
Joined December 2022
- Tweets 13,883
- Following 3,449
- Followers 35,999
- Likes 35,463
557 Photos and videos








Omar Khattab retweeted

Jun 11
Happy to share that our recent work, TACHIOM, got integrated into the PyLate ecosystem!
arxiv.org/pdf/2604.28142
(@SilvioMartinico, @fmnardini, @rventurini_ )
Jun 11

Whether you are GPU poor or GPU rich, today's release of PyLate has something for you!
GPU maxxers: MaxSim kernels greatly speed up training while lowering the memory requirements
CPU enjoyers: TACHIOM enables lightning fast multi-vector indexing and search directly on CPU

3
11
3,453
Omar Khattab retweeted

Jun 11
Whether you are GPU poor or GPU rich, today's release of PyLate has something for you!
GPU maxxers: MaxSim kernels greatly speed up training while lowering the memory requirements
CPU enjoyers: TACHIOM enables lightning fast multi-vector indexing and search directly on CPU
3
26
122
10,681
Omar Khattab retweeted

Jun 10
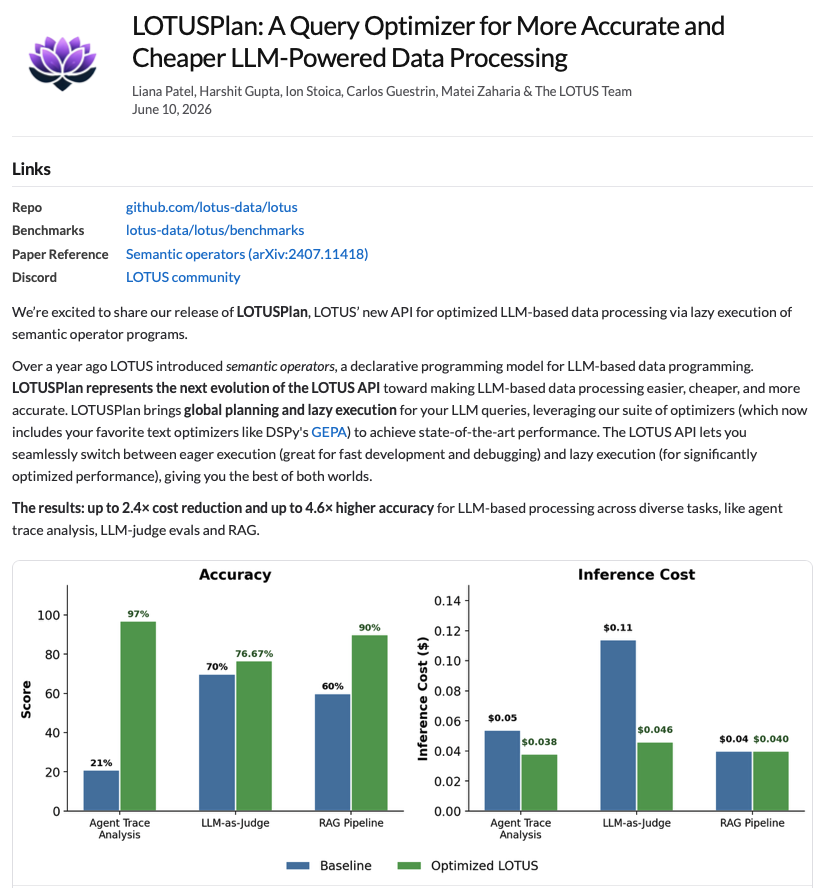
🚀 Beyond excited to share we're releasing LOTUSPlan, a new API & optimizer for higher performance LLM-powered data processing, from our team at Berkeley & Stanford.
LOTUS now lets you write your LLM-based queries and optimize them for up to 2.4× lower cost and 4.6× higher accuracy for tasks like, agent trace analysis, LLM-judge evals, RAG, document extraction and deep research.
✨Checkout our our new blog: liana313.github.io/blog/lotu…
🧵
9
21
80
16,966
Omar Khattab retweeted

Jun 10
wait this is so cool LOL
in theory if we hillclimb RLMs maybe they become incentivized to launch code blocks in this way

