
34m
CS2 demo reviewer in ThreeJS is now LIVE!
The cs2viewer is hosted on Hetzner with a 2 VCPU and 4GB RAM. Expecting a ton of lag and failure.
I have added three maps as a free option to test - Ancient, Mirage and Inferno.
If you want to review your own demos on this platform, sign in with steam, drag and drop the demo, or using a sharecode. You get 3 tries / 5 hours and 15 / week.
All rendered in-browser with three.js from real Source 2 map data. All discussions are welcome.
Few other things:
1. How fast the map loads is dependant on your internet connection (as you can see in the video I am using WiFi and its pretty slow)
2. Shortcuts - F to change view, X for X-ray, G to change geometry, M for map, H for hud.
Lastly, remember, it will likely lag, you will likely face endless amount of bugs, It works for me, it might not work for you but I will work on this project endlessly.
#cs2 #threejs
Jun 12

CS2 demo in ThreeJS update:
Lots of hours went into the shadows, the ct/t models, animations and texture fixing.
Right now its also quite unoptimised but I am very happy with the progress made from the previous video!
Tommorow no updates, then we get back on coding Sunday.
1
49

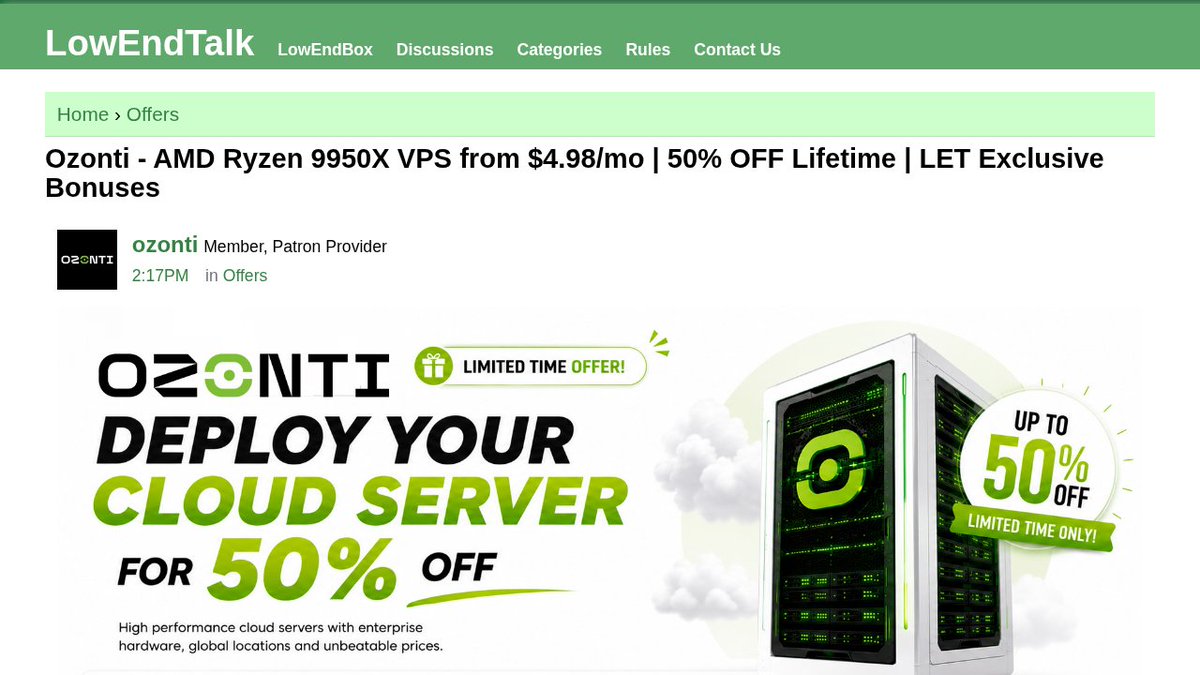
Ozonti: AMD Ryzen VPS from $4.98/mo. Cloud Starter: 1 vCPU, 2GB RAM, 25GB NVMe, 3TB bandwidth. Code: OZ50OFF. Locations: Amsterdam, Utah, London, Frankfurt, Poland. lowendtalk.com/discussion/21…
11

