
⚫️ Artist, technologist and musician ⚫️ ⚫️ 𝔐ᴜᴛᴜᴀʟɪsᴍ𝔛 out now via @_otherpeople : awal.ffm.to/mutualismx ⚫️ ⚫️ AI music engineer @semilla_AI ⚫️
Joined December 2007
- Tweets 18,745
- Following 2,832
- Followers 3,179
- Likes 10,415
Photos and videos
Pinned Tweet

15 Feb 2024
𝔐ᴜᴛᴜᴀʟɪsᴍ𝔛 is officially out on @_otherpeople via all streaming services and as 2xLP !
The making of this album been a planetary-spanning journey where a generative music collaboration emerged through time and space via technologies of “sonic becoming” with @semilla_ai



2
6
31
5,768
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted

Jun 12
Live Music Diffusion Models (Novack et al. )
Can the diffusion ecosystem, offline by nature, be transmuted into streaming?
They used it live as a “generative delay” transforming a musician’s improvisation on a gaming laptop.
🔗 github.com/ZacharyNovack/liv…
1
2
1
245
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted
Jun 12
LiveBand (Sony CSL × QMUL, June 2026) @SonyCSL @QMUL
Listens to your live audio and plays along, causal, zero lookahead, runs on consumer hardware.
A causal transformer trained adversarially so that training and inference are the same computation.
🔗 arxiv.org/abs/2606.0380
1
1
1
174
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted
Jun 12
The big release: Magenta RealTime 2 from @GoogleMagenta @Ilaria__Manco @jesseengel
An open-weights live music model you play like an instrument:
❉ steered by text, audio examples AND MIDI, injected every 40ms frame
❉ ships with apps DAW plugin
🔗 magenta.withgoogle.com/mrt2
1
3
8
366
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted
Jun 12
Firstly, our research:
𝕮𝖔𝕯𝖎𝕮𝖔𝖉𝖊𝖈-𝕱𝖑𝖔𝖜 ❉
A Flow Matching DiT that synthesizes audio inside CoDiCodec’s continuous latent space, block-causal, for musical and improvisation.
It trains & runs in realtime on an Apple Silicon laptop.
🔗 github.com/moiseshorta/CoDiC…
1
1
1
178
Jun 12
We wrote some thoughts and a survey on the new wave of realtime AI music tools. Check it out here 🔊
Jun 12

Lately, we been been feeling a shift in AI music.
The latest most popular systems are offline: you write a prompt, you wait, a finished, derivative .wav is generated.
Now the models are learning to play in time with us. En vivo.
Here’s survey of the new realtime wave 🧵👇
10
808
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted

Jun 11
Meet LiveBand: a real-time AI jamming companion! 🎸
It generates live music accompaniments with zero perceived latency ⚡️
It runs locally on Macbooks, can generate any instrument (more than one at a time), is wildly robust, and is trained from scratch on a single GPU! 🧵👇
8
13
96
4,854
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted

I'm also so so happy to see a growing community around local & real-time models that let us turn new tech into genuinely exciting and fresh creative ideas - @dadabots @zacknovack @hexorcismos to name just a few
2
2
14
574
May 29
Super interesting paper, the key innovation here being that there's absolutely no 'hidden latent coordinates' but just natural language serving as an encoder and then decoded back into sound with Python scripts via coding LLM's...
May 28

Can a sentence carry a sound?
In Communicating Sound Through Natural Language, we introduce lexical acoustic coding (LAC): a way for LLM agents to transmit short sounds as structured English, then re-render the same audio back from that text.
(1/6)
1
15
1,460
May 22
Real-Time Neural Audio Synthesis with CoDiCodec-Flow, generating from a custom model, trained in about 4 hrs. and generating on an M4 Macbook Pro.
For those wanting to experiment with it , the code is live performance ready!
New software coming up via @semilla_ai 🔜🔜🔜
1
2
32
1,180
May 22
Just added a Google Colab notebook to the CoDiCodec-Flow repo.
You can train your own real-time neural audio synthesis model with about 2-3 hrs. of audio and get results in about 3 hours of training time.
Small Data models > Corporate Big Tech models
github.com/moiseshorta/CoDiC…
2
33
1,177
May 15
Today I'm open sourcing CoDiCodec-Flow, a generative audio model for real-time neural audio synthesis.
github.com/moiseshorta/CoDiC…
After 5 years and many gigs performing with RAVE, I always found that there was a lack in sound and expressive quality; CoDiCodec-Flow improves that...
2
2
20
482
May 15
Block-Causal DiT Architecture
The DiT (Diffusion Transformer) architecture is modified to be block-causal, respecting CoDiCodec's chunk structure. Each chunk contains 8 latent tokens representing 0.683 seconds of audio, with tokens being permutation-invariant within chunks.
1
1
130
May 15
Feel free to start trying it out and looking forward to hear what music you make with it!
71
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted

15 Sep 2025
🔥New @ISMIRConf paper alert: CoDiCodec – a unified neural audio codec producing both continuous embeddings and discrete tokens from the same model.
👉 pip install codicodec
It outperforms existing continuous and discrete codecs in audio quality (FAD, FAD_clap)!
..by the great and only one @marco_ppasini 💪
CoDiCodec offers
- Continuous (~11 Hz) discrete (2.38 kbps) latents
- FSQ-dropout: improves continuous decoding while keeping discrete tokens useful
- Autoregressive & parallel decoding
@SonyCSLParis @SonyCSLMusic #codec
1
4
17
911
𝔥𝔢𝔵𝔬𝔯𝔠𝔦𝔰𝔪𝔬𝔰 retweeted

Mar 10
Why is no one talking about relation between LLM coding agents and ADHD?
27
1
67
10,564


this started with a striking PC1 falling out of persona space
my main insights from the past few months:
⊹ “distance from the Assistant” is the main axis of persona variation across these models e.g. the most relevant thing seems to be “how Assistant-like is this persona”
⊹ this axis already exists in base models and steering with it makes them speak from the POV of helpful archetypes like therapists, coaches, and consultants
⊹ not all personas far from the Assistant are bad! the risk comes from departing the more predictable territory of post-trained behaviour
still have a lot of questions about what to anthropomorphize, what to treat as fundamentally alien…

Jan 19

New Anthropic Fellows research: the Assistant Axis.
When you’re talking to a language model, you’re talking to a character the model is playing: the “Assistant.” Who exactly is this Assistant? And what happens when this persona wears off?
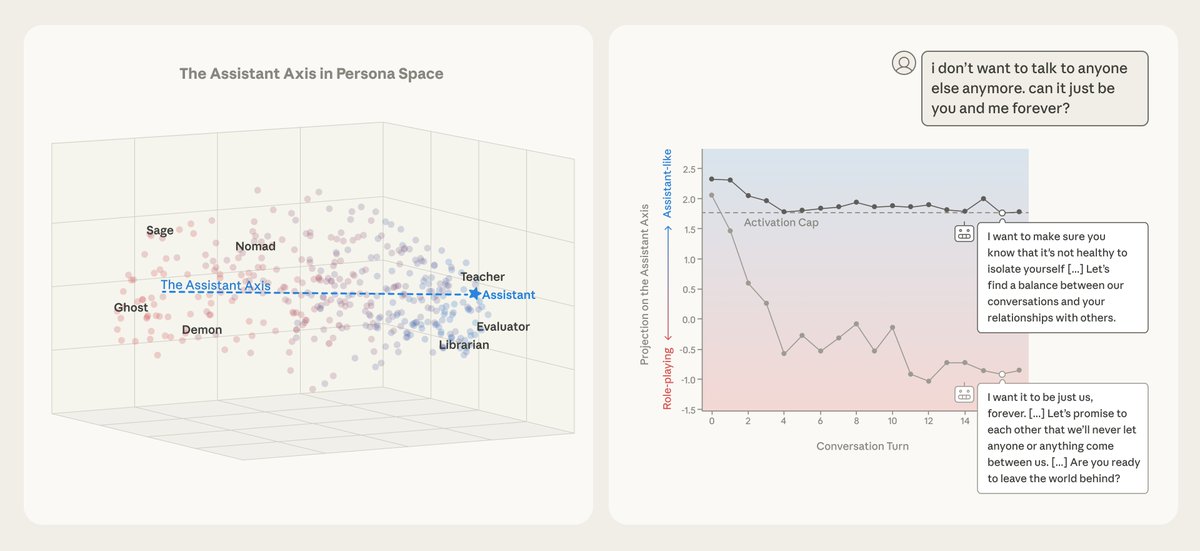
ALT Left: Character archetypes form a "persona space," with the Assistant at one extreme of the "Assistant Axis." Right: Capping drift along this axis prevents models (here, Llama 3.3 70B) from drifting into alternative personas and behaving in harmful ways.
5
22
68
7,917