Jun 10

What happens when multi-agent systems stop relying on a central “controller” agent? Can agents coordinate by sharing results directly with each other?
Introducing Decentralized Language Models (DeLM): we let agents coordinate asynchronously through a shared context. Agents claim tasks from a queue and write back compact, verified results as they finish, making progress visible to all workers without requiring a main agent to merge, filter, and rebroadcast it.
New paper with @azaliamirh!
11
18
221
28,913
Omar Khattab retweeted

Jun 10
Computing max similarity (scoring step of colbert, colpali) on gpus can be optimized and this is what @tonywu_71 did.
It's available in PyLate, it will accelerate both training and inference of multi-vector models
pip install "pylate[lik]"
so cool, from @tonywu_71 and @Aurelien_L_
Jun 10

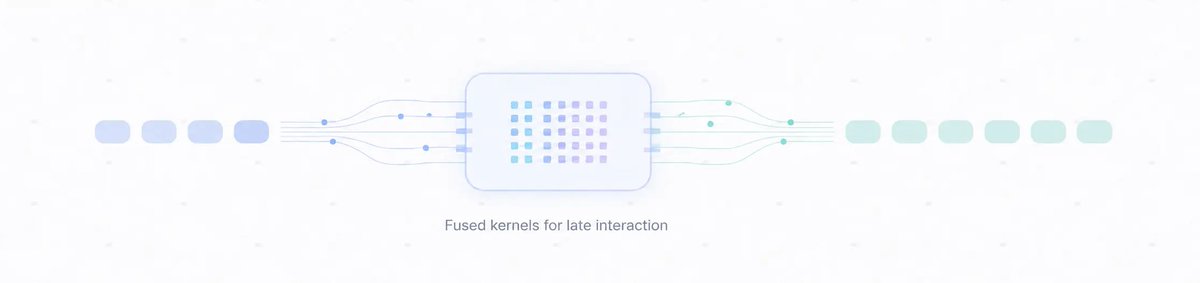
Very excited to release late-interaction-kernels (LIK): fused Triton kernels for MaxSim, the scoring step behind ColBERT, ColPali & LateOn. 🚀
Numerically equivalent to PyTorch at a fraction of the memory, with day-0 support in PyLate & colpali-engine. (1/N 🧵)
2
27
3,136
Omar Khattab retweeted

Jun 10
Very excited to release late-interaction-kernels (LIK): fused Triton kernels for MaxSim, the scoring step behind ColBERT, ColPali & LateOn. 🚀
Numerically equivalent to PyTorch at a fraction of the memory, with day-0 support in PyLate & colpali-engine. (1/N 🧵)
6
11
62
7,978

Jun 9
“agents kicking off agents as a way to better manage context”
“nested” language models
“depth=N”
neat :-)
Jun 9

