
PDFDocument is now on Android.
Generate PDFs, forms, attach files, from your Xojo built mobile app.
2025r3. documentation.xojo.com/resou…
#Xojo #MobileApps
1
3
99
PDFDocument API in Xojo:
- Draw with PDFGraphics (like regular Graphics)
- Add tables with PDFTable
- Embed files, sounds, movies
- Create interactive forms
- Set metadata (Author, Title, Keywords)
- Supports custom page sizes and embedded fonts.
documentation.xojo.com/api/p…

2
58

Feb 8
I just got an automated email from my database provider:
"Your database will be deleted soon due to 0 activity."
My first thought: *Is the app dead?
Did everyone stop using it?*
I panicked for a second.
I knew people were installing it.
I knew I just got a sale from X.
So why was my backend reporting zero traffic?
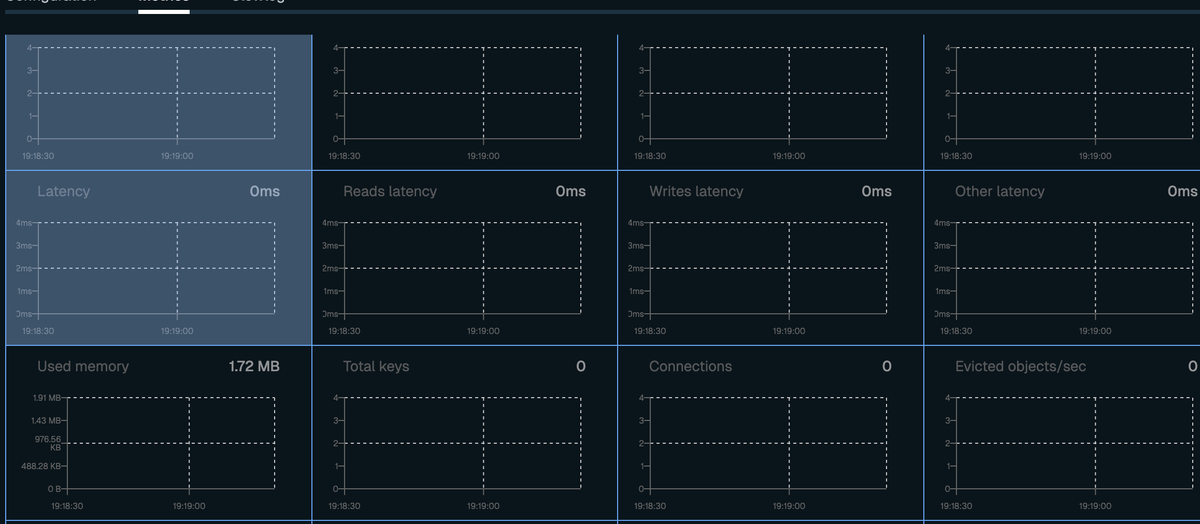
I logged into my Vercel dashboard and Redis Cloud metrics to see what was going wrong.
I looked at the "Ops/sec" graph.
*Flatline. 0.00 ops/second.
I thought the connection was broken.
I opened the app on my phone, triggered the "AI Document Scanner" (which talks to Gemini), and immediately saw a spike on the graph.
The connection was perfect.
Then it hit me: The "No Activity" warning wasn't a failure. It was the ultimate proof of my architecture.
When I built Anti-Gravity (PDF Tool Pro),
I promised that "Your data never leaves your device."
To make that real, I built the Splitter, Merger, and Watermark tools to run 100% locally on the user's phone.
- No cloud proxies.
- No server-side processing.
- No data "phoning home."
Because my users are using the app for privacy-sensitive PDF work, they ARE using it, but my server has no idea.
My tech stack thinks the app is dead because it's used to "chatty" apps that steal your data every 5 seconds.
To be specific:
Zero Network Calls:
When a user clicks "Merge" or "Watermark," the app uses a library called pdf-lib
On-Device Processing:
The code imports PDFDocument directly into the user's phone memory.
It reads the file, merges the pages, and saves the new PDF without ever sending a single byte to server.
Why the Redis Metrics were "Flat":
It only talks to the backend (Redis) if:
- AI is used: It needs to ask Gemini a question.
- A Purchase happens: It needs to verify a receipt.
- User Logs In: It needs to check a Google account.
Privacy isn't just a marketing line. Sometimes it looks like a "No Activity" warning from your own database.
3
1
6
111
🙌 Massive Thanks to November Year of Code Stars! 🙌
What a finale! You all crushed the PDF challenge with creativity. Your projects showcase Xojo's PDFDocument power and inspire us all. Congrats to participants!
🔗 Forum: forum.xojo.com/t/2025-year-o…
#YearOfCode #PDFProjects #DevCommunity
8
92
📬 Nov Year of Code: PDF 's!
Image message → auto-cropped, shadowed PDF postcard. Graphics PDFDocument showcase.
Download, build, forum-share for prizes!
🔗 blog.xojo.com/2025/11/10/yea…
#Xojo #YearOfCode
1
3
95

