
13h
The row that violates your schema should fail the build, not surface in the lakehouse at 2am.
Declare types, nullability, and allowed values in metadata, and BimlFlex turns them into validation in the build. Break a rule and it fails before deploy.
varigence.com/bimlflex?utm_s…

6

Jun 12
#Kotlin is better than #Scala for dealing with nullability. #Java has JSpecify & upcoming support for null restrictions. In Scala we rely on social conventions (Option), while the type system is YOLO on `null`. And Scala 3's -Yexplicit-nulls is flawed.
contributors.scala-lang.org/…
2
46





It’s more nuanced than this. One example where zig is just better is an evm
- zigs pointers are typesafe against nullability unlike rust
- the correct memory strategy is arena allocation. Something that is way easier in zig and rusts borrow checker is overkill
- a good evm requires a lot of unsafe rust. Zig is better than unsafe rust
May 11

Unfortunately, I don't use Zig now. Every 1.5-5x human DX productivity boost from Zig features is eclipsed by the 100x boost from coding agents writing Rust:
Allocator interface:
This is my favorite Zig feature, you feel so galaxy brain using a specialized allocator to optimize a code path (e.g. arena, stack fallback etc). The problem in Rust used to be that there was no Allocator interface equivalent and if you wanted a Vec<T> that used a custom allocator you literally had to copy paste the std version and modify it to use it (this is what Bumpalo did, look at the source). For a long while now there has been an Allocator trait in nightly, and it seems to be good now. Because it is a trait it is static dispatch, vs Zig's which is based on a vtable. Unlike Zig there isn't a community-wide convention of designing data structures to be parametric based on the allocator, but AI changes the game and makes it trivially to copy paste code and change that. I find it works well enough for my use-case.
Arbitrary bit width integers packed structs:
Another beloved Zig feature of mine. It makes it so easy to do DOD-style CPU cache optimizations and stuff like tagged pointers, NaN boxing, etc. and even made bitflags really easy to make. You could always do this in Rust or any systems programming language but it was really ugly/unergonomic. The least worst option was using some crate like bitfield/bitflags which both rely on proc macro magic to work. Now, with coding agents I literally do not care how annoying it is to write the code by hand.
Comptime:
This is Zig's flashiest feature, no other programming language except maybe for obscure dependent-types langs have compile time evaluation as nice as Zig's. I thought I would miss it a lot, but I actually don't. For me, 95% of comptime usage is to create Zig's version of generic data structures with parametric types. Rust has a better designed type system IMO (see next section). In the remaining 5% of cases, not having comptime sucks. The only reliable way to reach an equivalent is through codegen. I'm making a game right now, and I have hardcoded hitbox geometry data generated from a tool that I want to bake into a data structure. Without comptime, I have to get Claude to write a script that generates the Rust file. However, I don't find myself needing compile time evaluation that much anyway.
Rust's type system:
I think I'd rather trade having comptime for Rust's better-designed type system, especially for bounded polymorphism (traits/typeclasses). Trying to do the equivalent in Zig is a nightmare. Also, I think that Rust's type system allows you to enforce more variants and prevent coding agents from making common mistakes. In my game I use the euclid crate which essentially allows you to not mix up coordinate spaces (very common problem in graphics programming) by creating specialized types for each coordinate space (e.g. Point<Screen> or Point<World>)
Not having to deal with memory issues:
With coding agents allowing 100x more code to be written, this also means you need to scrutinize 100x more Zig code for memory issues. Without formal verification, the surface area of the search space to enumerate to find bugs is just so much larger now. With the magnitude of code being generated now, Rust is even more attractive. Rust's tradeoff was always that it hinders developer productivity especially if you are unfamiliar with borrow checker, but this simply does not matter with coding agents anymore. And if you do use unsafe in Rust there's tools like miri which you can have the coding agent run the code against to make sure it doesn't cause UB or isn't violating Rust's aliasing rules when it comes to unsafe.
I still miss writing Zig and find it to be a great language but I like Rust more and coding agents work with better with it.
8
2
64
11,555

nullability by default is the fucking worst idea anyone has ever had
6
2
89
2,686
Swift Concurrency is really bl**dy complicated, which is great for me, financially.
Swift’s whole deal is making it really hard to write broken code: type-safe nullability, automatic memory management, and compiler guarantees around data races.
This is the whole reason your codebase suddenly grew 14,000,001 compiler warnings around non-Sendable classes. The Swift team were not being jerks, they wanted you to think about data isolation.
In a rare spurt of Apple humility, the team acknowledged this unintentional complexity in the Approachable Concurrency manifesto:
Swift’s built-in support for concurrency has three goals:
1. Extend memory safety guarantees to low-level data races.
2. Progressive disclosure, making basic use of concurrency easy.
3. Make advanced uses of concurrency to improve performance natural.
Swift meets the first goal, but it comes at the cost of the second, and can be frustrating to adopt.
Progressive disclosure is a core Apple design philosophy: make basic options easy to access, but reveal advanced use cases when needed. Think Dock → Finder → bash shell for working in your file system. The same approach applies to language design.
Easy to get started.
Straightforward to level up when needed.
Thus the Swift 6.2 Approachable Concurrency story began.
Learn the 3 tiers of Swift 6.2 approachable concurrency here 🎮 blog.jacobstechtavern.com/p/…

