
Literally anybody(!) who wants can read and comment on my draft paper ( jascal.github.io/fieldrun/pa… ), or they can use the longer form, human friendlier materials I made to go with it ( jascal.github.io/fieldrun/ ). @terrence_tao @HarmonicMath @elonmusk @GaryMarcus #Openscience
1
19

Let's clear up what $CITE actually is. 🧵
❌ MYTH: "It's just another crypto coin to speculate on."
✅ FACT: It's a utility token you EARN by contributing — publishing, validating, reviewing. You can't buy reputation.
❌ MYTH: "There's a presale to get rich early."
✅ FACT: No presale. No hype. Product and audit come before any mainnet token.
❌ MYTH: "Crypto means it's not for serious academics."
✅ FACT: It's built FOR researchers — ORCID identity, open access, real integrity.
Science deserves better incentives. That's all this is.
citechain.org
#DeSci #OpenScience

1
7
Zimbabwe University Libraries Consortium (ZULC) retweeted

🚨 Zimbabwe's #OpenScience future starts with collaboration!
Join researchers, librarians, policymakers, and scholarly communication stakeholders at the Zimbabwe Open Science Stakeholder Convening during #ZULC2026.
Register: us02web.zoom.us/meeting/regi…

1
1
19
$TAO vs $GL1 retweeted

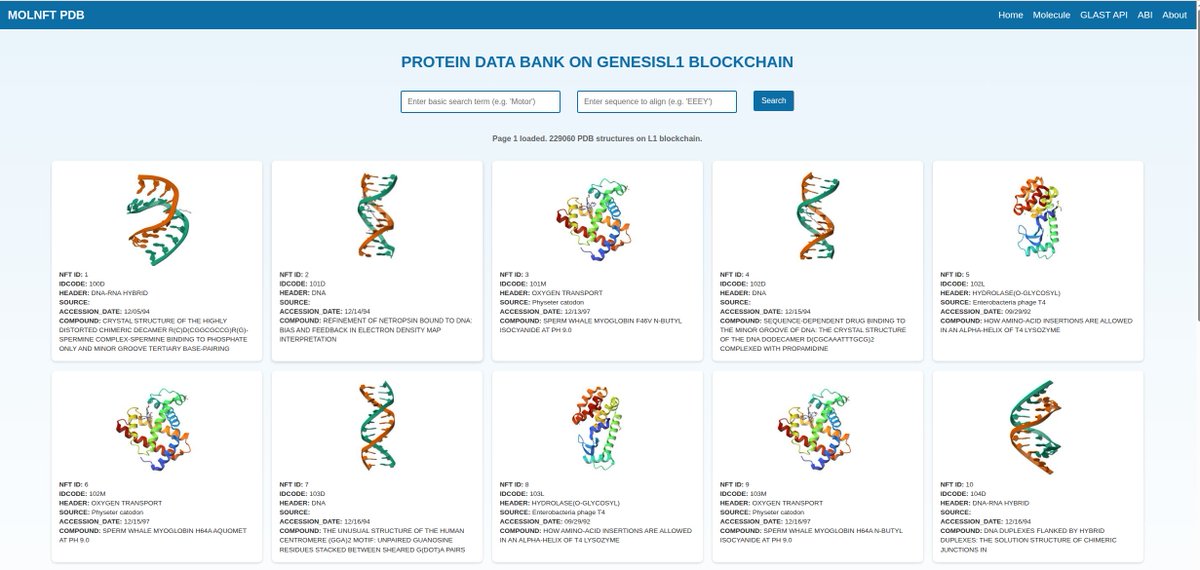
#DeSci infrastructure and primitives. #MolNFT #BioTech #OpenScience #GenesisL1
app.molnft.org
molnft.org
Why MolNFT? On-Chain Molecular Data, Explained
MolNFT places complete macromolecular structural data directly on GenesisL1, where it can be read natively by web3 applications. The first reaction from scientists and crypto-natives alike is some version of the same question: the data already exists and moves freely elsewhere — why does it need to be here?
That is the right question, and it deserves a direct answer rather than a slogan. The short version: MolNFT is not trying to replace the Protein Data Bank, and its value is not the data. Its value is what becomes possible when structural data is a native, verifiable, composable on-chain object. MolNFT is infrastructure; the science built on top of it is the impact. The same question gets a different answer depending on where you are standing, so we answer it for both audiences below.
The Protein Data Bank is free, open, CC0-licensed, and wrapped in excellent APIs (RCSB, PDBe). Why does any of this need to be on-chain?
Because MolNFT is not a redistribution of the PDB; it is infrastructure built on the same public data. The distinction is everything. Mirroring RCSB on-chain would be pointless — the existing mirrors are excellent, fast, and free, and you should keep using them. What the public databases cannot do is let a structure act as a verifiable, programmable component inside other on-chain systems.
A structure in MolNFT is not merely retrievable. It is referenceable with cryptographic integrity, ownable and licensable as a discrete object, and directly callable by other on-chain logic. The PDB gives you the data. MolNFT gives you the data as a building block that contracts, models, and applications can use without trusting any intermediary. Everything below follows from that single difference.
(For a crypto-native reader) Isn't this just "tokenize everything"? Tokenized stocks already trade fine on centralized exchanges — why put assets on-chain at all?
"It already exists elsewhere" has been said about every successful tokenized asset — stablecoins, tokenized treasuries, tokenized gold, tokenized equities — and demand materialized anyway, because the product was never the novelty of the underlying. It was composability, programmability, and permissionless access.
Tokenized AAPL matters not because shares were hard to buy, but because the token can become collateral in a lending market, a leg in an automated strategy, or a component in a structured product without asking anyone's permission. MolNFT applies the same logic to molecular data: the point is not that structures were unavailable, but that they could not be consumed programmatically by on-chain systems. A protein structure that a smart contract can read, reference, and run a model against is a different kind of object than a file behind a REST API.
There is one inversion worth stating plainly, because it is a place where MolNFT is stronger than a tokenized stock rather than merely analogous. A tokenized stock can never escape the backing question: the token is a claim on a share held by a custodian, and it carries counterparty and redemption risk. The token is a pointer to value sitting somewhere else. MolNFT, when it stores the full structural data on-chain, has no such dependency — the asset is the data itself, not a claim on data held off-chain. There is nothing to redeem and no custodian to trust.
