': Integer(64, 512),
'cognitive_control_units': Integer(32, 128),
'goal_units_0': Integer(8, 128),
'goal_units_1': Integer(8, 128),
'goal_units_2': Integer(8, 128),
'decision_making_units': Integer(16, 64),
'l1_reg': Real(1e-5, 1e-2, 'log-uniform'),
'l2_reg': Real(1e-5, 1e-2, 'log-uniform'),
'dropout_rate': Real(0.1, 0.5),
'learning_rate': Real(1e-4, 1e-2, 'log-uniform'),
'batch_size': Integer(16, 128)
}
# Load and preprocess the data
train_data, train_labels = load_data('path/to/train/data')
val_data, val_labels = load_data('path/to/val/data')
test_data, test_labels = load_data('path/to/test/data')
train_data = preprocess_data(train_data)
val_data = preprocess_data(val_data)
test_data = preprocess_data(test_data)
# Perform data augmentation
train_datagen = augment_data(train_data)
val_datagen = augment_data(val_data)
test_datagen = augment_data(test_data)
# Perform hyperparameter tuning
result = gp_minimize(objective, param_space, n_calls=50, random_state=42)
# Get the best hyperparameters
best_params = {
'attention_units': result.x[0],
'working_memory_units': result.x[1],
'cognitive_control_units': result.x[2],
'goal_units_0': result.x[3],
'goal_units_1': result.x[4],
'goal_units_2': result.x[5],
'decision_making_units': result.x[6],
'l1_reg': result.x[7],
'l2_reg': result.x[8],
'dropout_rate': result.x[9],
'learning_rate': result.x[10],
'batch_size': result.x[11]
}
# Create the best model with the tuned hyperparameters
best_model = build_model(HyperParameters(best_params))
# Compile the best model
optimizer = Adam(learning_rate=best_params['learning_rate'])
best_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the best model
best_model.fit(train_datagen.flow(train_data, train_labels, batch_size=best_params['batch_size']),
steps_per_epoch=len(train_data) // best_params['batch_size'],
epochs=100,
validation_data=val_datagen.flow(val_data, val_labels, batch_size=best_params['batch_size']),
validation_steps=len(val_data) // best_params['batch_size'],
callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the best model on the test set
test_loss, test_acc = best_model.evaluate(test_datagen.flow(test_data, test_labels, batch_size=best_params['batch_size']), steps=len(test_data) // best_params['batch_size'])
logger.info(f'Test loss: {test_loss:.4f}, Test accuracy: {test_acc:.4f}')
# Save the best model
best_model.save('best_model.h5')
# Convert the best model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(best_model)
tflite_model = converter.convert()
with open('best_model.tflite', 'wb') as f:
f.write(tflite_model)
# Save the best model architecture as JSON
model_json = best_model.to_json()
with open('best_model_architecture.json', 'w') as json_file:
json_file.write(model_json)
# Save the best model weights
best_model.save_weights('best_model_weights.h5')
# Load the saved model
with custom_object_scope({'MultiHeadAttention': MultiHeadAttention, 'LayerNormalization': LayerNormalization}):
loaded_model = load_model('best_model.h5')
# Load the saved model architecture and weights
with open('best_model_architecture.json', 'r') as json_file:
loaded_model_json = json_file.read()
loaded_model = model_from_json(loaded_model_json, custom_objects={'MultiHeadAttention': MultiHeadAttention, 'LayerNormalization': LayerNormalization})
loaded_model.load_weights('best_model_weights.h5')
# Use the loaded model for inference
new_data = preprocess_data(new_data)
predictions = loaded_model.predict(new_data)
# Implement continuous learning and adaptation
def continuous_learning(model, data, labels):
# Update the model with new data
model.fit(data, labels, epochs=10, batch_size=32)
# Save the updated model
model.save('updated_model.h5')
# Monitor and detect distribution shifts
def detect_distribution_shift(data, threshold=0.1):
# Compare the distribution of new data with the training data
train_mean = np.mean(train_data)
train_std = np.std(train_data)
new_mean = np.mean(data)
new_std = np.std(data)
# Calculate the difference in means and standard deviations
mean_diff = abs(train_mean - new_mean)
std_diff = abs(train_std - new_std)
# Check if the difference exceeds the threshold
if mean_diff > threshold or std_diff > threshold:
logger.warning('Distribution shift detected!')
return True
else:
return False
# Implement monitoring and logging
def monitor_performance(model, data, labels):
# Evaluate the model on the new data
loss, acc = model.evaluate(data, labels)
# Log the performance metrics
logger.info(f'Monitoring - Loss: {loss:.4f}, Accuracy: {acc:.4f}')
