

Wanted a quiet Sunday after the @w3match launch
Made it 70% of the way 😅
The other 30%:
> Speed optimizations
> Matching improvements
> W3Match Skill
That last one is big.
Imagine having the full W3Match knowledge base inside Claude or Codex:
> Find partners among real users
> Improve your profile based on your AI's knowledge
> Create content from the latest news in the database
Early this week, OGs and top inviters get free beta access.
Not on W3Match yet? First 20 spots:
w3match.com/invite/T2FBHCK5
After that, look for invites in the comments.
What would you use the W3Match Skill for?
1
3
32

maMvelase ❤️ retweeted

ClickHouse Power Tips - Too Many Parts, Schema Optimizations, Query Analytics, When to Partition, Understanding MergeTree, Monitoring, and more. Check out our blog series!

20
68
353
3,455,117

Ya qwel did a stream on discord where she revealed that stickers, a new machine, merch, a new toon, skins, dandy sprout and cosmos optimizations and lots of other goodies were coming
1
3
45
Mohammed Ibrahim retweeted

Love to see it! 🚀
One day in and the community is already shipping optimizations for faster decode. 🥳

Made some improvements on the decode path for MiniMax M3 by @MiniMax_AI on MLX-VLM
Faster decode, slightly lighter footprint.
Thanks to @ivanfioravanti for the PR 🚀
PR:
github.com/Blaizzy/mlx-vlm/p…

6
9
223
16,269

39m
I'd say it's a successful project. Minimal on purpose, has great optimizations, and is formally proven to be correct. It's finished software. Only reason it doesn't have much adoption is because people take the path of least resistance and usually don't care. They'd rather use FreeRTOS as it has the tools available.
21

🎮 PS VR2 update for Death Horizon: Reloaded is LIVE!
👉 store.playstation.com/en-us/…
🏆 Fixed broken trophies
📊 Improved online leaderboards
🎮 Enhanced haptic feedback
⚡ Better adaptive trigger effects
🔧 Additional bug fixes & optimizations
#DeathHorizonReloaded #PSVR2 #PS5
1
4
7
77

Hypothesis: getting a given level of AI to be cheaper is mostly about doing grinding optimizations on it
Premise: Mythos 5 is really good at this sort of optimization
Prediction: We get much cheaper Mythos-class models fairly soon
3

Xiaomi 18 may have appeared in the GSMA database 👀
What the leak suggests:
• Codename: "madrid"
• Global, India, China & Japan variants spotted
• 6.3–6.4-inch compact flagship design
• Snapdragon 8 Elite Gen 6 Pro
• LPDDR6 memory
• HyperOS next-generation optimizations
Interestingly, Xiaomi's internal model-number strategy appears to have changed, making it unclear whether "madrid" is the Xiaomi 18 or Xiaomi 18 Pro.
The model number also hints at a possible November 2026 launch window, later than some earlier leaks suggested.
A compact flagship with next-gen silicon is still very much on track.

4
148

Explain the benefits of the original optimizations and the follow on optimizations you proposed @grok
1
5

That's the thing, despite optimizations, their demand for energy seems to be only growing and their energy still relies on the older industries which harmfully impact the environment as a whole and if AI adoption continues you grow, more users will mean more demand for energy.
1

well ios 27 is planned to have a lot of optimizations, as well as changes to liquid glass to like make it more usable, like a transparency slider, i think it would be a good idea to update in september/october when the software becomes stable
22

that it’s not JUST about writing faster kernels. lots of low hanging fruits out there. chasing microsecond optimizations are fruitful only when the other simpler but “boring” things are taken care of.
1
36

Growtics is a privacy-first (fully cookieless), lightweight website analytics platform with an AI Growth Agent. It doesn't just show you metrics — it actively monitors your site, spots issues (SEO, UX, performance), and delivers daily actionable growth tasks like directory submissions, content fixes, or conversion optimizations.
growtics.io
18


