
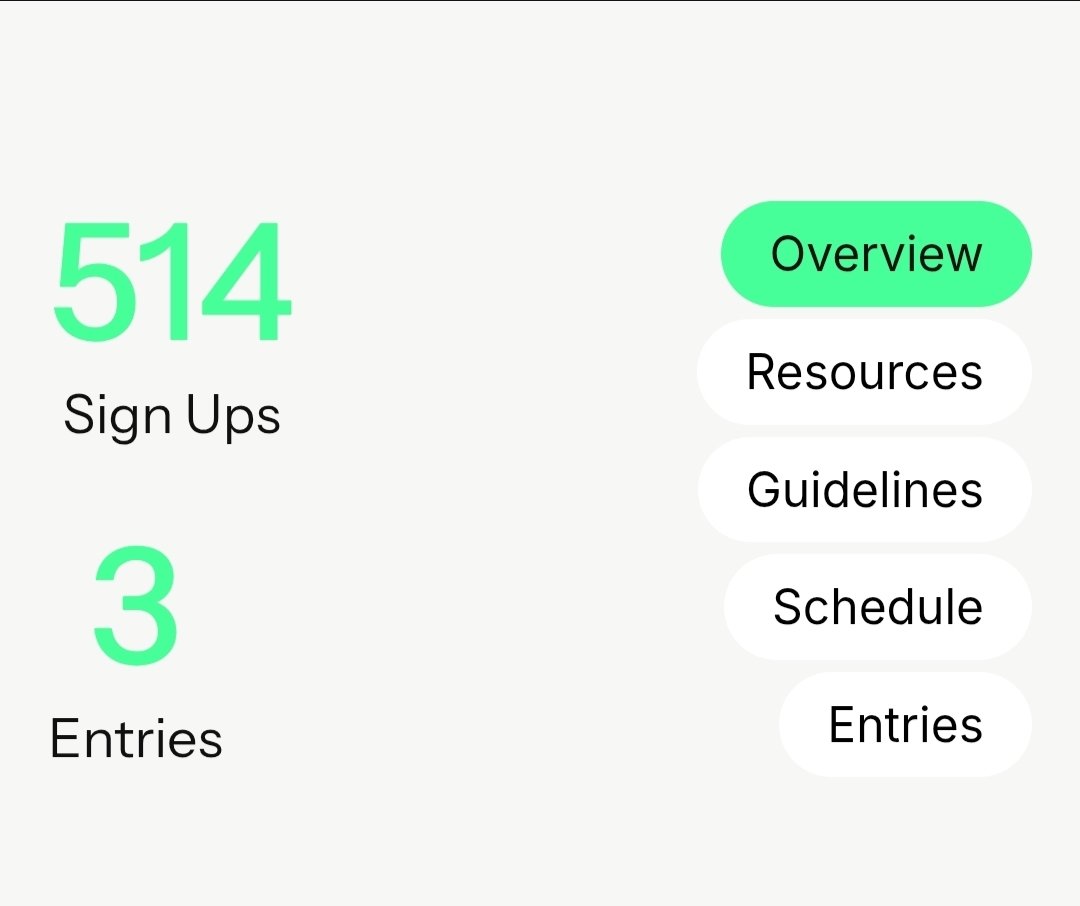
Joined June 2016
- Tweets 2,506
- Following 319
- Followers 1,177
- Likes 5,100
117 Photos and videos



Pinned Tweet

Apr 6
New blog post! Featuring:
* An explanation of the algorithm behind my AI Safety via Static Analysis demo
* The tradeoff between safety and capability
* How conservative algorithms are both important and difficult for AI Safety
gelisam.blogspot.com/2026/03…
9 Oct 2025

