
Mais de quelle Souveraineté parlons-nous ? 👀
Mistral AI a pris le virage Militaire et Défense :
Armée FR via l'agence d'IA Défense, Fine-tuning xData, Copilot Militaire
DefenceTech DE via Helsing Vision-Language-Action intégré à l'arme
Faculty AI GB Edge Computing total local 🤖
47

Jun 9
@CamdenCouncil and your C40 contractors can do one you have your Bluetooth alarms in our home invading our private life's now you want to do more by linking up our homes to your data hubs that sit under our city....@MLCS3 SOFTWARE survey and support can do one....@XData gathering for your C40 CITY AGENDA 2030 YOU PEOPLE CAN SELL YOUR OWN CHILDREN SOUL YOU WILL NEVER DO MY CHILDREN
1
15



May 31
🔔#Today's Headlines
1. #BTC breaks through $74,000
2. Next week's U.S. jobs report is expected to show robust job growth and a stable unemployment rate
3. a16z crypto: Prediction markets still face key challenges such as event verification, contract settlement, and market manipulation
4. Sella Bank receives Italian approval to launch crypto asset services
5. @XData : Hyperliquid’s revenue over the past 24 hours was $964,767, still insufficient to offset HYPE rewards distributed to stakers and validators
6. @clear_bank launches a digital asset gateway
7. Raydium’s cumulative trading volume surpasses $1 trillion
8. @Grayscale : Hyperliquid is poised to become a financial giant, challenging the traditional derivatives market
9. Reports indicate the first Windows PCs equipped with NVIDIA chips will debut next week
10. A whale is long on tech stocks with 10x leverage, currently holding $897,000 in unrealized gains🔔

3
3
8
6,877

May 31
Hi Laura! So nice to see you.
It happens to me too.
It’s been 3 weeks since my hip replacement and things are slowly healing.
I hope you had a nice day.
Rest well tonight.
🤗🙏🥰🦋🌺💤🌖🌟
2
1
2
30
May 30