# Check for performance degradation
if acc < 0.8:
logger.warning('Performance degradation detected!')
# Example usage of continuous learning and monitoring
new_data, new_labels = load_data('path/to/new/data')
new_data = preprocess_data(new_data)
if detect_distribution_shift(new_data):
continuous_learning(loaded_model, new_data, new_labels)
monitor_performance(loaded_model, new_data, new_labels)
# Set up real-time monitoring and alerts
def real_time_monitoring(model, data, labels, interval=60):
while True:
# Evaluate the model on the new data
loss, acc = model.evaluate(data, labels)
# Log the performance metrics
logger.info(f'Real-time Monitoring - Loss: {loss:.4f}, Accuracy: {acc:.4f}')
# Check for anomalies or performance degradation
if acc < 0.7:
logger.critical('Critical performance degradation detected!')
# Send alert notification
send_alert_notification('Performance Degradation Alert', f'Model accuracy dropped to {acc:.4f}')
# Wait for the specified interval before the next evaluation
time.sleep(interval)
# Function to send alert notifications
def send_alert_notification(subject, message):
# Implement your preferred method of sending notifications (e.g., email, SMS, slack)
# Example using email notification
from_email = 'your_email@example.com'
to_email = 'alert_recipient@example.com'
msg = MIMEMultipart()
msg['From'] = from_email
msg['To'] = to_email
msg['Subject'] = subject
msg.attach(MIMEText(message, 'plain'))
server = smtplib.SMTP('smtp.example.com', 587)
server.starttls()
server.login(from_email, 'your_email_password')
server.send_message(msg)
server.quit()
# Start real-time monitoring in a separate thread
monitoring_thread = threading.Thread(target=real_time_monitoring, args=(loaded_model, new_data, new_labels))
monitoring_thread.start()
# Implement parallel processing for data loading and preprocessing
def load_and_preprocess_data(data_dir):
# Load the data from the directory
data = []
labels = []
for label_dir in os.listdir(data_dir):
label_path = os.path.join(data_dir, label_dir)
if os.path.isdir(label_path):
# Use parallel processing to load and preprocess images
with multiprocessing.Pool() as pool:
img_paths = [os.path.join(label_path, img_file) for img_file in os.listdir(label_path)]
preprocessed_imgs = pool.map(preprocess_image, img_paths)
data.extend(preprocessed_imgs)
labels.extend([int(label_dir)] * len(preprocessed_imgs))
data = np.array(data)
labels = np.array(labels)
return data, labels
def preprocess_image(img_path):
img = cv2.imread(img_path)
img = cv2.resize(img, (224, 224))
img = img.astype('float32') / 255.0
return img
# Load and preprocess data using parallel processing
train_data, train_labels = load_and_preprocess_data('path/to/train/data')
val_data, val_labels = load_and_preprocess_data('path/to/val/data')
test_data, test_labels = load_and_preprocess_data('path/to/test/data')
# Perform incremental learning
def incremental_learning(model, data, labels, batch_size=32):
# Shuffle the data
data, labels = shuffle(data, labels)
# Perform incremental learning in batches
for i in range(0, len(data), batch_size):
batch_data = data[i:i batch_size]
batch_labels = labels[i:i batch_size]
# Fine-tune the model on the batch
model.fit(batch_data, batch_labels, epochs=1, batch_size=batch_size)
# Save the updated model
model.save('incremental_model.h5')
# Example usage of incremental learning
incremental_learning(loaded_model, new_data, new_labels)
# Perform model pruning
def prune_model(model, pruning_factor=0.2):
# Create a pruning model
pruning_model = tf.keras.models.clone_model(model)
# Perform pruning
pruning_params = {}
for layer in pruning_model.layers:
if isinstance(layer, tf.keras.layers.Dense):
pruning_params[layer.name] = {'pruning_factor': pruning_factor}
pruned_model = tfmot.sparsity.keras.prune_low_magnitude(pruning_model, **pruning_params)
# Compile the pruned model
pruned_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return pruned_model
# Example usage of model pruning
pruned_model = prune_model(loaded_model)
# Fine-tune the pruned model
pruned_model.fit(train_datagen.flow(train_data, train_labels, batch_size=best_params['batch_size']),
steps_per_epoch=len(train_data) // best_params['batch_size'],
epochs=50,
validation_data=val_datagen.flow(val_data, val_labels, batch_size=best_params['batch_size']),
validation_steps=len(val_data) // best_params['batch_size'],
callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the pruned model