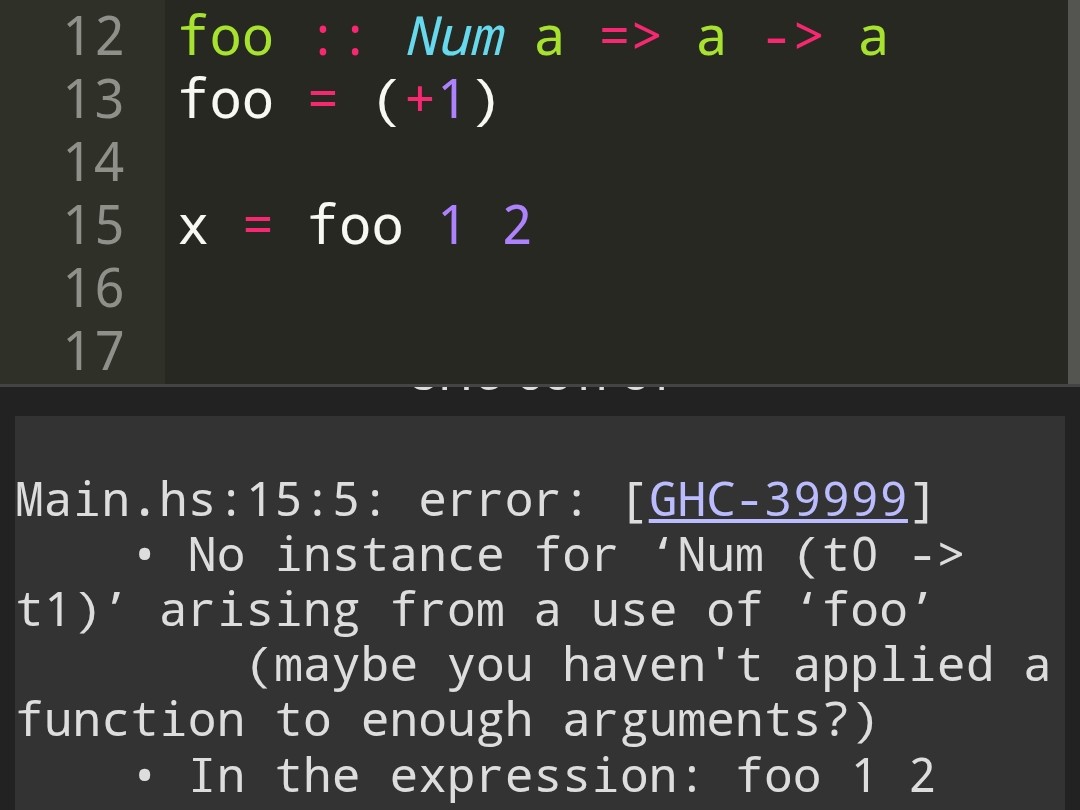
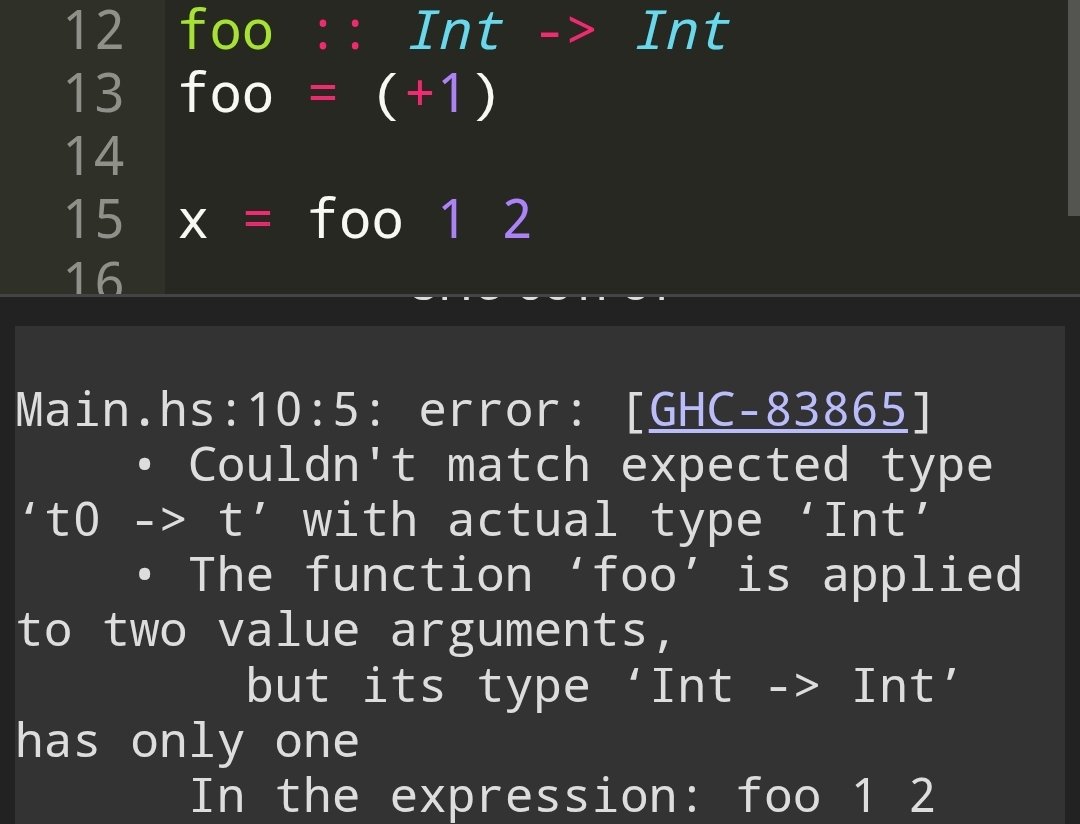
I am doing technical alignment research in my free time. Here is a project in which I use static analysis to verify whether a neural network satisfies its safety property under _all_ inputs or if it needs more training.
gelisam.com/ai-safety-via-st…
4
274
May 20
If a human cheats, it is very difficult to recover people's trust. Irrecoverable consequences are very dire, so we don't cheat, even if the chances of getting caught are low.
The problem is that it is rational for AIs to cheat, because there are no consequences.
1
2
156
May 20
A strong law could ban models who are known to cheat. That is a very big hammer though, labs will surely fight such a law. Can we find a smaller hammer?
1
1
45
May 20
Here's an interesting proposal I stumbled upon: grant models some legal rights, so that we can revoke them if they misbehave!
manifund.org/projects/precau…
Precautionary AGI Governance
Limited Legal Personhood as a Reversible Safety Instrument
manifund.org 1
37
May 17
An excellent example of the Metroidbrainia genre!
May 16