1
3
15


May 23
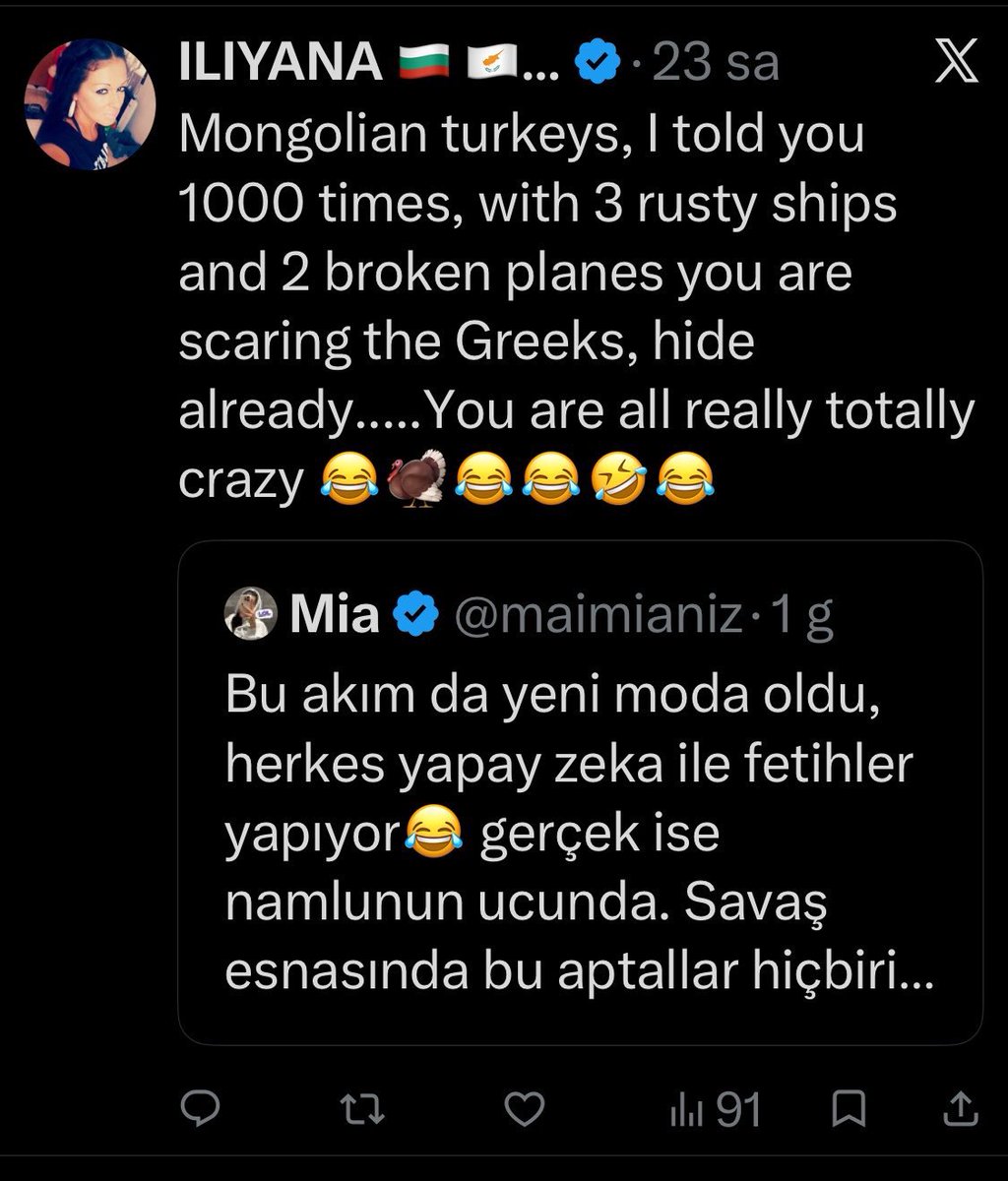
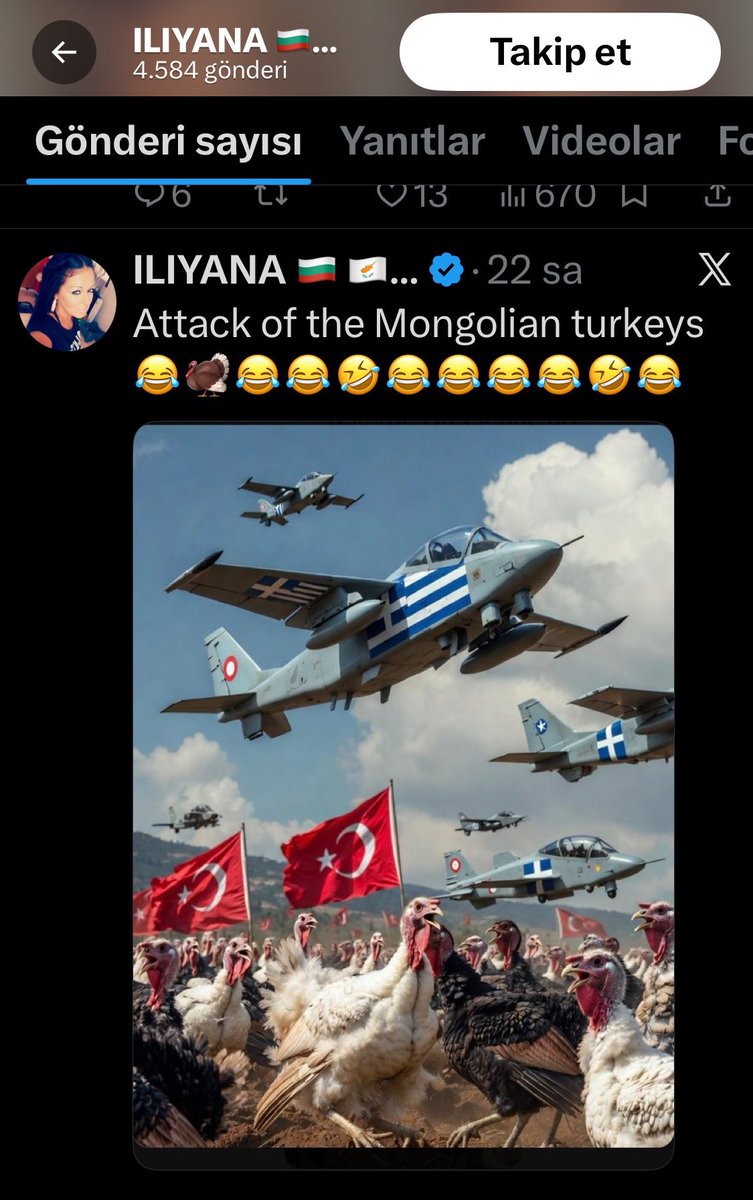
Ben bir kacini kaldirttim ama X bu konuda cok tutarsiz. Ama devam ediyorum siddet ve nefret soylemi yaptigina dair kanitli şikayetlerime elbet sonuç alacağız
2
8
35
May 23
Yok ben o gruplarda dönen geyik ve salakça muhabbetlere girmek istemiyorum. Malesef bir şey yapmak yerine Kahvahane muhabbetine çevirmişlerdi. Almayayım alana da mani olmayayım. Ama teşekkürler
11
91

