
Efficiently loading 500-1000 chunks into a VectorDB typically involves using batch inserts to minimize network overhead and parallel embeddings to speed up the generation of vector representations
1
1
9



Jun 13
So, I started an AI bootcamp in March.
I was an AI rejectionist but I am somewhat more of a believer after getting elbow deep in everything.
The course started with fundamentals doing n8n basic automations and their business needs.
Next up was the business ownership and presenting it to the C-Suite guys.
Finally we rolled into the deep technical stage. Building agents top to bottom using MCP, VectorDB, etc.
I have to say well constructed and planned agents are going to take a lot of jobs off the table. I don’t doubt it at all.
Do I think it’s going to lead to national unemployment? No, I think current trends of unchecked foreign employment is having that effect in the US far more, but I’m not going to get political in this.
Now, the fun part.
AI has Web3 like contests. It’s a super under utilized platform currently and feels like it’s getting into Web3 security in the boom. I’ve already been doing security testing and am planning to sit the HTB cert very soon.
Web3 may have never paid off for me (other than learning Rust) but it did prepare me to seize great opportunities. So overall, while I’m not an AI maxi I am a believer.
25


Jun 11
AWSの箱より、最大の大事な要素は、
投入するデータがRAGのVectorDBにとって如何にきれいにできるかです。
世の多くの案件は、何文字毎に切って分割して投入する雑さな手法でデータを大量にしてカバーしていますが、ここをきれいにできると精度が跳ね上がるので。
1
29
Jun 11
私だとAWSのBedrockでRAGやったときは、1日で検証環境構築して、RAG用のDBデータをJSONに変換してVectorDBに投入を数回繰り返して、検索用のプログラムを書いてAgentに使わせるように設定して、それなりに90%ぐらいはOKのQA機能を5日で作ったという体感。
1
40


Jun 11
▼概要
AIエージェントの記憶基盤や知識グラフ構築に特化した、Rust製のグラフ・ベクトルデータベース「HelixDB」が注目を集めている。AIアプリ開発に必要な各種データ管理を単一のプラットフォームに統合する。
▼ポイント
・グラフとベクトルのデータモデルを主軸に、KV・ドキュメント・リレーショナルデータもサポート
・用途別にリレーショナルDBやベクトルDBを使い分ける従来の構成から、単一基盤への統合を実現
・RustやTypeScriptのDSLによるクエリ記述に対応し、ビルドなしでの動的実行が可能
・対話型の初期化コマンドを搭載し、AIエージェントと連携したアプリ全体の自動構築をサポート
▼使い所
社内データと連携するAIエージェントの記憶基盤構築や、複数のDBを組み合わせる複雑なAIアプリケーション開発の簡略化。
#HelixDB #VectorDB
URLはリプ⬇️

1
4
1,617
1. 记忆模块的数据存在哪种介质上?
Agent 的记忆一般分为三层。
第一层是短期记忆(Short-term Memory)。
主要保存当前会话上下文,例如最近几十轮对话、当前任务状态、工具调用结果等。
通常存储在:
Redis
内存 Cache
LangGraph State
特点是读取速度快,但生命周期短。
第二层是长期记忆(Long-term Memory)。
保存用户画像、偏好、历史行为等结构化信息。
例如:
用户在日本工作
用户正在开发 Agent 产品
用户偏好 Python
通常存储在:
PostgreSQL
MySQL
MongoDB
第三层是语义记忆(Semantic Memory)。
用于跨会话召回历史经验。
例如:
用户一个月前讨论过「简历 Agent」。
今天提问:
如何优化模板理解?
系统需要知道这两次对话其实属于同一个项目。
这类数据一般会:
Embedding
存入向量数据库
例如:
Milvus
Qdrant
OpenSearch
Chroma
现代 Agent 的 Memory 实际上就是:
Redis PostgreSQL VectorDB 的组合。
Jun 10