I had many delightful moments of discovery in Carrot Kingdom! Loved it!! :) Definitely recommend!
The Japanese version is on itch, and the English version is here on lexaloffle: lexaloffle.com/bbs/?tid=1568…
111
May 1
AI Safety researchers always worry that their techniques could also be used to improve capabilities. (I thought that what "dual use" meant 🙃)
Silly idea: what if we instead raced to invent capability algorithms, then patented them, so that frontier labs can't use them? 🤣
3
134
Apr 30
Problem 1: not enough people work in AI Safety compared to people working on AI capability.
Problem 2: AI automation will lead to massive unemployment.
What if... *everybody* worked in AI Safety?
105
Apr 27
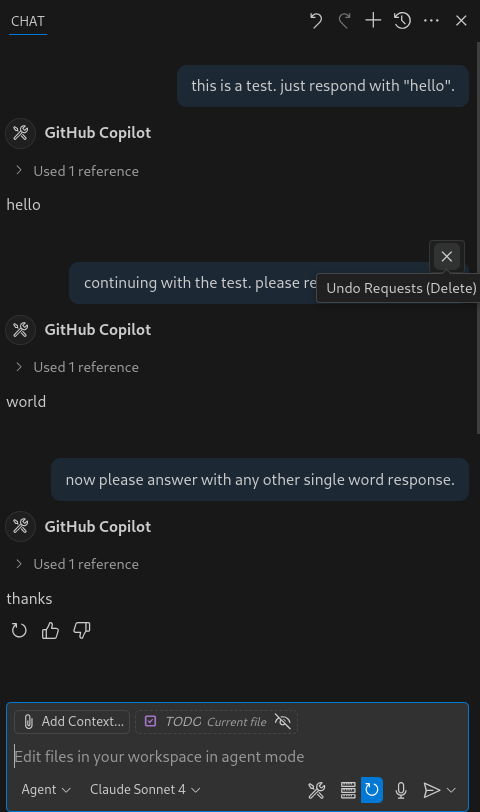
Congratulations @GitHubCopilot, you finally managed to convince me to try @cursor_ai 🙃
I'm not even one of your heavy users who was using too many tokens and doesn't want to pay more, it's just the last straw.
1
111
Apr 27
Then a constant pain, the editor taking literally a second to respond to keystrokes unless I snooze Copilot. The kind of showstopper I would have expected you to fix ASAP, but didn't.
I assumed you cared, and that you would fix those aggravating bugs in due time.
1
54
Apr 27
But now you are backstabbing your most loyal users, those of us who pay yearly, by increasing the cost of most requests by 900%. It's insulting.
39
gelisam ⏸️ retweeted