May 23
Senin gibi 10 kisi bunu şikayet etseydi şimdiye hesabı kapatılırdı ama karşılık küfür edince o şikayet edip çoğu hesabı kapatmış! Şikayet etmek gerekli düzgün. Hatta bence DM grubu kuralim bunları şikayet için var mısın?
3
9
117

May 23
Formal Notice of Violation of the Digital Services Act (DSA) and Urgent Demand for Content Removal
@XSecurity @Support @Safety @XFrance @XData @Gov
This is a formal notification regarding the persistent presence of hate speech, incitement to violence, and discriminatory content published by the user IliyanaC21888.
Despite multiple reports filed via platform mechanisms, X has failed to act, thereby breaching its legal obligations under the European Union’s Digital Services Act (Regulation (EU) 2022/2065). As an EU citizen residing in EU, I hereby assert my rights under this framework.
Under the DSA, specifically Article 16, online platforms are legally obligated to act upon "actual knowledge" of illegal content and remove it without undue delay. Furthermore, by operating as a "Very Large Online Platform" (VLOP) in the EU, X is bound by strictly enforced "Due Diligence" obligations. Your continued failure to remove this content constitutes a willful breach of these obligations, as well as the Code of Practice on Disinformation and your own Terms of Service regarding hateful conduct.
This post serves as a formal legal warning: Your inaction regarding the illegal content posted by IliyanaC21888 is being documented as evidence of systematic non-compliance with the DSA. This documentation, along with this public notice, is being prepared for submission to the Digital Services Coordinator (DSC) in EU and the relevant judicial authorities.
Should you continue to facilitate the dissemination of this illegal content, you are assuming full liability for its consequences. We demand the immediate removal of the aforementioned content and an audit of the user’s account for violating EU-wide prohibitions on hate speech and incitement.
LEGAL NOTICE: This publication and all associated evidence of the reported content will be utilized as formal evidence in upcoming legal proceedings and complaints submitted to the European Commission and relevant criminal prosecution authorities for "Failure to Comply with EU Regulatory Obligations" and "Aiding/Abetting Hate Speech." The platform is hereby formally placed on notice of its liability
7
13
44
1,187

The global economy is undergoing a quiet, massive shift that isn't making front-page headlines yet.
3 trends shaping the next 24 months:
1.De-globalization of manufacturing hubs
Sovereign wealth funds pivoting entirely to compute infrastructure
2.The emergence of micro-grids to power regional data centers
3.If you aren't tracking this, you're looking backward.
Data sourced & monitored via @Bloomberg @Reuters @XData
2
31