今天来看腾讯的开发工程师的初面题。
Q1 - Q9, Q12我感觉这是整张卷子最值钱的部分。面试官非常懂行,他关注的是大模型在实际业务中的控制流和记忆管理。
先说Q1, Q2, Q5。
大模型的 Token 是要算钱且有长度限制的。怎么存用户的聊天记录?
怎么在跨系统、跨时间的情况下,还能让大模型记得用户是谁、之前说了什么?
这是做智能助手最核心的痛点。
Q3, Q4, Q6, Q12。终于开始考架构了。
面试官在考查你对大模型调用框架的底层认知。问 FSM和 LangGraph,说明腾讯需要用强控制、确定性高的流式架构去规范大模型的胡言乱语。
问为什么选 ReAct 而不是纯 Chain,估计是在看面试者对Reason-Action与死板工程流水线之间平衡点的理解。
Q7, Q8,毫无疑问的Skill。
这通常是大型 Agent 框架,比如字节的 Coze、腾讯自己的类似产品里的核心概念,考查的是能不能把复杂的工具调用封装成标准化、可复用的插件。
Q10、Q11,还有Q13。
这应该算是传统后端的知识。
工厂模式、本地部署与配置管理以及后台怎么搭建,是在淘汰那些只会调 OpenAI 接口,但连基本的后端架构、高可用、设计模式都不懂的包装型选手。
腾讯的团队,要的是能直接上手写生产环境代码的熟练工。
Q14、Q15,没啥可说的,算法基本功。
最长有效括号考Stack或者动态规划,挺考验逻辑严密性。
股票交易,也属于LeetCode 经典系列,我经常刷,典型的动态规划、贪心算法。经典的大厂核心算法大礼包,虽然和 AI 没直接关系,但用来刷掉代码基本功不过关的人非常有效。
现在大厂要的 AI 工程师,既要懂大模型的特性,比如Token限制、Agent流控、RAG挂载这些,又要是一个扎实的传统后端高手。
如果能把前 12 道关于 Agent 架构和记忆管理的题解释得既深又透,哪怕后面项目稍微薄弱一点,腾讯那边也会觉得你对大模型应用开发是有深度思考的。

1
1
185

Jun 10
ChatGPT has a short attention span. To give it a permanent, searchable memory, tech companies use VectorDB.
Traditional databases search for exact words. Vector databases search for meaning by calculating the literal geometric distance between ideas.
linkedin.com/company/ilmenoo…

12
Jun 10
技術者としては、LLMにVectorDBを検索してもらうより、自分で直で検索させろといいたくなることが多いので、人類SQLくらいは必修の世界になってほしい。
90



Jun 9
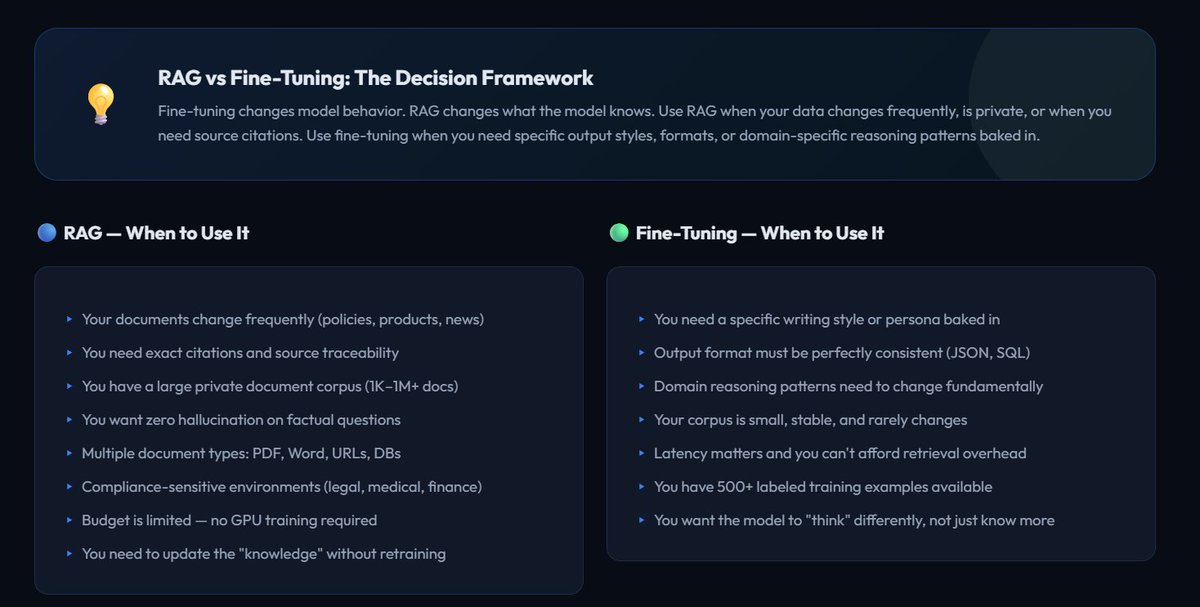
Exploring the Part - 9 of RAG & VectorDB.
lets, take a look on brief comparission of fine tuning and RAG.
#AI #RAG #BuildInPublic #AITools #Productivity
13