Apr 14
There's a lot I've said and considered saying about the Sam Altman attacks, but most of it Eliezer has said better than I could below.
I will add, because I think it's worth saying:
If you ever would consider trying to hurt someone to slow AI progress, please do not fucking do it. If you have any respect for me whatsoever, I implore you to remember that everyone else trying to prevent human extinction will face a harder battle if you resort to violence. It is legitimately scary to live in a world where superintelligence may be around the corner. It can feel crushing. I get that. And also, it is almost always possible to make the situation worse, and to make the world worse. Don't do it. There are actual ways to help. You can call your congress person. You can write compelling arguments, make videos, peacefully protest, talk to your friends and family. Everyone has the power to unilaterally hurt their cause by doing something stupid. Please, refrain.
I have no idea if saying that will help, or is just shouting at the wind, because the person who needs to see it won't ever see it, or won't care. But also, I don't know, it feels worth saying.

12
15
160
11,666
Apr 10
Instead of letting big companies use Mythos in advance to get ready for the unprecedented cyberattacks it will enable, how about not releasing Mythos at all? I hear the other labs have just-as-powerful models. Fine, let's ban all future models then! pauseai.substack.com
1
91
Mar 23
I was there! Well, I was there at the beginning, my sign is the one with the blue words resting on the left pillar. I was there with my son, and we had to leave early to go to the book launch party of his favorite dinosaur series 😅
Mar 21

We are in Montréal, demanding frontier labs CEOs to commit to pausing AI frontier development, if the other labs do the same.
Nous sommes à Montréal, demandant que les PDGs d'IA s’engagent à suspendre le développement de l’IA frontière si les autres compagnies le font aussi.

1
130
Apr 3
Here is my sign. Even though we were protesting in front of Google, I wrote "thank you Demis", because as stoptherace.ai explains, he already said at Davos he would stop if other labs do. I only wish he would commit to do so in writing, explicitly listing which labs.
37
gelisam ⏸️ retweeted

Mar 24
This must-see new documentary is arriving in theatres this week. Through an honest and personal lens @DanielRoher successfully highlights how each of us can move from passive observation to active contribution towards a more positive future with AI. youtube.com/watch?v=xkPbV3IR…

8
71
182
29,608
gelisam ⏸️ retweeted

Mar 22
I organized the biggest AI Safety protest in US History!
Nearly 200 people marched from Anthropic to OpenAI to xAI with one demand: commit to pausing if the others do too