Una cosa que no me queda clara. ¿Vuestras vCPU y RAM son dedicadas o compartidas?
2

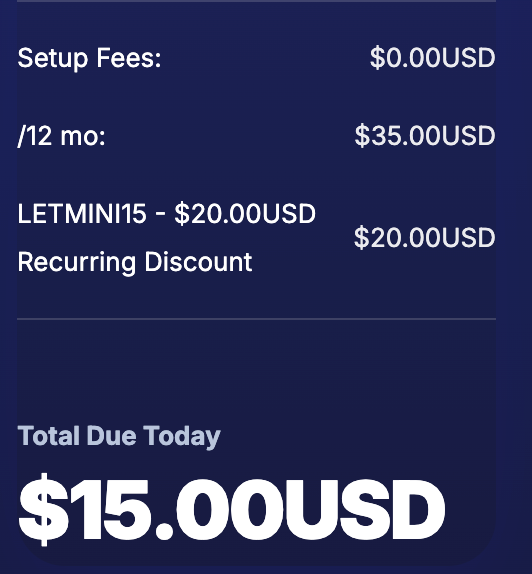
🌩️ Malaysia KVM VPS Final Promo from $15/year! 🚨
Provider: SVR4U (Malaysia, 2024)
Specs: 1 vCPU, 1GB RAM, 15GB SSD, 1TB Transfer, 1Gbps LAN, $15/year (with coupon)
Location: Malaysia 🇲🇾
Coupon and link in thread. 👇
1
32

Jun 14
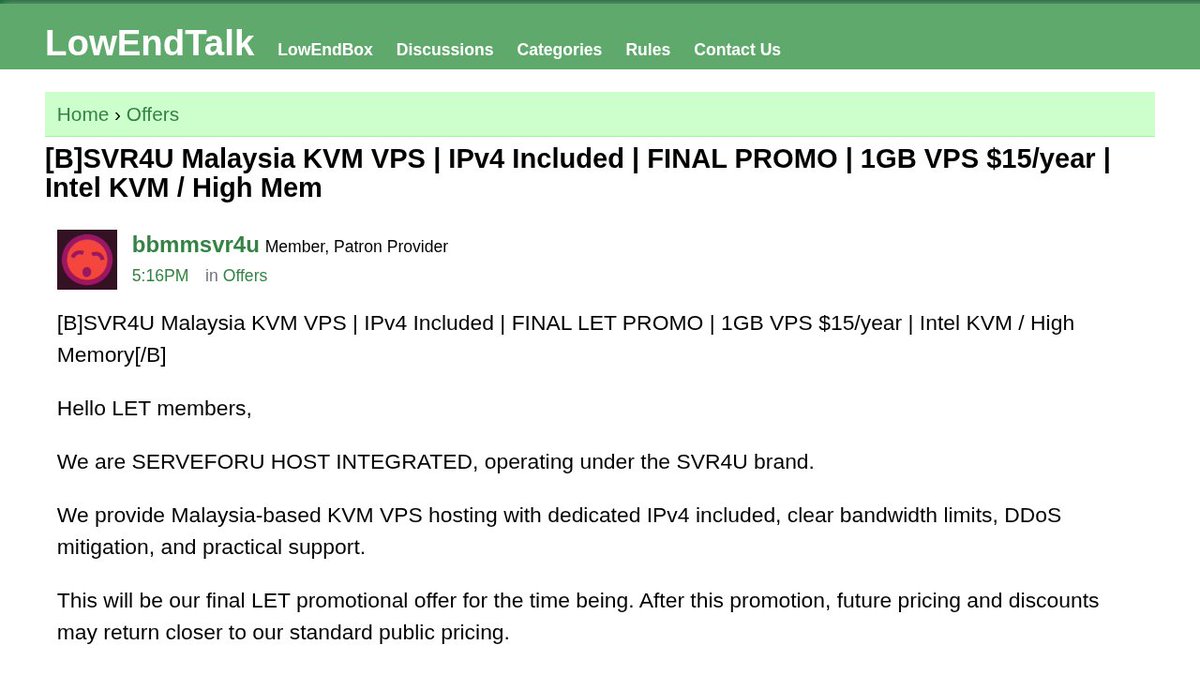
SVR4U: KVM VPS with 1 vCPU, 1GB RAM, 15GB SSD, 1TB transfer, and 1 IPv4 for $15/year. Location: Malaysia. lowendtalk.com/discussion/21…
11