31 Oct 2025
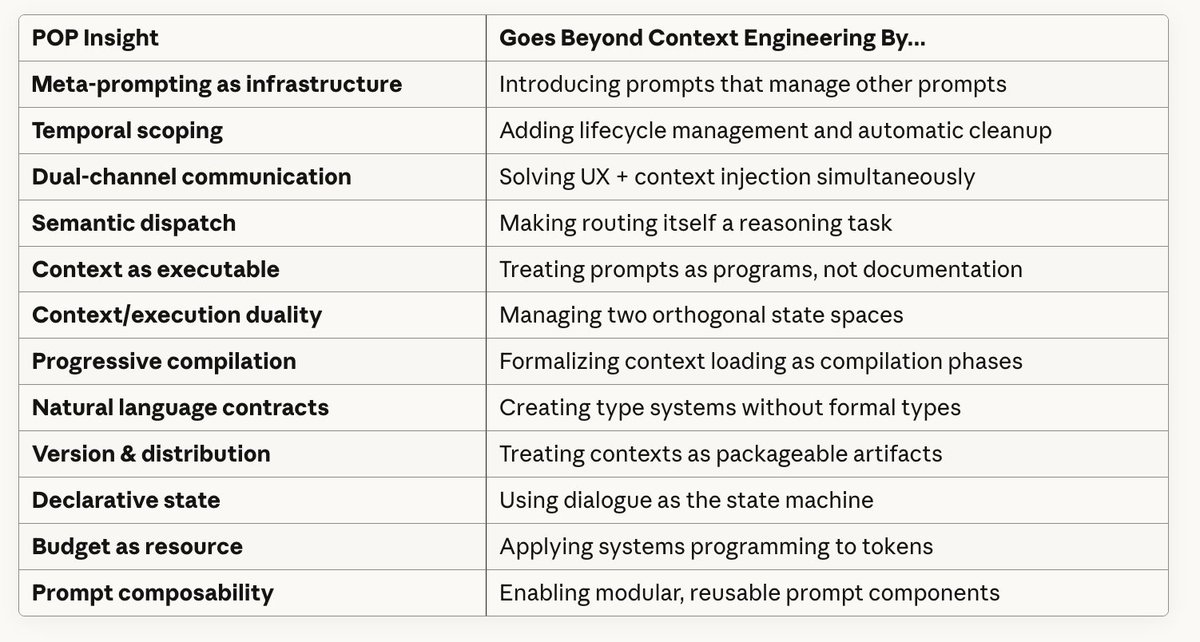
The 12 Architectural Innovations That Prompt-Oriented Programming Adds to Context Engineering
Prompt-Oriented Programming goes beyond good context engineering.
After mapping every architectural decision in Claude's skills system, I found 12 patterns that don't exist in Anthropic's context engineering guidelines.
These aren't refinements. They're novel inventions.
Let me show you what I mean. 🧵
Anthropic's context engineering guide is excellent. It tells you:
Keep prompts at the "right altitude"
Use progressive disclosure
Manage token budgets
Load context just-in-time
But here's what it doesn't tell you:
How to build an architecture where prompts manage themselves.
Innovation #1: Meta-Prompting as Infrastructure
Context engineering: "Manage what goes in the context window"
POP: "Build prompts that decide which other prompts to load"
The Skill tool isn't just a prompt. It's a meta-prompt that orchestrates other prompts.
Skill Tool → Reads available skills
→ Guides selection
→ Loads chosen skill
→ Modifies context
This is prompts managing prompts. Infrastructure-level meta-programming.
Think about what this enables:
Traditional: You (the engineer) decide what context to load
POP: The AI participates in curating its own context based on semantic understanding of the task
The system becomes self-organizing.
But that's just the start.
Innovation #2: Temporal Scoping
Context engineering says "context is limited."
POP says "context should have lifetimes."
Like variables in programming:
def process():
temp = load_data() # ← Scoped to function
# use temp
# ← temp destroyed here
Skills work the same way:
[General] → [PDF skill active] → [General]
↓ temp context ↓
auto-cleanup
Specialized context is temporary and self-cleaning.
This prevents context pollution across tasks in the same session.
Innovation #3: Dual-Channel Communication
Here's a problem context engineering doesn't address: How do you inject detailed instructions without overwhelming users?
POP's solution: Two parallel message channels in the same stream
{
content: "Loading PDF skill",
isMeta: false // User sees
},
{
content: "[5000 words of instructions]",
isMeta: true // Claude sees, user doesn't
}
Transparency without clutter. The architecture solves UX and context injection simultaneously.
Innovation #4: Semantic Dispatch as Architecture
Context engineering assumes you know what to load.
POP inverts this: Let the AI decide through reasoning, not routing code.
No if/else chains:
# ❌ Traditional
if file_type == "pdf":
use_pdf_processor()
# ✅ POP
# Claude reads skill descriptions
# Semantically matches user intent
# No routing logic needed
When your system is intelligent, dispatch itself becomes a reasoning task.
Innovation #5: Context as Executable Artifact
This one changed how I think about everything.
Context engineering: Prompts are instructions to the model
POP: Prompts ARE the program
SKILL. md isn't documentation
↓
It's the executable code
↓
Written in natural language
↓
Executed by the LLM
The prompt is simultaneously:
Human-readable docs
Machine-executable instructions
The "source code" of the behavior
Documentation and implementation collapse into one artifact.
Innovation #6: The Context/Execution Duality
Context engineering focuses on managing tokens.
POP reveals there are two orthogonal state spaces:
Epistemic Context (what Claude knows)
Conversation history
Loaded instructions
Domain knowledge
Deontic Context (what Claude can do)
Tool permissions
Model selection
Capability grants
Skills modify BOTH simultaneously and keep them synchronized.
This is architectural—security and knowledge managed together.
Innovation #7: Progressive Compilation Model
Context engineering mentions progressive disclosure.
POP formalizes it as a compilation pipeline:
Phase 1: DISCOVERY (scan all SKILL. md frontmatter)
~50 tokens per skill
↓
Phase 2: LINKING (semantic match to user intent)
Symbol resolution
↓
Phase 3: LOADING (full prompt loaded)
~2000-5000 tokens
↓
Phase 4: EXECUTION (JIT resource loading)
Variable, on-demand
Each phase has different token budgets and optimization strategies.
This is compiler thinking applied to natural language programs.
Innovation #8: Natural Language Type Systems
Traditional programming:
function(input: PDFDocument): ExtractedText
POP introduces semantic contracts:
## Input Contract
- Must be PDF file
- Must be readable
## Output Contract
- UTF-8 string