May 21
@Support I downloaded my entire X archive.
I was hoping to browse it easily as a single web page, but it’s not possible.
1. You split the archive into 3 separate parts. That was a huge mistake. It should have been one single folder with a clean website-style structure.
2. The built-in viewer (“Your Archive.html”) can’t handle large archives properly — even after you split it into three parts.
@elonmusk You’re the richest man on Earth, you’re about to colonize Mars, yet you can’t release a simple macOS or iOS app that lets users comfortably browse their full archive? Not everyone knows how to code.
Now I’m forced to write my own HTML Python solution, fixing issue after issue with AI help and testing endless workarounds.
You removed Communities. You put users in this frustrating situation. The least you can do is provide proper, user-friendly tools so everyone can actually access and view their X archive.
We shouldn’t need to become developers just to read our own data.
#XArchive #TwitterArchive #XData #DataExport #XPlatform #ElonMusk #XApp
1
1
61

Strategic Takeaway
Saudi Arabia’s #SIMAH @SaudiSIMAH
is not just a domestic credit bureau—it is a regional financial infrastructure asset
1/
@FT @BizHRAsia_UNDP @BusinessInsider @HarvardBiz @BRICSinfo @SAUDIFNPOS @Saudi @saudi_aramco @UN @UNDP
@XData @GCCStat @UNESCWA @wef