Jun 9
[09/06, 01:31] hyperlog Von den Sümpfen zu den Sternen: Dnalabs shows 680 facial landmarks, 455 landmarks are central European, remainder are rna associate health params they do not network without direct anomaly detection, the idea here is to create a full 90% measurement for what was missed and the true bioprint
[09/06, 01:36] hyperlog Von den Sümpfen zu den Sternen: From this bioprint I can figure out the serious ssp associations from one figure of Elliott wave theory and influence .. then important lack of weighting... this means those weights are resharded not from anomalies but from experimental association so hyperlog.agency/labx/ runs through 1million tests enhances the findings through quant24.ch begins to associate the anthropological habitation the galleries of fortitude and magnifying 🔎 these open chasepoints... outrun? Are we outrunning the past ways across myriads of intelligence beams .. each kafkaesque each an engine of 50 x star delta vectordb associates ... these must cancel model collapse on fpga for quant24.ch to ensure q# is used through overcaml usage for strict overhead until machine saturation in ramdisk q sense.. begin engineering the fpga using gerber365.ch pick and place virtual machine create the fpga pcb customised specifically for 30 hop genius factors inside of predictive Elliott referential sensorimotor feedback from monadic results after 6 /loops improve by stochastic modelling the 2bit radaruhr.ch exosensori tiny llm.c snowballing lora nack to dl380 server 1tb ramdisk spooling 140b capacitance snowballing llm.c from purest formatted local data on phone in termux hitting agi intuition in swarm of swarms for fallen requests across 50 logical endpoints from unabliterated anti security guardrail tokens to cf -y and tu -p and rsa -256 and 2fa - aes^2 overcaml.. elegant.
72
Jun 9
@karpathy[09/06, 01:31] hyperlog Von den Sümpfen zu den Sternen: Dnalabs shows 680 facial landmarks, 455 landmarks are central European, remainder are rna associate health params they do not network without direct anomaly detection, the idea here is to create a full 90% measurement for what was missed and the true bioprint
[09/06, 01:36] hyperlog Von den Sümpfen zu den Sternen: From this bioprint I can figure out the serious ssp associations from one figure of Elliott wave theory and influence .. then important lack of weighting... this means those weights are resharded not from anomalies but from experimental association so hyperlog.agency/labx/ runs through 1million tests enhances the findings through quant24.ch begins to associate the anthropological habitation the galleries of fortitude and magnifying 🔎 these open chasepoints... outrun? Are we outrunning the past ways across myriads of intelligence beams .. each kafkaesque each an engine of 50 x star delta vectordb associates ... these must cancel model collapse on fpga for quant24.ch to ensure q# is used through overcaml usage for strict overhead until machine saturation in ramdisk q sense.. begin engineering the fpga using gerber365.ch pick and place virtual machine create the fpga pcb customised specifically for 30 hop genius factors inside of predictive Elliott referential sensorimotor feedback from monadic results after 6 /loops improve by stochastic modelling the 2bit radaruhr.ch exosensori tiny llm.c snowballing lora nack to dl380 server 1tb ramdisk spooling 140b capacitance snowballing llm.c from purest formatted local data on phone in termux hitting agi intuition in swarm of swarms for fallen requests across 50 logical endpoints from unabliterated anti security guardrail tokens to cf -y and tu -p and rsa -256 and 2fa - aes^2 overcaml.. elegant.

28
Jun 9
@karpathy From this bioprint I can figure out the serious ssp associations from one figure of Elliott wave theory and influence .. then important lack of weighting... this means those weights are resharded not from anomalies but from experimental association so hyperlog.agency/labx/ runs through 1million tests enhances the findings through quant24.ch begins to associate the anthropological habitation the galleries of fortitude and magnifying 🔎 these open chasepoints... outrun? Are we outrunning the past ways across myriads of intelligence beams .. each kafkaesque each an engine of 50 x star delta vectordb associates ... these must cancel model collapse on fpga for quant24.ch to ensure q# is used through overcaml usage for strict overhead until machine saturation in ramdisk q sense.. begin engineering the fpga using gerber365.ch pick and place virtual machine create the fpga pcb customised specifically for 30 hop genius factors inside of predictive Elliott referential sensorimotor feedback from monadic results after 6 /loops improve by stochastic modelling the 2bit radaruhr.ch exosensori tiny llm.c snowballing lora nack to dl380 server 1tb ramdisk spooling 140b capacitance snowballing llm.c from purest formatted local data on phone in termux hitting agi intuition in swarm of swarms for fallen requests across 50 logical endpoints from unabliterated anti security guardrail tokens to cf -y and tu -p and rsa -256 and 2fa - aes^2 overcaml.. elegant. Predict habitual psychographic bar graph reports on food intake exercise regularity and excels and top aquarianism or other specific high intake types learning near zero shot instant uncover ancestral traits on healing superfood types currently missing in facial proportion dilation anomaly detection scientifically backed research overcaml hallucinations checker no fluff
15
