
Senior Principal Architect at @VMwareTanzu / @Broadcom | Ex @Pivotal | Bichon Frise 🍋🐩
Joined April 2007
- Tweets 36,470
- Following 199
- Followers 3,738
- Likes 6,088
2,314 Photos and videos







Javaで実装したCommon Lispサブセット。インタプリタに加えて.lispからJVMバイトコードとWASMバイトコードにコンパイル可能
github.com/making/rontolisp
これ自体GraalVMでWASMにコンパイルしてブラウザで試せる
making.github.io/rontolisp/
selfhostのreplもwasmにコンパイルできる
github.com/making/rontolisp#…
1
294

Jun 10
spring.io/blog/2026/06/10/sp…
spring.io/blog/2026/06/10/sp…
spring.io/blog/2026/06/10/sp…
Spring Boot 4.1.0, 4.0.7, 3.5.15がリリースされました。
spring.io/security を見ると(AIによる)脆弱性Fixが60件以上取り込まれているので、今すぐアップデート!
10
24
2,305
Jun 5
先週の土曜日に見られて良かった

展示は終了しました。図鑑でしかみれない生き物。ご来館いただいた皆様ありがとうございました。
380
May 31
> HTTP2を有効にしてると、なぜか一部のテストが落ちる
h2cだと4KB以上のボディでTomcatが413エラーを返すやつだったりしませんか?
github.com/making/icelog/blo…
May 30

今から話す資料です! #jjug_ccc #jjug_ccc_c #jjug_ccc_cd
RestTemplate非推奨化に備えよう!RestClient入門、そしてリニューアルされたSpring Retryでリトライして、WireMockでテストする。 | tada #docswell
docswell.com/s/MasatoshiTada…
1
1
1,250
Toshiaki Maki retweeted

May 29
llama.cpp now has an official website: llama.app
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
96
483
2,980
164,051

May 23
reddit.com/r/SpringBoot/comm…
Spring BootとNode.jsで同じマイクロサービスを作り18ヶ月プロダクション運用で比較。インフラコストはSpring Bootが半額、メモリも安定。
だそうです
15
58
6,236
May 22
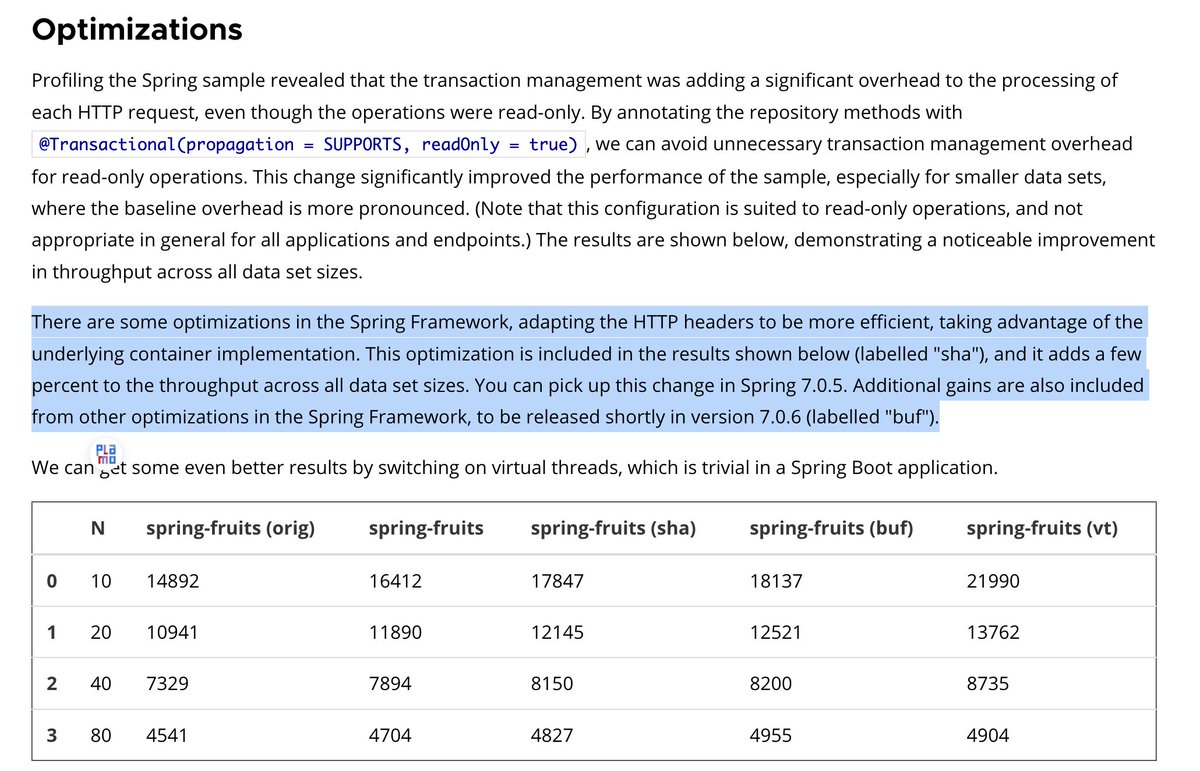
例えばSpring DataでRepositoryを作った場合、実体はこういうクラスが使われるけれど、全メソッドにトランザクションがはられている。トランザクションをRepostioryかUsecase(Service)にはるかではなく、ネストさせた上でどう伝播させる(既存に参加、新規作成等)か、だと思う
github.com/spring-projects/s…
May 21

Javaだと当たり前だけど、他の言語・フレームワークだとそうじゃないのかな。
両方にトランザクション貼ってネストさせて、必要に応じて伝播属性を調整すればええやん。
2
26
11,425
May 21
Javaだと当たり前だけど、他の言語・フレームワークだとそうじゃないのかな。
両方にトランザクション貼ってネストさせて、必要に応じて伝播属性を調整すればええやん。
May 20
トランザクションの伝播について誰も言及していないのは何故?
1
4
37
56,141
May 20
トランザクションの伝播について誰も言及していないのは何故?

12
39,759
May 19
llama.cppのMTPサポートのおかげで、Qwen3.6-27B on DGX Sparkで、26 tok/s 出るようになった。以前は11 tok/s だったので、だいぶ快適になった。
1
602
Toshiaki Maki retweeted
May 18
llama.cpp adds MTP for the Qwen3.6 family
This is a significant milestone for the local AI ecosystem. The performance jump with these changes is massive and elevates local inference on commodity hardware further.
Special thanks to Aman Gupta for leading this development!
github.com/ggml-org/llama.cp…
48
180
1,202
273,144
I just pushed a big refactoring of DS4 backends with CUDA support and single direction activation steering. The Metal path should be unaffected. Note: I only support hardware I have own (or have full access to): so just M3 (no M5 NE for now), DGX Spark.

Soon in DS4: 1. CUDA support (14 t/s, 350 t/s prefill on DGX Spark), 2. Single direction steering support. 3. Huge refactoring to support Metal / CUDA / CPU in a more sensible way.
6
11
165
18,111