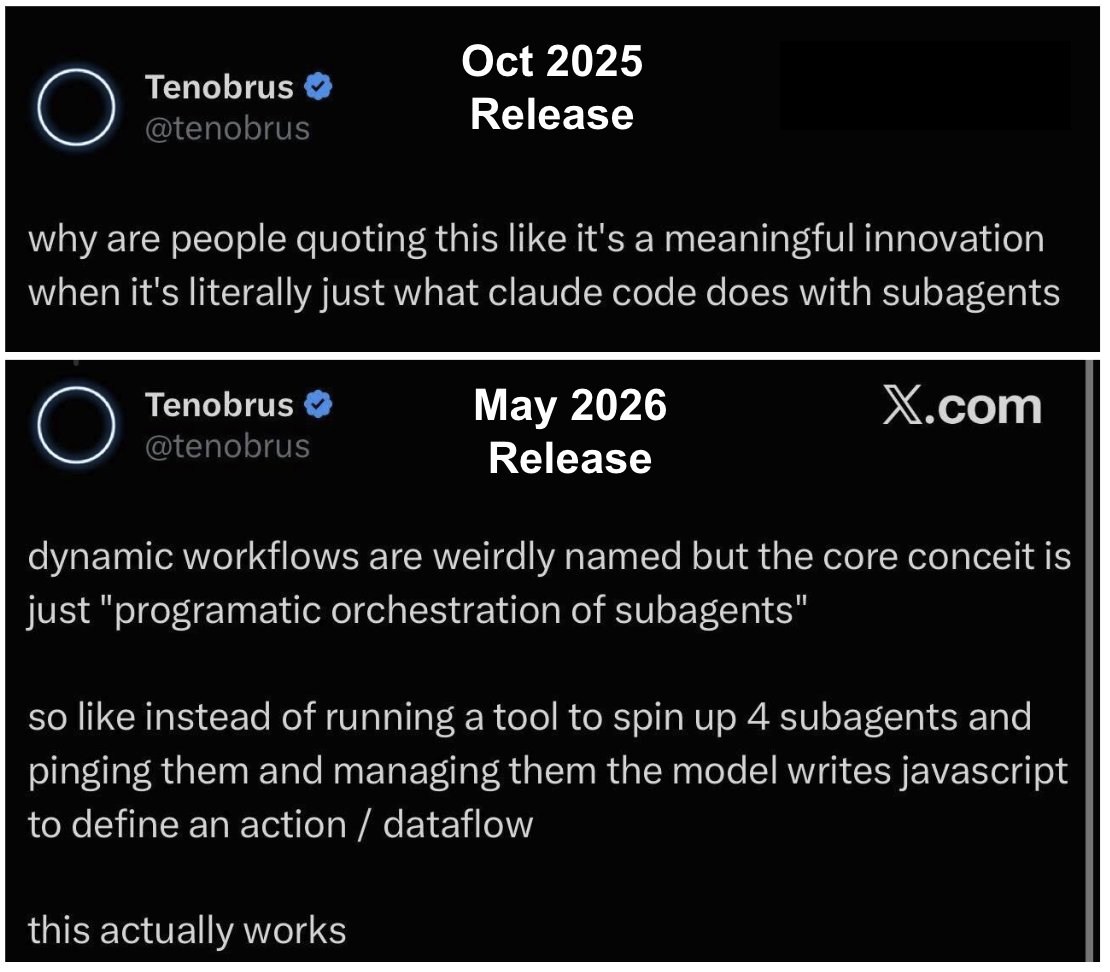
Just landed nested subagent support in Claude Code
Starting to experiment more with agents kicking off agents as a way to better manage context. Capped at depth=5 to start, going out in today’s release.
Lmk what you think!
18
8
164
20,091
Omar Khattab retweeted

Jun 9
New blog post: On-Policy Distillation — Promise, Pitfalls, and Prospects.
OPD combines on-policy rollouts with dense teacher supervision.
But it is not a free lunch.
I discuss three failure modes and introduce our new paper.
louieworth.github.io/blog/op…

9
43
305
19,392
Jun 8
as usual from @yoonholeee, this is extremely well-written and a great way to organize the major arguments in this space

4
31
323
45,463


🎉 Happy to see @mattjustram joining @mixedbreadai and @rpradeep42 joining @DbrxMosaicAI - grep is all you need? ❌ bm25 is all you need? ❌ both wrong - talent is all you need ✅
5
4
46
4,612
Omar Khattab retweeted

Jun 7
Will just leave this here… dspy.ai/getting-started/prog…
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
3
13
193
40,881
Omar Khattab retweeted