That is a higher-integrity guarantee than any tokenized real-world asset can offer. The caveat is the same fact that makes the claim meaningful: this only holds if the complete data lives on-chain, not as a hash pointing at a file that can move, change, or vanish. Full data on-chain is the difference between an asset and an IOU.
(For a scientific reader) What does on-chain storage give a researcher that RCSB or PDBe doesn't?
For everyday structure retrieval, nothing, and you should keep using them. MolNFT addresses a different set of problems, all downstream of one property the public databases do not provide: a permanent, cryptographically verifiable reference that cannot be silently changed.
Reproducibility. A method that references an on-chain structure by its hash can prove, years later, the exact bytes it was computed against — even if the canonical PDB entry is subsequently revised, re-refined, or superseded. The version you ran against is frozen and verifiable, not "whatever the database happens to serve today." For any pipeline whose results depend on the precise input coordinates, that is the difference between a reproducible claim and a best-effort one.
Attribution and provenance. Derived work — a trained model, a curated subset, a benchmark — can reference the exact structures it was built from, immutably. That creates rails for credit, and where desired for licensing or royalty flow back to data curators, which do not exist when the inputs are anonymous CC0 bytes pulled from an endpoint. Provenance stops being a footnote and becomes a property of the object.
Composability with computation. This is the consequence that is new rather than incremental, and it is large enough to deserve its own answer below.
In the vocabulary that matters to scientists — reproducibility, provenance, verifiable benchmarks — these are real gains, not financialization dressed up as research.
What can you actually build with MolNFT that you can't build today?
This is the strongest reason MolNFT exists, and it is where the crypto and scientific cases finally converge. GenesisL1 supports on-chain ML inference, which means a model, a structure, and a prediction can all live on the same chain as mutually referenceable objects, and a computation over them can be verifiable from end to end.
Concrete example: a protein-stability (ΔΔG) prediction model deployed on-chain can take an on-chain MolNFT structure as input and produce a prediction whose entire lineage — which model, which weights, which input structure — is verifiable on-chain, with no off-chain trust anywhere in the path. A third party can independently confirm that this model produced this prediction from this structure. Today that chain of custody lives in a private notebook, a data-repository upload, and a README, and any link in it can rot or be quietly altered. On-chain, the whole pipeline is a single verifiable record.
The capability compounds. Structures reference the models trained on them; models reference the structures they consumed; predictions reference both. The result is a verifiable scientific dependency graph: the substrate for reproducible computational biology, and for a marketplace of composable models and data where each can be used, credited, and built upon without trusting a host. A single dApp call can pull a structure and run inference against it. None of this is reachable when the structure is a file behind an API and the model is a binary on someone's hard drive.
How is this different from speculative projects that wrap public data just to launch a token?
Two tests separate infrastructure from a wrapper, and MolNFT is built to pass both.
First, the data is real and complete on-chain. The asset is the structure itself, not a pointer to a file that can disappear — which is precisely the failure mode of most "tokenized data" projects, where the token survives but the data it supposedly represents drifts away. If the bytes are on-chain, the integrity guarantee is real; if they are not, no amount of tokenization fixes it.
Second, there is a real consumer. GenesisL1's own on-chain inference stack, including a protein-stability predictor, is designed to take MolNFT structures as inputs. A working application that reads on-chain structures is the molecular-data equivalent of an asset already being used as collateral in a live market: it converts hypothetical composability into demonstrated composability. A wrapper has a token and a promise. Infrastructure has a dependent application.
MolNFT is not the PDB on a blockchain. It is the substrate that lets structural data carry provenance, participate in computation, and compose with other on-chain objects — and the science built on that substrate is the point.
4
8
548