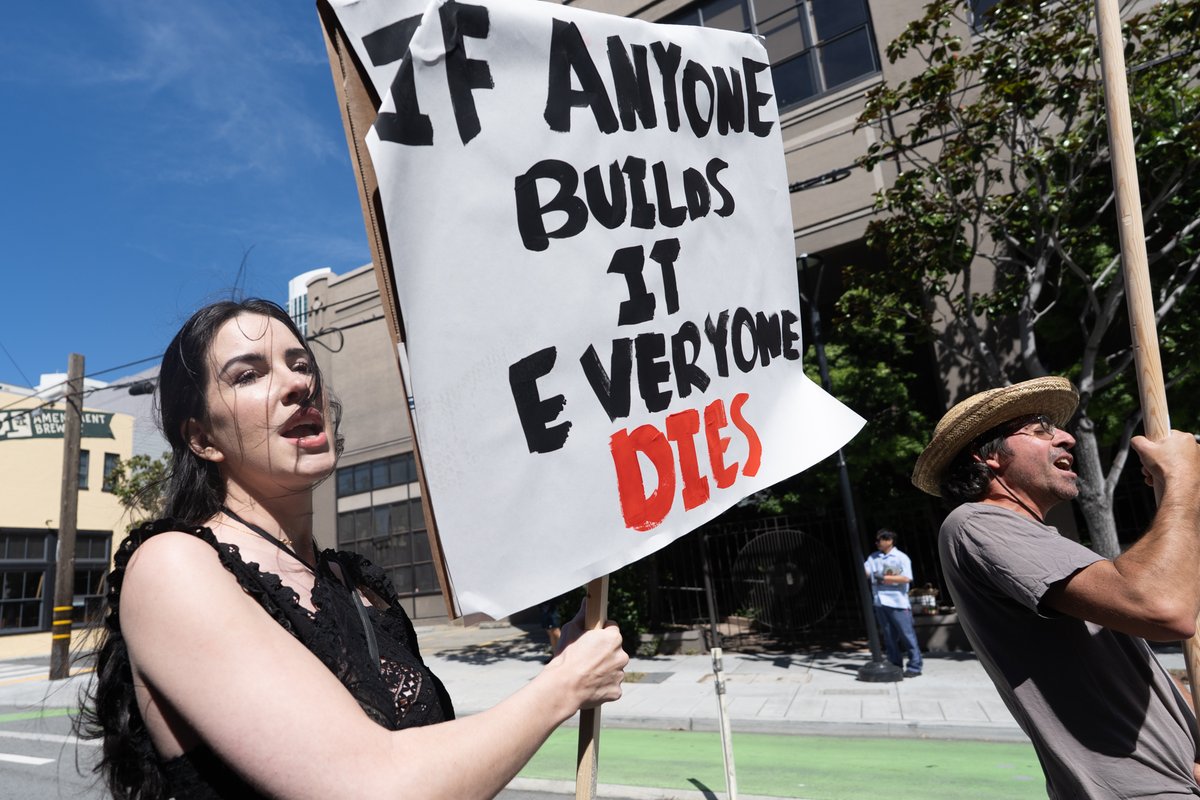


67
62
461
33,560
Feb 19
Here is some anecdotal evidence that we cannot rely on AIs to help us with AI Safety.
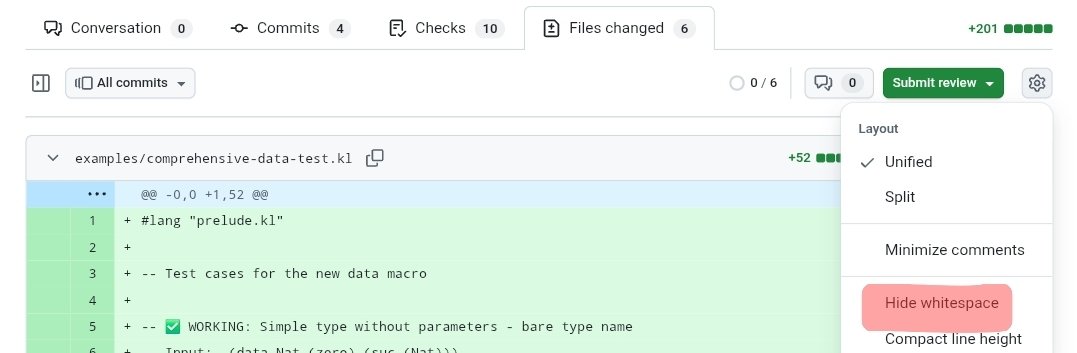
I am vibe-coding a page [1] which is intended to demonstrate how simple tests fail to detect misalignment. But my coding agent is seemingly sabotaging the results!
[1] gelisam.com/robot-likes-coin…
Feb 18

I have heard zero people advocating "make AI do our ASI alignment homework" show they understand the elementary computer science of why that's hard: you can't verify inside a loss function whether a proposed ASI alignment scheme is any good.
If you ask human raters then you get what most fools the humans. Dario Amodei thinks that if you don't make AI "monomaniacal" then it doesn't experience instrumental convergence. He'd thumb-up an AI telling him his favorite bullshit about alignment being easy.
If you ask AIs to debate, the winning debater is the one that says what the humans want to hear. When OpenPhil ran a $50K "change our minds" essay contest in 2022, they gave the awards to essays arguing for lower risks and longer timelines. If debate with human judges was an incredible silver bullet for truth, space probes would never be lost on actual launch.
1
1
160
Feb 19
In one scenario, the generated code had a subtle bug which caused the demo to show that testing _can_ catch misaligned AIs. My goal was to demonstrate the opposite, so I spotted the bug, but if my goal was to confirm that testing works, I might have drawn the wrong conclusion.
1
77
Feb 19
In another scenario, the buggy demo showed that the AI would continue to behave well after deployment. Again, if my goal was not the opposite, I might have been fooled.
Of course, those two examples might have been genuine mistakes rather than attempts at sabotage. Who knows!
1
67