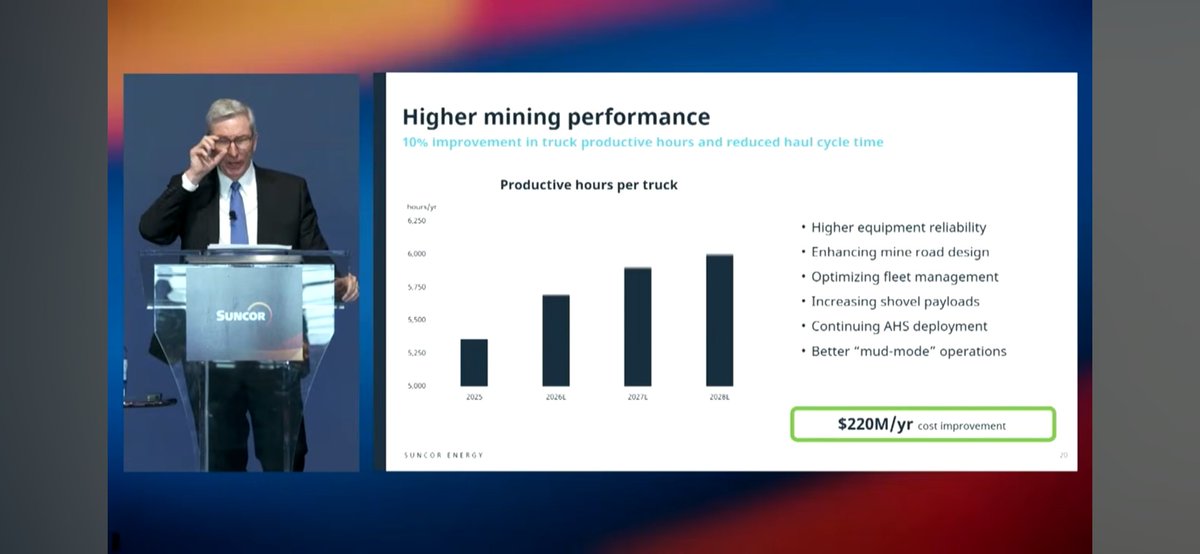
For a haul truck they can also do optimizations using data. Small changes = big results
1
1
11