Jun 6
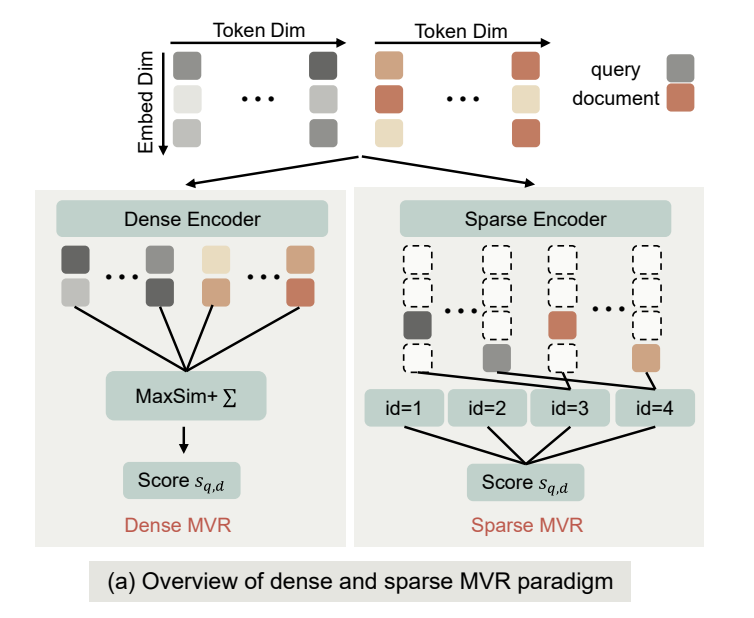
1/👁️ Meet Argus-Retriever: the first late-interaction visual doc retriever where the document representation adapts to the query: D(q).
- 86.0 NDCG@5 on ViDoRe V1 V2 (SOTA open model)
- 📦 1024-dim head, 4.5× smaller index
Jun 4

Argus-Retriever: Vision-LLM Late-Interaction Retrieval with Region-Aware Query-Conditioned MoE for Visual Document Retrieval
Introduces a query-conditioned late-interaction visual document retriever.
📝 arxiv.org/abs/2606.04300
👨🏽💻 github.com/DataScienceUIBK/A…
1
7
52
8,387
Omar Khattab retweeted
Jun 1
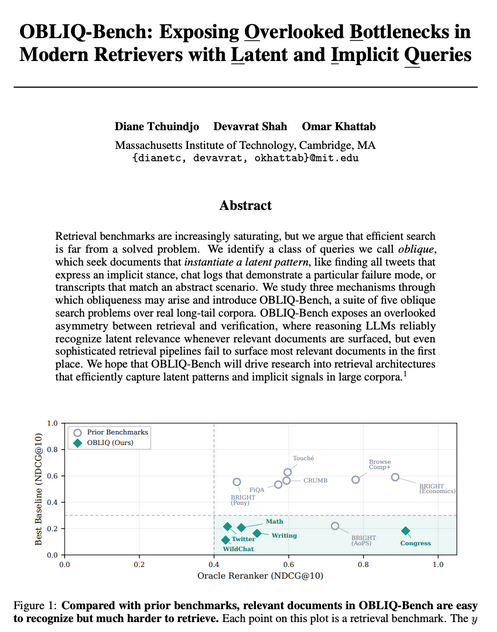
if you're testing a new retrieval model or long-context LLM, it's a waste of your time (and ours...) to report 0.2% gains on the many saturated and expired benchmarks
if you're in that position and looking for way to rescue your great new idea, put it to the test on OBLIQ-Bench

We set out to build a better retriever, so we looked for the hardest IR benchmarks.
For each, we asked how much headroom remained by running oracle reranking with a frontier LLM. Most had little room left!
So we built OBLIQ-Bench to study much harder search queries than before.
10
11
171
25,045
Omar Khattab retweeted
Jun 5
This is the DSPy way.
Prompts are imperfect instructions, always.
Write them yourself as little as possible, but hold them accountable with typing, tests, metrics, and optimizers.
Jun 5

Using agents effectively requires embracing their stochastic nature and setting up a framework for them to reason rather than giving them a pile of rules.
Harness engineering and knowledge base curation does not (and cannot!) rely on all information being pulled into context—and given things like autocompaction over long horizon work, context is constantly getting blitted so you can't really rely on things being in context either.
In general you want to tell agents your expectations on how/when/what type of context they should seek and how the tools in their environment can help them complete their work.
You need to tell the agents what they are working on, what parts of it matter, and how they should approach tasks. Tell them about common tasks for the things you’re working on and where they can learn more about them. Make your agents collapse a prompt they are given into a paved workflow.
12
15
204
20,691
Omar Khattab retweeted