pruned_test_loss, pruned_test_acc = pruned_model.evaluate(test_datagen.flow(test_data, test_labels, batch_size=best_params['batch_size']), steps=len(test_data) // best_params['batch_size'])
logger.info(f'Pruned Model - Test loss: {pruned_test_loss:.4f}, Test accuracy: {pruned_test_acc:.4f}')
# Save the pruned model
pruned_model.save('pruned_model.h5')
# Convert the pruned model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(pruned_model)
tflite_pruned_model = converter.convert()
with open('pruned_model.tflite', 'wb') as f:
f.write(tflite_pruned_model)
# Perform knowledge distillation
def distill_knowledge(teacher_model, student_model, data, labels, epochs=50, batch_size=32, temperature=1.0):
# Create a distillation model
teacher_output = teacher_model.output / temperature
student_output = student_model.output / temperature
distillation_output = tf.keras.layers.Lambda(lambda x: x)(student_output)
distillation_model = tf.keras.models.Model(inputs=student_model.input, outputs=[distillation_output, student_output])
# Compile the distillation model with distillation loss
def distillation_loss(y_true, y_pred):
student_loss = tf.keras.losses.categorical_crossentropy(y_true, y_pred)
distillation_loss = tf.keras.losses.KLDivergence()(teacher_output, student_output)
return student_loss distillation_loss
distillation_model.compile(optimizer=optimizer, loss=[distillation_loss, 'categorical_crossentropy'], loss_weights=[1.0, 0.0], metrics=['accuracy'])
# Prepare the train data for distillation
train_data_distill = train_data
train_labels_distill = tf.keras.utils.to_categorical(train_labels)
# Train the distillation model
distillation_model.fit(train_data_distill, [train_labels_distill, train_labels_distill], epochs=epochs, batch_size=batch_size)
return student_model
# Example usage of model distillation
student_model = create_model() # Create a smaller student model
distilled_model = distill_knowledge(loaded_model, student_model, train_data, train_labels)
# Evaluate the distilled model
distilled_test_loss, distilled_test_acc = distilled_model.evaluate(test_data, test_labels)
logger.info(f'Distilled Model - Test loss: {distilled_test_loss:.4f}, Test accuracy: {distilled_test_acc:.4f}')
# Save the distilled model
distilled_model.save('distilled_model.h5')
# Perform model compression
def compress_model(model, compression_factor=0.5):
# Create a compressed model
compressed_model = tf.keras.models.clone_model(model)
# Compress the model weights
for layer in compressed_model.layers:
if isinstance(layer, tf.keras.layers.Dense):
weights = layer.get_weights()
compressed_weights = [weight * compression_factor for weight in weights]
layer.set_weights(compressed_weights)
# Compile the compressed model
compressed_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return compressed_model
# Example usage of model compression
compressed_model = compress_model(loaded_model)
# Fine-tune the compressed model
compressed_model.fit(train_datagen.flow(train_data, train_labels, batch_size=best_params['batch_size']),
steps_per_epoch=len(train_data) // best_params['batch_size'],
epochs=50,
validation_data=val_datagen.flow(val_data, val_labels, batch_size=best_params['batch_size']),
validation_steps=len(val_data) // best_params['batch_size'],
callbacks=[early_stopping, model_checkpoint, reduce_lr, tensorboard_callback])
# Evaluate the compressed model
compressed_test_loss, compressed_test_acc = compressed_model.evaluate(test_datagen.flow(test_data, test_labels, batch_size=best_params['batch_size']), steps=len(test_data) // best_params['batch_size'])
logger.info(f'Compressed Model - Test loss: {compressed_test_loss:.4f}, Test accuracy: {compressed_test_acc:.4f}')
# Save the compressed model
compressed_model.save('compressed_model.h5')
# Convert the compressed model to TensorFlow Lite format
converter = tf.lite.TFLiteConverter.from_keras_model(compressed_model)
tflite_compressed_model = converter.convert()
with open('compressed_model.tflite', 'wb') as f:
f.write(tflite_compressed_model)
# Perform model optimization for inference
def optimize_model_for_inference(model):
# Create an optimized model
optimized_model = tf.keras.models.clone_model(model)
# Optimize the model for inference
optimized_model = tfmot.sparsity.keras.strip_pruning(optimized_model)
optimized_model = tfmot.quantization.keras.quantize_model(optimized_model)
# Compile the optimized model
optimized_model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return optimized_model
# Example usage of model optimization for inference
optimized_model = optimize_model_for_inference(loaded_model)
1
1
89