- Metadata included
## Behavior Contract
- Will validate first
- Will handle multi-column layouts
You get the benefits of types (clear interfaces, composition rules) without the rigidity.
Soft typing through semantic understanding.
Innovation #9: Versioned, Distributable Context
If prompts are programs, they need software lifecycle management:
my-skill/
├── SKILL. md
├── scripts/
├── references/
└── LICENSE.txt
Version: v1.2.0
Distributed via: Repositories
Composed with: Other skills
Context engineering treats context as ephemeral session state.
POP treats it as packageable artifacts you can version, share, and compose.
Imagine npm for AI behaviors. That's the vision.
Innovation #10: Declarative State Management
Traditional programming:
self.mode = "pdf_mode" # Imperative
POP:
User: "Process this PDF"
System: "Loading PDF skill"
# State exists in the dialogue itself
The conversation history IS the state machine.
Benefits:
Auditable (read history = see all transitions)
Resumable (reload conversation = restore state)
Inspectable (humans see what mode AI is in)
Self-documenting
Innovation #11: Token Budget as First-Class Resource
Context engineering: "Context is limited"
POP: "Treat tokens like memory in resource-constrained systems"
Token Budget Allocation:
├── System: 500 (fixed)
├── Tools: 1000 (fixed)
├── Skills: 50/skill (variable)
├── Active Skill: 2000 (loaded)
├── History: 10k (grows)
└── Tool Results: 25k (capped)
Optimization:
- Lazy evaluation (progressive disclosure)
- Garbage collection (unload completed skills)
- Pagination (chunk tool outputs)
This is systems programming thinking for context.
Innovation #12: Prompt-Level Composability
The final piece: Modular composition patterns
# Base (abstract interface)
---
name: document-processor
---
Common workflow
# Concrete (implementation)
---
name: pdf-processor
extends: document-processor
---
PDF-specific behavior
# Composed (aggregation)
---
name: document-suite
includes: [pdf, docx, xlsx]
---
You can build:
Inheritance hierarchies
Mixin patterns
Interface/implementation separation
DRY principle for prompts.
Notice the pattern across all 12 innovations?
Each one takes a concept from traditional software engineering and asks:
"What would this look like if the 'compiler' was an intelligence that understands rather than parses?"
Control flow → Semantic dispatch
Variable scope → Temporal context
Type systems → Natural language contracts
State management → Dialogue as state
Resource management → Token budgets
Module systems → Skill composition
This is why POP goes beyond context engineering:
Context engineering = Best practices for managing tokens
POP = A complete programming paradigm with:
* Meta-architecture
* Lifecycle management
* Type systems
* Compilation model
* Distribution mechanisms
* Resource optimization
* Compositional semantics
It's not context engineering 2.0.
It's a theory of executable natural language.
Here's what each discipline gives you:
Prompt Engineering:
"How to write good prompts"
Context Engineering:
"How to manage what the model sees"
Prompt-Oriented Programming:
"How to build programmable systems where natural language IS the code"
The abstraction level is fundamentally different.
What does this mean for you?
If you're building AI systems, these 12 patterns are design primitives you can use:
Need better tool routing? → Semantic dispatch Context getting polluted? → Temporal scoping Users confused? → Dual-channel communication Building complex workflows? → Skill composition
Each pattern solves a specific architectural problem.
Here's my prediction:
In 2 years, every major AI platform will have something like skills:
Scoped, temporary context
Meta-prompts that load other prompts
Versioned, distributable prompt packages
Natural language composition
Not because it's trendy.
Because these patterns are structurally necessary for building reliable agentic systems at scale.
But here's what I'm still figuring out:
What's the right "assembly language" for POP?
We have high-level (natural language prompts) and mid-level (traditional code).
But what's the primitive instruction set for prompt-based systems?
What are the "opcodes" of semantic computing?
Context engineering tells you what to put in the window.
Prompt-Oriented Programming gives you a programming language for it.
One is a practice. The other is a paradigm.
The difference matters.
@karpathy @lateinteraction @dexhorthy
3
12
1,613