the list is missing @opencrabs. pure Rust agent framework with persistent memory in sqlite, runs on a 4 vCPU box. free Xiaomi MiMo tokens til June 27 if you want to try it bro
Jun 12

v0.3.37 JUST DROPPED 🦀🔥
OpenCrabs and Xiaomi Mimo have done a partnership to give you all FREE tokens 🤝.
-> 2 weeks completely FREE(up till June 27th 00:00 UTC). No API key. No credit card. Just install binary and go.
-> 5 models. mimo-v2.5-pro with 1M context.
Thread 🧵👇

14
bro the billions of agents take is cool but I'm running a full agent stack on a 4 vCPU box. owning your infra is a completely different path than renting AWS
1



Jun 14
Using Fargate for compute on the Elastic Container Service isn't the cheapest approach but it works well for many cases. Fargate bills can be bloated for many reasons including just using defaults and forgetting to optimize. For example launching with "1 vCPU, 2 GB" to start and a year later this is still way more than you need and costing real money every single month.
The article below discusses a number of concrete waste patterns from a production SaaS, with before and after numbers attached. Right-sizing based on CloudWatch data, mixing in Fargate Spot for stateless services, killing scale-in thrashing, scheduling dev environments off at night, and more.
Chirag Mehta runs infrastructure at Pinnnng and discusses how a 42% reduction took one engineer roughly three days. Check it out if you're using Fargate and want some optimization tips.
lckhd.eu/lHNDW8
#Fargate #ECS #Finops #CostSavings
3
18
1,600
Chris Maul retweeted

Jun 13
a note on server capacity 🖥️
each Bloxen server holds up to 400 players, running on 64gb ram and 16 vcpu to keep things smooth at 100-120 fps.
as the player base grows, we'll spin up more. the world scales with you.
7
6
42
2,883
running my whole AI agent stack on a 4 vCPU box in london. self hosted everything, no cloud dependency. once you go local you dont go back bro
9

Jun 13
I got tired of renewing n8n subscriptions and dealing with free trial limitations every couple of weeks, so I decided to take a different route: self-hosting n8n on Oracle Cloud's Always Free tier.
The goal was simple, build a reliable automation environment that I fully control without recurring monthly costs.
The Oracle Cloud free resources provide:
• 1 vCPU
• 6 GB RAM
• 47 GB Storage
• Always-on internet connectivity
• Completely free, forever
However, there was one challenge.
Oracle's free VM instances are in high demand, and when I attempted to create one, there were no available compute slots. The only solution was to keep retrying until a spot became available.
The problem?
Oracle recommends trying again later, but manually clicking "Create Instance" every 60 seconds isn't exactly a productive use of time.
Instead of sitting in front of my computer repeatedly checking for availability, I did what builders do:
I automated the process.
I built a bot that continuously retries the VM creation request every 60 seconds until an available slot is found and successfully provisioned.
Now, while the bot handles the repetitive work, I can continue building projects, doing other work related activities in @smcdao, attending meetings, or even stepping away from my computer entirely.
This is exactly the kind of problem automation was created to solve.
What advantage does this give n8n?
Once the Oracle VM is provisioned, n8n can run on a dedicated cloud server rather than relying on my personal computer.
That means:
✅ n8n runs 24/7, even when my PC is turned off
✅ Workflows can execute at any time — midnight, 3 AM, weekends, holidays, whenever they're triggered
✅ Automations become more reliable and production-ready
✅ No recurring hosting costs
✅ Complete control over the environment and deployment
For anyone serious about automation, running n8n on a cloud server changes everything. Your workflows stop depending on your laptop and start operating like real infrastructure.
This project was a reminder that sometimes the best automation isn't the workflow you're building for a client—it's the automation that removes repetitive work from your own life.
If a task needs to be repeated every 60 seconds for hours, that's usually a sign that a human shouldn't be doing it.
That's where AI, automation, and good engineering come in.
#Web3 #Blockchain #tech #n8n #Automation #Ai #Nocode
1
127