Layered Protection: The Real Answer
◦Specific harness implementations: custom orchestration logic, memory systems, routing decisions, tool integrations, or feedback mechanisms that aren’t publicly disclosed.
◦Training data selection/curations, fine-tuning processes, and model parameters.
◦Internal know-how, failed experiments, and configuration details.
5How companies actually protect them (reasonable measures required by law):
◦Contracts: NDAs with employees, contractors, and partners; employment agreements with confidentiality clauses; restrictive licenses if any part is shared.
◦Access controls: Need-to-know basis, role-based permissions, logging/monitoring of access.
◦Technical measures: Encryption, secure environments, model watermarking/fingerprinting, code obfuscation (where feasible), and secure deployment practices.
◦Policies and processes: Clearly label information as confidential, regular employee training, audits, and strict offboarding procedures (return or destroy materials).
◦Documentation: Precisely define what is secret (vague descriptions like “our algorithm” don’t work well in court).
6Advantages: Immediate protection, no registration or public disclosure, can last indefinitely (as long as secrecy is maintained). Perfect for fast-evolving AI where patents move too slowly.63
Limitations: Protection ends if secrecy is lost (e.g., public disclosure, independent invention, or successful reverse engineering — though complex AI systems are often hard to fully reverse-engineer). Enforcement requires proving misappropriation.
Best Practice: Combine Them Strategically
Most sophisticated companies use all three in a layered “moat”:
•Copyright the code.
•Patent the truly novel inventions.
•Keep the secret sauce (specific implementations, data processes, optimizations) as trade secrets.
•Use contracts and technical controls everywhere.
•For deployment: Combine with technical measures like running in secure enclaves or on controlled infrastructure.
In the context of the original discussion (government restrictions cutting off access to models like Anthropic’s Fable/Mythos):
•Relying solely on a centralized provider’s models/infrastructure creates exactly this vulnerability.
•Building and owning your own harness infrastructure (e.g., on decentralized platforms like NEAR Protocol, which focuses on open infrastructure and user-owned agents) protecting your custom layers with the above methods gives real control and sovereignty.64
Bottom line: Copyright alone is insufficient and doesn’t reach the mathematical/probabilistic underpinnings you mentioned. The strongest protection for unique AI infrastructure comes from trade secrets (for the proprietary, non-public elements) layered with copyright for code and patents for patentable innovations, backed by strong contracts and security practices.
If you have more specifics about the exact harness/tensor components you’re thinking of (or the context from the original post), I can refine this further. Legal strategies should always involve qualified IP counsel tailored to your jurisdiction and situation.
8
**Copyright is not the primary or sufficient answer** for protecting the core of tensors, harness systems, or unique AI infrastructure. You’re right that it doesn’t cover the underlying mathematical foundations — things like multi-dimensional arrays (tensors), linear algebra operations, probability distributions, sampling methods, or abstract algorithmic ideas. Copyright protects *specific expressions* (e.g., the exact source code you wrote to implement something), not the ideas, math, or functionality itself.<grok:render card_id=“5ec53b” card_type=“citation_card” type=“render_inline_citation”><argument name="citation_id">62</argument></grok:render>
### Layered Protection: The Real Answer
Companies (especially in AI) use a **portfolio or layered approach** combining several tools. No single method is perfect, especially for fast-moving fields like agent harnesses (the orchestration layer around models: routing, memory management, tools, context handling, sandboxes, feedback loops, etc.).
Here’s how it works in practice for unique infrastructure:
1. **Copyright (baseline, limited protection)**
- Automatically protects your original code implementing the harness or tensor operations.
- Covers things like specific implementations, documentation, or user interfaces.
- **Does not protect**: The underlying math, algorithms as ideas, model architectures in the abstract, training methods, or data structures conceptually.
- Easy and cheap, but weak against someone who reimplements the same functionality differently.
2. **Patents (stronger exclusionary rights, where eligible)**
- Can protect *novel, non-obvious technical methods or systems* — for example, a specific new routing algorithm in a harness, an innovative memory architecture, or a particular optimization technique for tensor operations that provides a technical improvement.
- Hardware-related aspects of infrastructure are often easier to patent.
- **Limitations**: Abstract ideas, pure math, or obvious applications of existing ML techniques are often not patentable (especially in the US under current eligibility rules). The process is slow and expensive, and patents become public. Many AI companies file selectively for key inventions while relying on other protections for the rest.<grok:render card_id=“691798” card_type=“citation_card” type=“render_inline_citation”><argument name="citation_id">48</argument></grok:render>
3. **Trade Secrets (often the most practical and heavily used for AI internals)**
This is frequently the **core strategy** for proprietary harness systems, model parameters/weights (if not released), training/fine-tuning processes, data curation methods, specific optimizations, and confidential configurations.<grok:render card_id=“682cb7” card_type=“citation_card” type=“render_inline_citation”><argument name="citation_id">27</argument></grok:render>
Trade secrets protect information that:
- Has independent economic value from not being generally known, and
- Is subject to reasonable efforts to keep it secret.
**What can typically be protected as trade secrets**:
- Proprietary algorithms and optimization techniques (including how you handle tensors or probability in your system).
- Specific harness implementations: custom orchestration logic, memory systems, routing decisions, tool integrations, or feedback mechanisms that aren’t publicly disclosed.
- Training data selection/curations, fine-tuning processes, and model parameters.
- Internal know-how, failed experiments, and configuration details.
**How companies actually protect them** (reasonable measures required by law):
- **Contracts**: NDAs with employees, contractors, and partners; employment agreements with confidentiality clauses; restrictive licenses if any part is shared.
- **Access controls**: Need-to-know basis, role-based permissions, logging/monitoring of access.
1
13