
2 Jun 2025
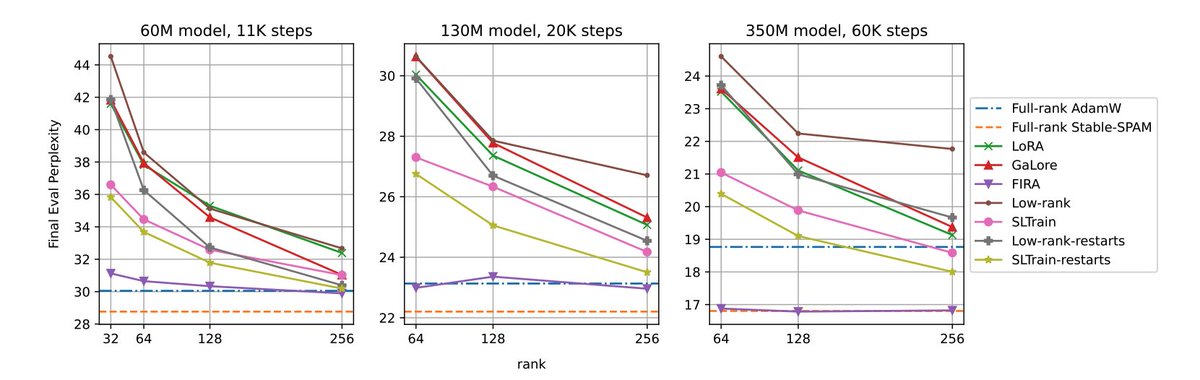
🧵2. Restoring full-rank boosts performance.
E.g., SLTrain (sparse low-rank) > pure low-rank.
FIRA (Hadamard-injected high-rank updates) > GaLore.
🎯 High-rank update paths are crucial for strong performance in low-rank pertaining.
1
2
156
2 Jun 2025
Nice benchmarking paper: Scalable Parameter and Memory Efficient Pretraining for LLM: Recent Algorithmic Advances and Benchmarking. arxiv.org/pdf/2505
A long-needed benchmark of memory-efficient pretraining algorithms (LoRA, GaLore, FIRA, SLTrain, etc.) under the low-rank training wave. Glad someone finally did this!
💡 They performed extensive wandb hyperparameter sweeps and reported best settings per method — a huge plus for fair benchmarking.
However, they didn’t fully tune learning rates per method, which in my experience is critical, especially for low-rank training.
🧵Here are their key takeaways and my thoughts:
3
4
23
4,209

2 Jun 2025
Mumbai locomotives among 32 engines sent to Sri Lanka
Read more: adaderana.lk/news.php?nid=10…
#india #sltrain #railway #lka #srilanka #adaderana #news #lanka #SriLankaNews
3
434
20 May 2025
Investigation underway after elephant killed by train despite recent safety measures
Read more: adaderana.lk/news.php?nid=10…
#elephant #sltrain #lka #slnews #news #adaderana #srilanka

3
444
16 May 2025
Dematagoda railway crossing to remain closed on May 24
Read more: adaderana.lk/news.php?nid=10…
#Dematagodarailway #railway #sltrain #lka #srilanka #adaderana #news #lanka #srilankanews
2
499
9 May 2025
Special train services for long weekend and Vesak festival
Read more: adaderana.lk/news.php?nid=10…
#Vesakfestival #sltrain #lka #srilanka #adaderana #news #lanka #SriLankaNews
1
2
555
30 Apr 2025
Trains delayed due to derailment between Fort and Maradana
Read more: adaderana.lk/news.php?nid=10…
#slrailway #sltrain #lka #slnews #news #adaderana #srilankanews #srilanka
1
2
338
8 Apr 2025
Railway Dept. to operate 10 special trains for New Year
Read more: adaderana.lk/news.php?nid=10…
#railway #sltrain #lka #slnews #news #adaderana #srilankanews #srilanka
1
342
3 Apr 2025
Special train service in place for Sinhala and Tamil New Year
Read more: adaderana.lk/news.php?nid=10…
#railway #sltrain #lka #slnews #news #adaderana #srilankanews #srilanka
1
419
31 Mar 2025
Railway Station Masters withdraw from relief duties in sub-stations
Read more: adaderana.lk/news.php?nid=10…
#railway #sltrain #CGR #lka #srilanka #adaderana #news #lanka #SriLankaNews
3
2
518
17 Mar 2025
Train breaks down causing delays on coastal line
Read more: adaderana.lk/news.php?nid=10…
#sltrain #slrailway #coastalline #lka #srilanka #adaderana #news #lanka #SriLankaNews
418
14 Mar 2025
Trains on coastal line delayed
Read more: adaderana.lk/news.php?nid=10…
#sltrain #railway #lka #srilanka #adaderana #news #lanka #srilankanews
1
1
349
11 Mar 2025
Trains delayed on coastal line
Read more: adaderana.lk/news.php?nid=10…
#slrailway #sltrain #lka #slnews #news #adaderana #srilankanews #srilanka
1
324
10 Mar 2025
Train services on up-country line restored
Read more: adaderana.lk/news.php?nid=10…
#sltrain #railway #lka #srilanka #adaderana #news #lanka #SriLankaNews

1
442
20 Feb 2025
Elephant death toll in ‘Meenagaya’ train accident climbs to 6
Read more: adaderana.lk/news.php?nid=10…
#Elephant #Meenagayatrain #sltrain #lka #srilanka #adaderana #news #lanka #SriLankaNews
1
4
668
7 Feb 2025
Sri Lanka Railways suspends third-class seat reservations on several trains
Read more: adaderana.lk/news.php?nid=10…
#railway #sltrain #lka #slnews #news #srilankanews #srilanka
3
473
27 Jan 2025
Suspect arrested over online train tickets racket granted bail
Read more: adaderana.lk/news.php?nid=10…
#slrailway #sltrain #lka #slnews #news #adaderana #srilanka #srilankanews
1
1
1
488
27 Jan 2025
Another suspect arrested over alleged online train tickets racket
Read more: adaderana.lk/news.php?nid=10…
#sltrain #slrailway #lka #slnews #news #adaderana #srilanka #srilankanews
1
4
534
23 Jan 2025
Online train tickets racket: Two more arrested including railway technical officer
Read more: adaderana.lk/news.php?nid=10…
#slrailway #sltrain #CGR #lka #slnews #news #adaderana #srilankanews #srilanka
2
366
20 Jan 2025
CID launches probe into alleged online train tickets racket
Read more: adaderana.lk/news.php?nid=10…
#CID #sltrain #lka #srilanka #adaderana #news #lanka #SriLankaNews
2
474