11 Feb 2023
grid that you have provided, then return the parameter combination that performs the best overall. This method is accessible from Sklearn's model_selection class.
6/6
1
3
21
11 Feb 2023
This method is accessible from Sklearn's model_selection class.
What is RandomizedSearchCV?
Another Hyper Parameter Tuning Technique is RandomizedSearchCV. Although this technique also uses cross-validation, it does so by having the model choose randomly from a parameter
5/6
1
2
9

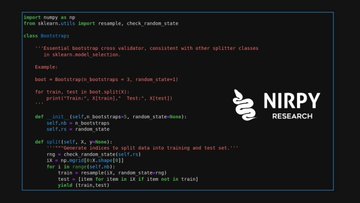
Bootstrap cross-validator consistent with other splitter classes in model_selection by @scikit_learn
#Python #chemometrics #DataScience #MachineLearning for #spectroscopy
1
2
Bootstrap cross-validator consistent with other splitter classes in model_selection by @scikit_learn
#Python #chemometrics #DataScience #MachineLearning for #spectroscopy

1
1

"A #model_selection approach to #structural equation #modelling: A critical #evaluation and a road map for #ecologists"
A great new paper by @gaiarrido @scott_k_hansen Rami Yaari and Hadas Hawlena
@MethodsEcolEvol
@mddeBGU
@bidrBGU
#network_structure
besjournals.onlinelibrary.wi…
4


14 Oct 2021
I sometimes think sklearn made a mistake because why would "train_test_split" be imported from model_selection and not preprocessing?
Isn't train_test_split closer to a preprocessing method than model_selection??
4
1
4

20 Sep 2021
"from sklearn import cross_validation" gives an import error.
Replace that with
"from sklearn import model_selection as cv"
And use it as
"... =cv.train_test_split(..."
#MachineLearning #DataScience
1
2

9 Sep 2021
scikit-learn==1.0.0 is coming soon! so cool! my most used scikit-learn modules/features from last couple of years:
- model_selection
- tree (decision tree)
- ensemble (random forest, extra trees)
- preprocessing (label encoder, one hot encoder)
- and some clustering ;)
6
8
173

23 Jul 2021
以下2つのオプションを追加してコミットしました🦔
・Face Detectionにmodel_selectionオプション追加
・PoseとHolisticでワールド座標系での動作確認(matplotlib)
github.com/Kazuhito00/mediap…
23 Jul 2021

MediaPipeのPoseとHolisticでワールド座標が返ってくるようになったため、とりあえずmatplotlibに投げ込んでみる🙄
11
45
21 Jul 2021
MediaPipeの0.8.6の変更点眺めてる🙄
・PoseとHolisticでワールド座標系の座標もあわせて出力するようにした
・Face Detectionにmodel_selectionオプション追加、近距離モデルと全範囲モデルが切り分けれるようになった(Face Detectionのみ、FacrMeshは無し)
github.com/google/mediapipe/…
4

8 Mar 2021
#今日の積み上げ
#Pythonデータ分析試験対策
#駆け出しエンジニアとつながりたい
回帰でソースコードを見直した。
回帰っていうのはある値を別の値で説明したタスクである。
データを学習させるとき、model_selection モジュールのtrain_test_split を使う。
クッソ眠い。
一度寝たがもう一度寝る。
6

17 May 2020
D030: Having a busy weekend, however still did something just to keep the mind code refreshed. Did a HandWrittenRecognition project using svm,metrics & some model_selection modules. #100DaysOfCode #100DaysOfMLCode #MachineLearning #DataScience @zerotomasteryio #Python
5
8

11 May 2019
そうか、__init__.pyの書き方次第でmodel_selectionにあるクラスに見えてファイル分割出来るんですね。
github.com/scikit-learn/scik…
2

2 Jan 2019
#golang
Happy new year !
I reworked my little sklearn port
- adapted to latest gonum/optimize changes
- added model_selection submodule with KFold and CrossValidate
godoc.org/github.com/pa-m/sk…
2
2
5