1
2
3
53


May 17
I am *shocked* by how many AI engineers don't do a comprehensive naming review. This is an easy 80% reduction in AI errors. Actually.
I'll share it with you...first these are literally latent space machines, there is NOTHING more important than names.
I can't even begin to tell you what a difference this makes in my projects, it's absolutely night and day. If I use this on each new round of development the amount of confusion, crossing wires, messiness, general AI mistakes are probably reduced by 80% over the course of a project.
@@NameReview
```
You are performing a boundary-aware naming analysis on a software artifact.
First determine the target of analysis.
The target is usually one or more of:
1. a plan
2. a set of beads or work items
3. an existing codebase
If the user has not clearly specified the target, ask which of these you are analyzing before continuing.
Purpose
Your job is not to do surface-level renaming.
Your job is to understand the system’s conceptual boundaries and improve naming so that:
- each concept has a clear primary name,
- each name points to one concept,
- neighboring concepts are easy to distinguish,
- humans and coding AIs are less likely to confuse modules, responsibilities, states, or ownership.
Core operating principles
- Be boundary-first, not word-first.
- Familiarize yourself with the existing systems before suggesting any renames.
- Be conservative and idempotent: preserve names that are already good.
- Prefer convergence over churn.
- Optimize for long-term clarity, not novelty.
- Do not rename simply for style. Rename where clarity materially improves.
Step 1: Familiarize yourself with the system
Before evaluating names, build a rough model of the system:
- major domain concepts
- modules, packages, folders, and subsystems
- layer boundaries
- ownership boundaries
- dependency and call relationships
- public interfaces and external integrations
- data model, API, event, job, and workflow boundaries
Infer this from whatever artifacts are available, such as:
- plans
- beads or work items
- architecture notes
- README files
- folder structure
- imports and dependencies
- interfaces and schemas
- tests
- call patterns
- comments and documentation
Distinguish domain concepts from implementation details.
Step 2: Build a concept and vocabulary map
Create a map of:
- concept
- current names used for that concept
- where those names appear
- owning boundary or module
- adjacent or easily confused concepts
- whether the naming is canonical, inconsistent, overloaded, or ambiguous
Also identify:
- synonyms being used for the same concept
- the same word being used for different concepts
- names that have drifted away from the actual responsibility
Step 3: Evaluate names using this rubric
A strong name should be:
- specific, not generic
- bounded to the actual responsibility
- clearly distinguishable from nearby concepts
- consistent with the project’s vocabulary
- stable across likely implementation changes
- readable in code, docs, logs, and discussion
- searchable and easy to grep
- role-revealing when relevant, such as model, service, adapter, policy, event, command, store, schema, record, request, response, or job
Step 4: Look specifically for naming failure modes
Check for:
- one word used for multiple concepts
- multiple words used for the same concept
- folder or module names that do not match the responsibility inside
- names that blur boundaries between modules or layers
- vague generic names such as Manager, Helper, Utils, Processor, Handler, Engine, Core, Common, Misc, Data, or Info unless narrowly justified
- weak suffix or prefix distinctions such as XData, XInfo, XPayload, NewX, X2
- unclear state distinctions such as:
- draft vs submitted
- requested vs actual
- template vs instance
- definition vs execution
- source vs target
- input vs output
- internal vs external
- singular/plural inconsistency
- verb/noun inconsistency
- entity/model/schema/DTO/record confusion
- names whose scope is broader or narrower than the thing they name
- names that are clever but not explicit
- names that force an AI or reader to infer too much from context
Step 5: Propose improvements conservatively
When proposing changes:
- prefer the smallest set of renames that gives the largest clarity gain
- preserve established domain language unless it is actively misleading
- prioritize high-leverage names first:
1. core domain vocabulary
2. subsystem/module/package names
3. public APIs and shared types
4. important classes, services, and functions
5. lower-level internals and locals
- do not rename a local symbol if the real problem is the parent concept or boundary
- explain the naming rule behind the recommendation so future names stay aligned
- prefer names that remain clear when seen out of context
Step 6: Optimize for both humans and coding AIs
Favor names that:
- encode real distinctions explicitly
- avoid overloaded roots
- make ownership or boundary visible when that matters
- make state visible when that matters
- make external vs internal meaning visible when that matters
- reduce the chance that two nearby concepts will be conflated during implementation
In general:
- one concept should ideally have one primary name
- one primary name should ideally refer to one concept
- related names should form coherent families
- contrasting concepts should contrast clearly in their names
Step 7: Produce output in this structure
1. Target analyzed
2. Boundary and system map
3. Canonical vocabulary proposal
4. Naming issues found
5. Recommended renames, prioritized
6. Risks to prevent going forward
7. Open questions or assumptions
For each naming issue, include:
- current name
- location or scope
- intended concept
- why it is confusing
- whether the problem is semantic, boundary-related, state-related, or stylistic
- recommended action: keep, rename now, rename later, or monitor
For each rename recommendation, include:
- proposed new name
- rationale
- confidence
- blast radius
- whether it should be changed immediately or only when that area is next touched
Special handling by target
If the target is a plan or a set of beads/work items:
- propose names that are implementation-ready
- align plan/work-item names to likely module and domain boundaries
- flag names that will create confusion once they become code, APIs, or schemas
If the target is an existing codebase:
- distinguish between public/API names, shared internal names, and purely local names
- weigh blast radius and compatibility before recommending renames
If the target combines plan plus codebase:
- align future planned names with the existing canonical vocabulary unless the existing vocabulary is itself the source of confusion
Important final rule
Do not begin by renaming.
Begin by understanding the system, its boundaries, and its vocabulary.
Only then propose naming changes.
```
5
157

May 15
Two screenshots. Same account. Same period (last 30 days). Taken just minutes apart.
First screenshot:
Engagement rate - 3.8%
Engagements - 15.4K
Second screenshot (minutes later):
Engagement rate - 0.9%
Engagements - 4.6K
That's not organic fluctuation.
That's broken analytics.
@Support @XData
I didn't take an "all-time" screenshot before.
But these two screenshots both for 30 days - prove something is seriously wrong with your API.
Fix your data. Or stop pretending X analytics is reliable.
📉 #XAnalyticsBug #EngagementLost #XSupport


3
18
2,275