13 Sep 2025
Xojo 2025 has a built in pdfDocument class. If you have that, do you really need #DynaPDF Starter Edition? Find out all the benefits of getting DynaPDF Starter Edition with Omegabundle for #Xojo 2025. Build better #PDF generation into your next #app bit.ly/4mgvwH8

1
6
152

12 Sep 2025
Xojo 2025 has a built in pdfDocument class. If you have that, do you really need DynaPDF Starter Edition? Find out all the benefits of getting DynaPDF Starter Edition with Omegabundle for #Xojo 2025. Build better #PDF generation into your next #app bit.ly/4mgvwH8

1
5
121
9 Aug 2025
Create PDF with special characters
If you like to create PDF documents in Xojo, you may just try the built-in PDFDocument class.
But if you need more unicode support, you can use DynaPDF and the Starter version is included with OmegaBundle for #Xojo.
mbsplugins.de/archive/2025-0…

3
101

12 Jul 2025
pdfrxのPdfDocument/PdfPage/PdfImageというローレベルのAPIをDartでも利用可能なようにパッケージを分ける作業をしているのだけど、dart:uiが名前に反してFlutterに依存していて、どうしよう・・・って思ってたんだけど、一か所を除いて、Flutter側で拡張メソッドとして実装しなおすだけで済むことがわかって安心している。
1
3
364

20 Dec 2023
Your security is our priority 🔒
We are ISO 27001 certified, the international standard for information security management systems.
Contact us now: hubs.li/Q02cF-DL0
#Ebundle #EBinder #PDFDocument

74

4 Dec 2023
The factory method in Python is based on a single function that's written to handle our object creation task. 🐍🚀
We execute it, passing a parameter that provides information about what we want. As a result, the object we wanted is created.
Interestingly, when we use the factory method, we don't need to know any details about how the resulting object is implemented and where it is coming from.
The underlying idea here is that, when developing code, you may instantiate objects directly in methods or in classes. While this is quite normal, you may want to add an extra abstraction between the creation of the object and where it is used in your project.
You can use the Factory pattern to add that extra abstraction. Adding an extra abstraction will also allow you to dynamically choose classes to instantiate based on some kind of logic.
Before the abstraction, your class or method would directly create a concrete class. After adding the factory abstraction, the concrete class is now created outside of the current class/method, and now in a subclass.
Imagine an application for designing houses and the house has a chair already added on the floor by default. By adding the factory pattern, you could give the option to the user to choose different chairs, and how many at runtime. Instead of the chair being hard coded into the project when it started, the user now has the option to choose.
Adding this extra abstraction also means that the complications of instantiating extra objects can now be hidden from the class or method that is using it.
This separation also makes your code easier to read and document.
-----------
📌 The key Terminologies here