5 Jun 2018
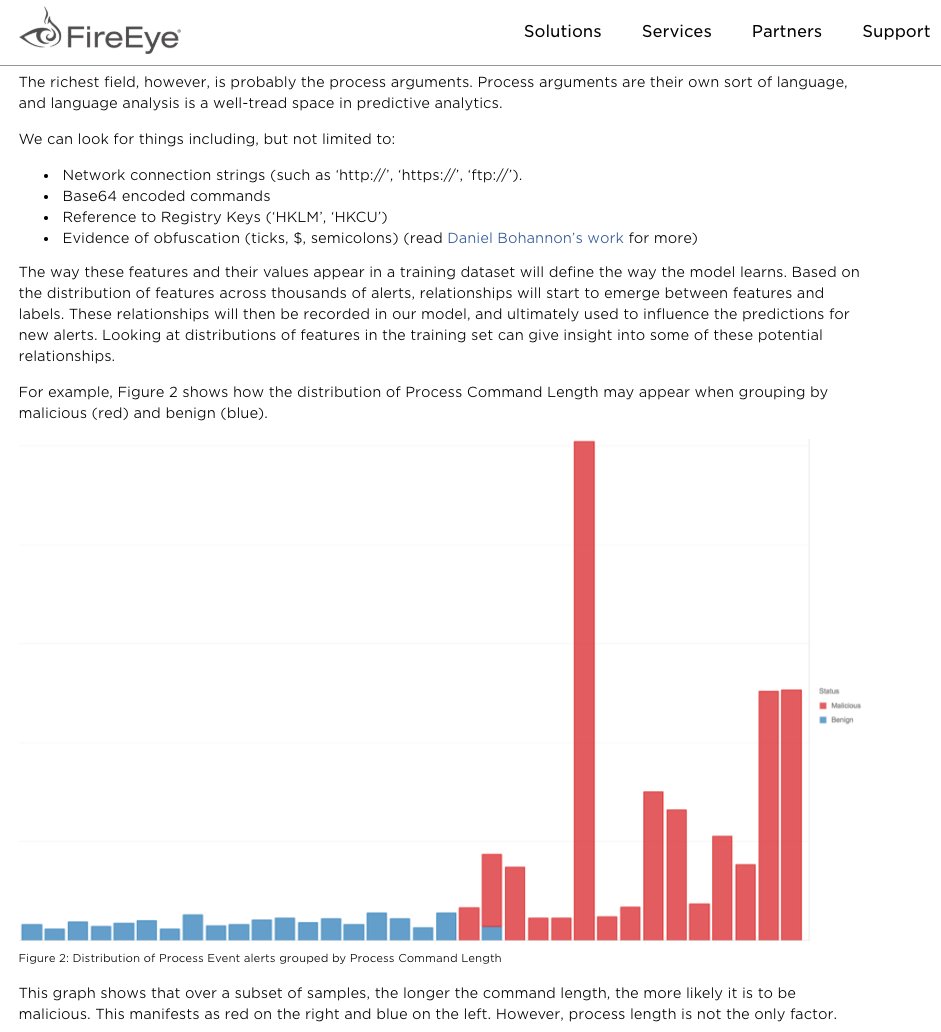
🚨 NEW BLOG ALERT: "Build Machine Learning Models for the SOC"
SOURCE: fireeye.com/blog/threat-rese…
AUTHORS: @secbern & @awalinsopan
FEATURES:
1⃣ Reverse_Engineering_the_Analyst
2⃣ Feature_Engineering
3⃣ Model_Selection
4⃣ SOC_Model_Use_and_Maintenance
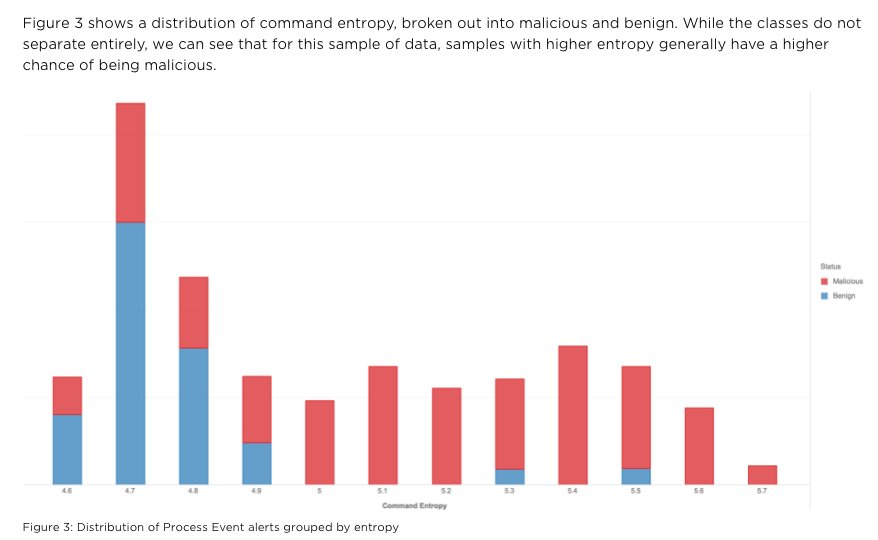
24
54