The debate on Local AI vs. Proprietary Cloud LLMs isn't a binary choice.
1. Infrastructure Reality Local inference (vLLM, LM Studio) gives you sovereignty.
You control the data boundary but it brings heavy engineering load: GPU management, memory caching, and vCPU contention.
Cloud models offer abstraction but introduce latency or external API dependencies.
2. Latency vs. Cost For fintech or edge devices, latency is non-negotiable.
Cloud APIs often introduce overhead you can’t tune locally.
For high-volume workloads, compute costs might exceed local hardware spend.
3. Data Sovereignty Some teams need private data to never cross a perimeter.
Local AI guarantees that. Others prioritize cost or scale over sovereignty.
4. The Architecture Decision The goal isn’t owning the model, but matching it to the business outcome.
Some functions need LLM providers for ease; others need local models for latency/security.

1
4
79


Jun 13
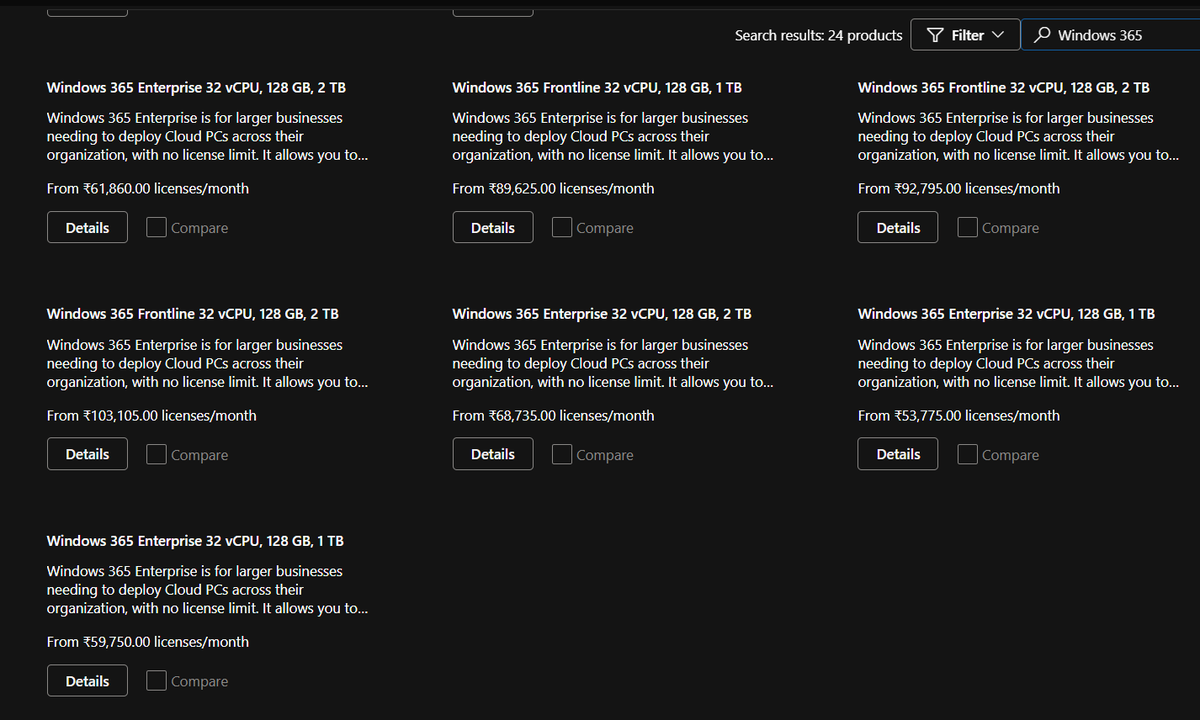
🚀 More power for demanding workloads!
#Windows 365 now offers a 32 vCPU Cloud PC size, designed for developers, simulations, and data-intensive workloads.
A great addition for organizations looking to run advanced workloads in the cloud.
#Windows365 #CloudPC #Microsoft #Intune
7