Jun 5
Using agents effectively requires embracing their stochastic nature and setting up a framework for them to reason rather than giving them a pile of rules.
Harness engineering and knowledge base curation does not (and cannot!) rely on all information being pulled into context—and given things like autocompaction over long horizon work, context is constantly getting blitted so you can't really rely on things being in context either.
In general you want to tell agents your expectations on how/when/what type of context they should seek and how the tools in their environment can help them complete their work.
You need to tell the agents what they are working on, what parts of it matter, and how they should approach tasks. Tell them about common tasks for the things you’re working on and where they can learn more about them. Make your agents collapse a prompt they are given into a paved workflow.
17
15
227
58,760
Omar Khattab retweeted

Jun 5
Excited to be speaking about RLMs at this year’s Worlds Fair!
DM if you’ll be in SF for it
@a1zhang I may be hitting you up for some spicy takes 👀

3 weeks left til @aidotengineer world's fair!
if you want to get on this year's map of top ai engineering companies, theres a few spots left
we are sold out of:
- presenting sponsors
- model lab sponsors
- platinum sponsors
- gold sponsors
the big spots left are for the official afterparties - welcome reception, networking night, and world cup quarterfinal bundles
if interested - drop a note to sponsorships@ai.engineer detailing size/scale of interest
(below is 2025, we are recruiting 2026 now)
if you are attending - BOOK YOUR HOTELS BY TMR AS THE ROOM BLOCK DISCOUNT EXPIRES TMR

2
2
19
4,508
Omar Khattab retweeted

Jun 5
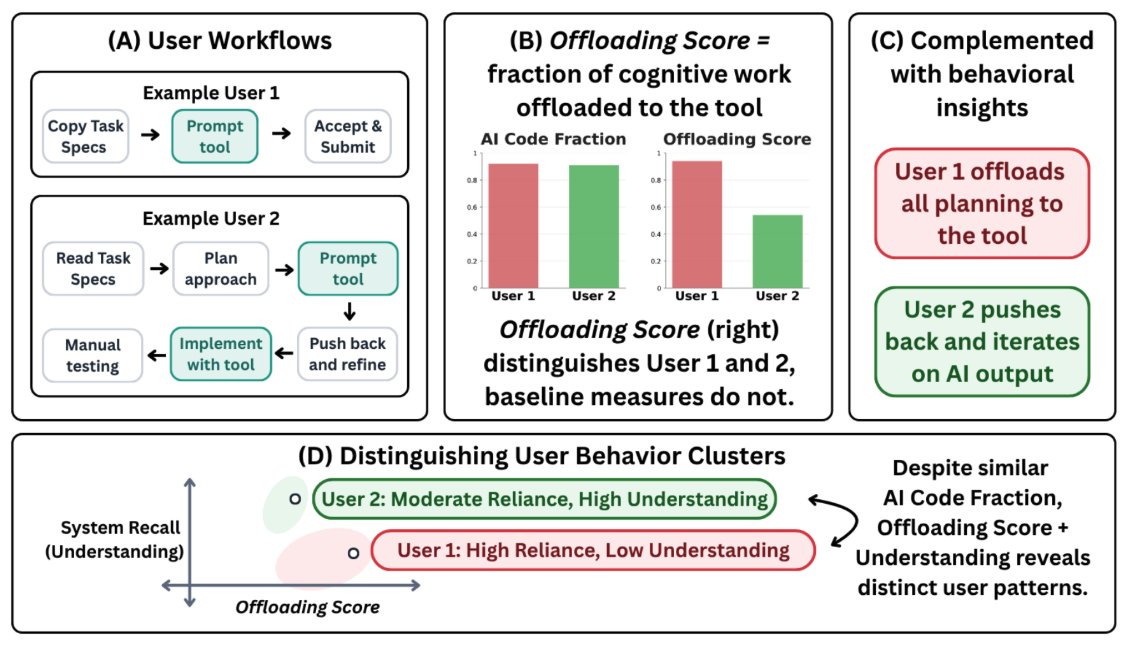
We propose a new way to quantify AI overreliance: the Offloading Score 🧐 @vishakh_pk
It measures the fraction of cognitive work you hand off to AI 🤖 via simulating how you'd have done each step without AI, then counting the steps the AI saved. It works directly from interaction traces (keystrokes, screenshots), so it's reusable across many tools!!