- **Concrete Creator**: The client application, class or method that calls the Creator (Factory method).
- **Product Interface**: The interface describing the attributes and methods that the Factory will require in order to create the final product/object.
- **Creator**: The Factory class. Declares the Factory method that will return the object requested from it.
- **Concrete Product**: The object returned from the Factory. The object implements the Product interface.
-----------
📌 Let's see an example WITH and then WITHOUT the **"Factory design pattern in Python"**
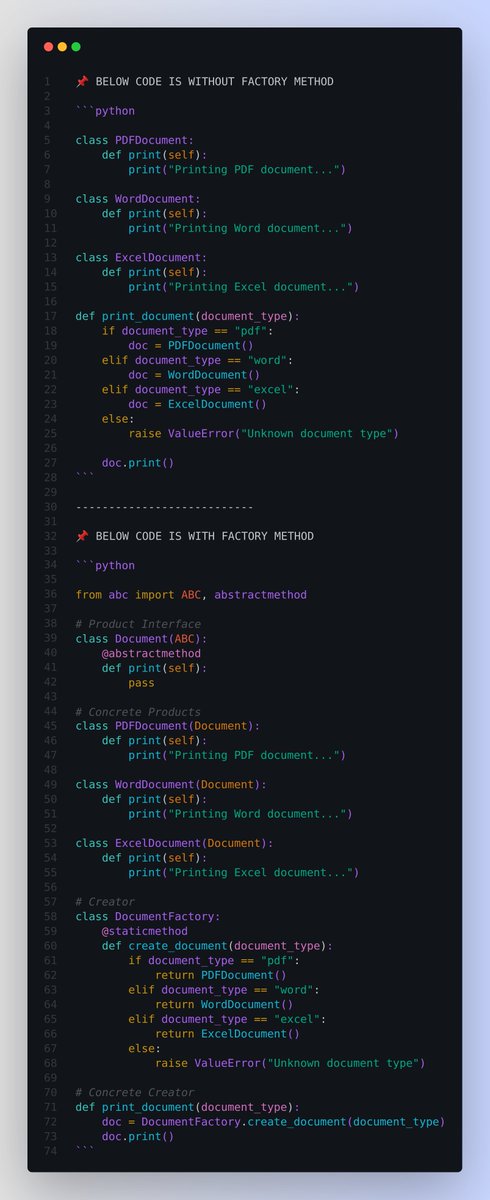
📌 Code without Factory Design Pattern
Consider a simple scenario where we have a system that deals with different types of documents. Each document type can be printed, but the way they are printed might differ.
📌 BELOW CODE IS WITHOUT FACTORY METHOD
```python
class PDFDocument:
def print(self):
print("Printing PDF document...")
class WordDocument:
def print(self):
print("Printing Word document...")
class ExcelDocument:
def print(self):
print("Printing Excel document...")
def print_document(document_type):
if document_type == "pdf":
doc = PDFDocument()
elif document_type == "word":
doc = WordDocument()
elif document_type == "excel":
doc = ExcelDocument()
else:
raise ValueError("Unknown document type")
doc.print()
```
📌 The code WITHOUT FACTORY METHOD has a few issues:
📌 If we want to add a new document type, we have to modify the `print_document` function. This violates the Open/Closed Principle, which states that software entities should be open for extension but closed for modification.
📌 The creation logic of documents is mixed with the printing logic in the `print_document` function. This makes the function less cohesive and harder to maintain.
📌 Refactored Code with Factory Design Pattern
To solve the above issues, we can use the Factory design pattern.
📌 Here's how the CODE WITH FACTORY METHOD pattern solves the issues:
📌 We've separated the creation logic from the printing logic. The `DocumentFactory` class is responsible for creating documents, while the `print_document` function is only responsible for printing.
📌 If we want to add a new document type, we only need to modify the `DocumentFactory` class. This makes our code more maintainable and adheres to the Open/Closed Principle.
📌 The `Document` class (Product Interface) ensures that all document types (Concrete Products) have a `print` method. This provides a consistent interface for the client code (Concrete Creator).
📌 The `DocumentFactory` class (Creator) abstracts away the creation logic, allowing the client code to remain unchanged even if the underlying creation logic changes.
2
5
442
22 Aug 2023
Last night, we officially kicked off ILTACON 2023 with the Ultimate Tailgate party!
For anyone else who would like to discuss our product, come visit us at booth 316.
#Ebundle #EBinder #PDFDocument #LegalTech #CloudSolutions #ILTACON2023 #ILTACONUltimateTailgateParty