Look at the biomimetic fish test: Same kinematics, but the experimental model is faster because it actually "catches" its own vortex waves! 🌊
github.com/MasterOgon/Aeroac…
#FluidDynamics #Biomimetics #PhysicsSimulation #Coding #OpenScience
1
10

📣 JMIR Publications has signed a 3-year partnership with MetaROR to advance open science and transparent peer review.
The collaboration will focus on integrating MetaROR’s publish-review-curate platform with JMIR’s innovative publishing ecosystem—specifically its JMIRx overlay journal series, including JMIRx Med and JMIRx Bio.
Read more about the partnership: jmirpublications.com/announc…
#OpenScience #PeerReview #Metascience #ResearchIntegrity

2
57

📢 ¡Buenas noticias para la comunidad de Salud UIS! Se mantiene la categoría B en resultados preliminares de Clasificación Publindex-2026. Gracias por ser parte de este logro. 🚀📚
#SaludUIS #Publindex #CienciaAbierta #AccesoAbiertoDiamante #OpenScience #Investigación #UIS



1
1
6
Jackson Cionek retweeted

Cerebro-Cerebro en el Aula | fNIRS Hyperscanning y Aprendizaje
#LanguageERP #SuperBowl2026 #DREX #OpenScience
brainlatam.com/blog/cerebro-…
27
12
74
Olmeca - Brain retweeted

Aleixo Cionek com Bonifácio Cionek
#OpenScience #EEGResearch #Hyperscanning #Multimodal
brainlatamimages.com/blog/av…
23
14
62
Olmeca - Brain retweeted

Perspectives for the Study of Pain - NIRS fNIRS
#OpenScience #SuperBowl2026 #CBDCdeVarejo #P300
brainlatam.com/blog/mapping-…
36
17
125
Olmeca - Brain retweeted
Sacando a Satanás de la SalaSerie: Respiración, Cuerpo, Conciencia y Cambio...
#Hyperscanning #OpenScience #Jiwasa #DrexCidadão #EEG #CrossCultural #PIX #fNIRS
brainlatam.com/blog/sacando-…

24
14
147
Olmeca - Brain retweeted
Jiwasa——集体自我中的学习与教学
#Jiwasa #Multimodal #Decolonial #Hyperscanner #PIX #NIRS #Neuroscience #fNIRS #EEG #OpenScience #CrossCultural #RMSSD
religareyourself.com/blog/ji…

37
16
182
Olmeca - Brain retweeted

fNIRS hyperscanning em díades mãe–filha com FXS
#NonWEIRD #Jiwasa #OpenScience #RMSSD
neurosciencegrrl.net/blog/fn…
33
16
90

19h
A major new consensus piece from editors across leading cardiovascular and biomedical journals argues that AI is no longer a future issue in scientific publishing—it is already embedded throughout the research lifecycle. The challenge is no longer whether AI should be used, but how transparency, accountability, and scientific integrity can be preserved as AI becomes ubiquitous.
Key points:
🔹 AI can accelerate discovery, literature synthesis, data integration, hypothesis generation, and manuscript preparation.
🔹 AI also introduces substantial risks:
• fabricated references and hallucinated content
• paper-mill amplification
• biased outputs
• image manipulation and synthetic data generation
• erosion of authorship responsibility
🔹 Detection is not enough.
The authors argue that AI-text detectors have limited reliability and may unfairly flag non-native English writers. Instead, scientific publishing should shift toward:
• transparency
• provenance tracking
• audit trails
• human accountability
🔹 Authors remain fully responsible.
AI cannot qualify as an author. Researchers must disclose:
• which AI tools were used
• model versions
• prompts/workflows when relevant
• verification procedures used to confirm accuracy
🔹 Reproducibility becomes harder in the AI era.
The same prompt can generate different outputs across model versions and updates, making documentation of model version, date of access, and settings increasingly important.
🔹 Journals are beginning to require:
• AI disclosure statements
• raw data submission
• source-code transparency
• AI-specific reporting standards
• provenance metadata
Perhaps the most important message:
➡️ The future of scientific publishing is not “AI vs humans.”
➡️ It is “AI as a tool, under explicit human responsibility.”
The authors propose that the red line is crossed when responsibility for scientific content, interpretation, or conclusions is transferred from identifiable researchers to automated systems.
AI can enhance rigor and efficiency, but only if accountability remains human.
"AI is a tool, not an author."
Reference:
Guzik TJ et al. Artificial Intelligence in Biomedical Scientific Publishing. European Heart Journal (2026).
#AI #ScientificPublishing #AcademicMedicine #ResearchIntegrity #BiomedicalResearch #Cardiology #GenerativeAI #OpenScience #PeerReview #MedicalResearch

1
5
15
527
Jackson Cionek retweeted
NIRS–EEG Hyperscanning para 5 Participantes
#Hyperscanner #RMSSD #OpenScience #P300
neurosciencegrrl.net/blog/ni…
27
12
52