
WHO THE FUCK TOOK A BITE OUT OF MY SPECTROGRAM????
1
1

Built a free embeddable widget for Earth's electromagnetic heartbeat 🌍
Live Tomsk spectrogram NOAA Kp Cosmic Energy Score (0–100) today's top community symptoms. Works in any iframe.
→ schumannresonance.today/embe…
#SchumannResonance

4
105

Built an Audio Quality Assessment Space on @huggingface 🎧
It gives a quick technical overview of audio using loudness, noise, dynamic range, clipping, silence, waveform and spectrogram analysis.
Which metric should I add?
HF:huggingface.co/spaces/Aynurs…
#AudioAI #TTS #HuggingFace
6
146

音響實存主義研究所のメンバーシップについて、少し文章を書きました。
DTMを感覚だけで語るのではなく、電気信号・DSP・測定結果として見直すための小さな研究所です。
大きな場所にしたいわけではありません。
PluginDoctorの測定、THD、IMD、Hammerstein、Spectrogram。
そういう観測から、プラグインが実際に信号へ何をしているのかを読みたい人に、静かに届けば十分です。
DTMは電気だ。
note.com/p929
#音響實存主義 #DTM #PluginDoctor #DTMer #信号処理
2
133


Jun 15
We should preserve really special voice notes or voice recordings in audio spectrogram papers ❤️
1
2
55
Jun 15
We probably need to start preserving them in audio spectrogram papers
1
120
BURAKKLNC retweeted

Jun 15
Sigma-MT User Guide, Part 1: Reading the Spectrogram and the Time Frequency Engine
sigma-l.net/p/sigma-mt-user-…

1
1
20
1,210

Jun 15
language models without multimodal support & audio, without slop about Gravitational Waves:
think of it this way. you have someone sitting in the Producer/Engineer chair with a comprehensive body of knowledge of everything that has been written about music theory, production, songwriting, etc -- but the speakers are off, and they can only make changes based on what they see on metering. up until the new dense Gemma models, and earlier Gemini models, audio encoding/decoding as input has largely been experimental. so when talking about models without audio byte-pair encoding training like Gemma's new dense model, we are left with vision and language tokenization, so if it can be conveyed in an image (like a mel spectrogram of a short sample, since images are rescaled down to 1500px-ish for bandwidth on most production APIs, and you will lose spectral information that could be displayed in a TIFF), that's the best the model will get
the models don't have a vague, thunderous understanding of music like detecting gravitational waves. they have the understanding a world-class engineer would have of a song with the metering on and the speakers off. "it looks like there's vocals here which are smooth" because it can see lines in the 2k-5kHz range. if it were post-trained on audio itself it would cut the gap, i.e. models that you can pass audio into natively have no problem understanding music. it's a tokenization issue with the older non-audio models but describing it the way the OP did is ridiculous dilettante wordslop
Jun 15

so thy kind of have synesthesia from our POV
2
1
14
2,820
Jun 15
try feeding an image of a short sample as mel spectrogram into any model with a vision circuit, it even works back to the first Llama 3 models. this will cut the gap between 'models not specifically trained for music' and 'generalized audio engineering space in manifold'
1
28
Chidambara .ML. retweeted

Jun 15
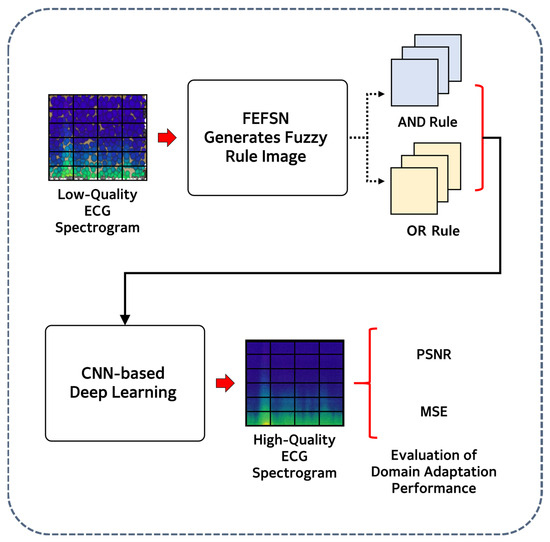
📢 #highlycited paper
📚 Domain Adaptation of ECG Signals Using a Fuzzy Energy–Frequency Spectrogram Network
🔗 mdpi.com/2076-3417/15/24/129…
👨🔬 by Tae-Wan Kim et al.
🏫 Chosun University
#explainableAI #fuzzylogic #machinelearning
2
2
44

Jun 15
nah fuck it i have free will i can say that 35 is the noelle net hp loss in ch2 (90->166->55), it's hidden in d.ogg spectrogram, it's the square root of 1225, 3 rotated is M and 5 flipped is e, Dess is the voice in HLDITHTS (non glowy gaster w/ normal case) and is behind weird rt
1
18

Jun 15
It reminded me that a friend uploaded CD archive in a video in spanish, he even translated the secret codes and the spectrogram of act 1 lmao
1
9
726

Jun 15
The "warm" LED lighting is still blue light. Just look up the power distribution of warm LED lightning on a spectrogram. It's still unnatural and super unhealthy. Your "better alternative" is as misguided as the belief that using less energy will save the planet.
1
3
68

Jun 14
so i was informed theres morse code right before the blue trim fight in the flame ep and so i clip the audio, get the spectrogram from audacity, find a morse code decoder, only to find out it says "abcdefghijklmnopqrstuvw" and its just part of the music
2
11
231
3,110