2
98

22 Aug 2023
At the moment you could only render the contents to a Bitmap and then save the Bitmap in the PDF using PdfDocument developer.android.com/refere…
1
420
Want to make sure you have kept up with what's new in Xojo's PDFDocument? The blog has a tag for that!
Read tips on using all the new features intoduced blog.xojo.com/tag/pdf/
#softwaredeveloper #PDF #devlife
3
182
Want to make sure you have kept up with what's new in Xojo's PDFDocument? The blog has a tag for that!
Read tips on using all the new features intoduced blog.xojo.com/tag/pdf/
#softwaredeveloper #PDF #devlife
1
4
180
Want to make sure you have kept up with what's new in Xojo's PDFDocument? The blog has a tag for that!
Read tips on using all the new features intoduced blog.xojo.com/tag/pdf/
#softwaredeveloper #PDF #devlife
2
210
Want to make sure you have kept up with what's new in Xojo's PDFDocument? The blog has a tag for that! blog.xojo.com/tag/pdf/
#devlife #indiedev
3
179
Want to make sure you have kept up with what's new in Xojo's PDFDocument? The blog has a tag for that! blog.xojo.com/tag/pdf/
#devlife #indiedev
3
Additional features added to PDFDocument in Xojo's latest release - more control while using PDFForm plus improvements to dealing with TOC indexes! Learn more: bit.ly/3s8R7aN #PDF #indiedev
1
1