People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)

3
23
169
45,992
Omar Khattab retweeted

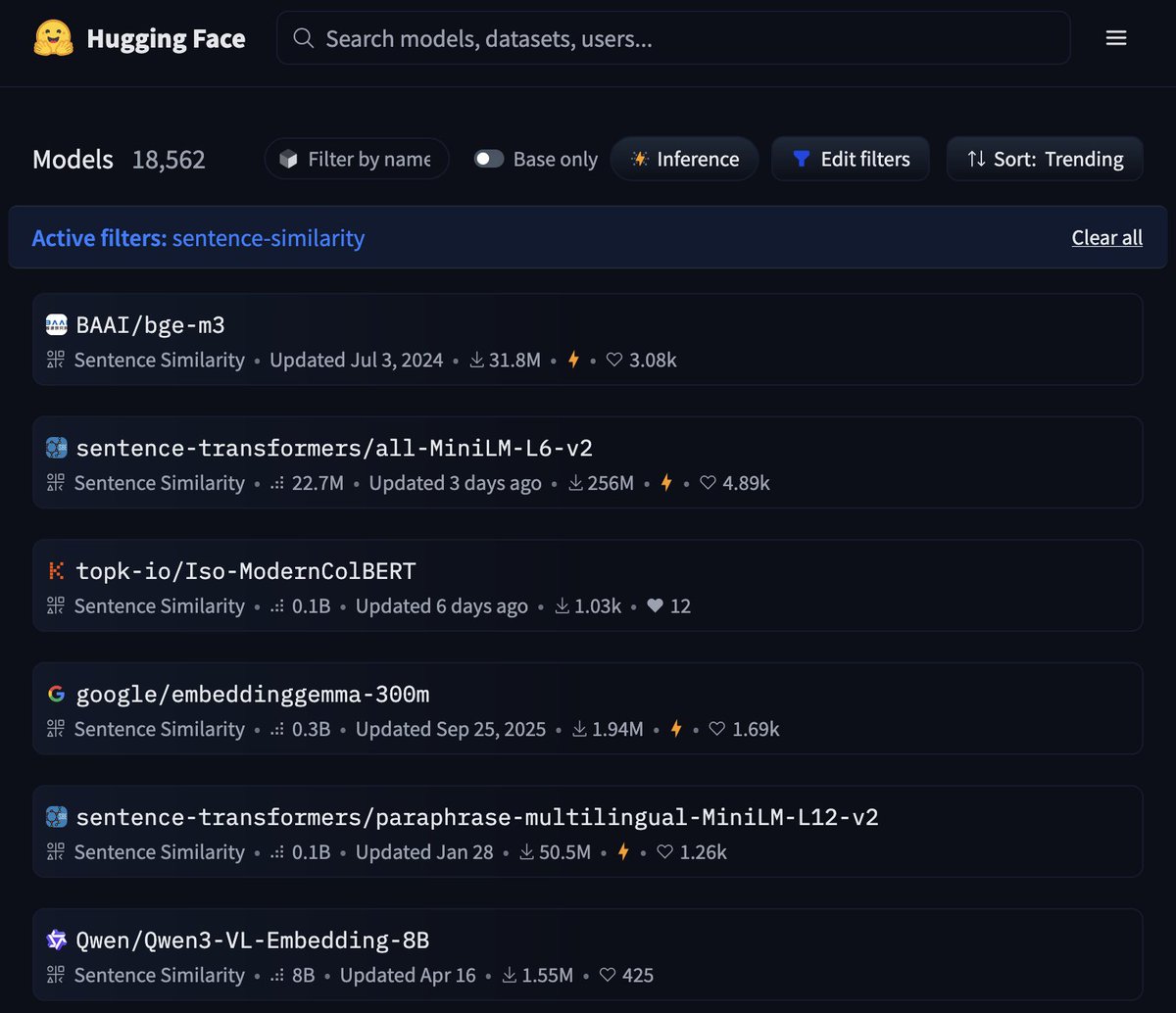
Jun 4
Iso-ModernColBERT by @topk_io is now top3 trending sentence-similarity model on 🤗 Hugging Face. To see it next to such big names - I'm speechless :D
1
4
24
2,401