1
12
879

Micronaut 5 adopts the JSpecify nullability annotations.
micronaut.io/2026/05/02/micr… #micronaut #micronaut5

2
6
23
1,222

Java keeps int for raw performance and simplicity, while Integer exists to integrate numbers into the object-oriented ecosystem (collections, generics, frameworks, nullability).
Autoboxing/unboxing bridges the gap so you can use them interchangeably without much friction.
1
28
2,607

Mar 25
I increasingly think that trying to retrofit nullability onto dotnet was a mistake
It's nice when somebody tells you that they might be a null
You can't ever trust that something object-based that isn't indicating nullability is actually not-null
9
147

Long is an object (you can't compare with "==", you have to .equals()), also it can be null. Meaning you must check for nullability.
Both of these introduce subtle maintenance overhead that compounds over time. But in 99% of cases, primitives passed around turn out to be non-nullable, rendering this overhead absolutely unnecessary
1
2
259

Mar 5
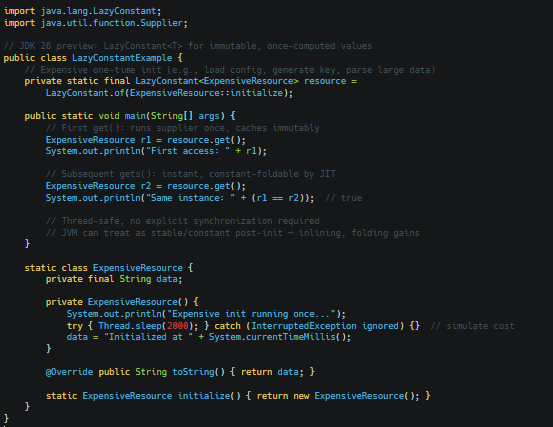
Lazy Constants (Second Preview) – JVM-Optimized, Safe Lazy Immutables:
JDK 26 previews Lazy Constants in JEP 526 (second preview). java.lang.LazyConstant<T> is an immutable holder that computes its value lazily via a Supplier exactly once on first get() then acts as a true constant for JVM optimizations (constant folding, stable fields, eager inlining). Unlike double-checked locking or holder classes, it's thread-safe by design, no user locks needed, no nullability risks, and better observability. Second-preview refines error propagation and serialization. Great for expensive singletons, parsed configs, or computed caches in libs/microservices where startup/hot-path perf counts.
2
20
753
Feb 28
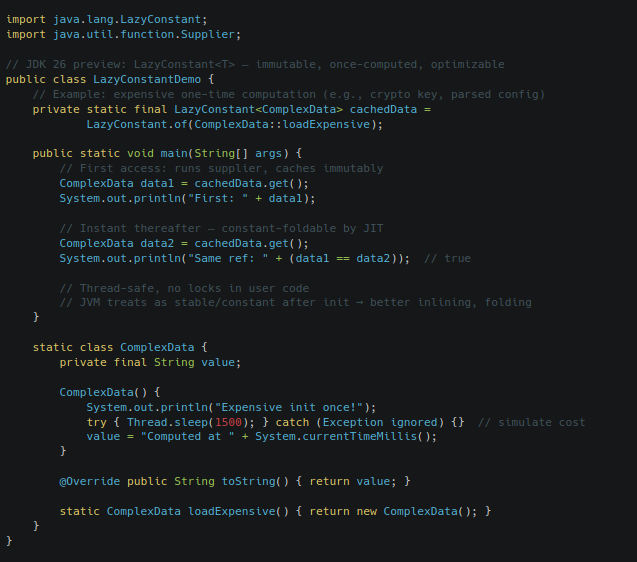
Lazy Constants – JVM-Optimized Immutable Lazy Init:
JDK 26 previews Lazy Constants in JEP 526 (second preview). java.lang.LazyConstant<T> offers a simple, thread-safe, immutable holder: compute via Supplier exactly once on first get(), then behave as a true constant for JVM opts like constant folding, stable fields, and eager inlining. Unlike double-checked locking or holder classes, no user synchronization, no nullability issues, and better observability. Second-preview tweaks refine error handling and serialization behavior. Ideal for expensive configs, caches, or computed constants in libs/microservices where startup latency or hot-path perf matters.
3
6
57
3,977

Feb 24
Making Maven Users Use JSpecify/NullAway More Easily with the Nullability Maven Plugin ik.am/entries/900/en
2
2
451
Feb 24
Nullability Maven Plugin で Maven ユーザーが JSpecify/NullAway を使いやすくする ik.am/entries/900
1
3
6
1,670

Feb 18
github.com/making/nullabilit…
A Maven plugin that configures ErrorProne and NullAway for nullability checking. It replaces the ~40 lines of maven-compiler-plugin boilerplate typically required to set up NullAway.
2
10
17
3,735

Feb 4
Yeah.
1. The key here is non-nullability
2. Use of querying pending state
3. Yeah, and still consistent
4. I'd call this parallel fetching or rather, showcasing reads aren't component level.
5. Boundary can exist below the fetch, self healing retries on errors.. ie it refetches.
6. Nested Loading opt out, and how transitions can keep disposed nodes alive, (count updates while rendering the next page).
7/8. Yeah
The overarching theme for almost all of these is how minimal the code would be different if the examples were synchronous instead of async. Really interesting for 7/8. Because optimistic data basically means UI code is unchanged.
3
155