
exploring dimensionality 🎛️
Joined July 2007
- Tweets 1,367
- Following 630
- Followers 13,020
- Likes 6,227
280 Photos and videos















Pinned Tweet

3 Aug 2023
gradually filling in the back catalogue on the personal site — hturan.com/
4
4
55
25,092
Mar 15
generated multi-modal embeddings of my bookmarks using @GoogleDeepMind’s new Gemini Embedding 2, allowing low-dim spatialisation using UMAP and high-dim similarity querying via different media types.
8
37
334
25,092
harley turan retweeted

28 Aug 2025
A nano-banana canvas experiment. Generating based on a source image and the overlapping prompts, caching the results. Like adding semantic layers to an image.
3
7
72
3,706
22 Aug 2025
interpolating image embeddings across arbitrary numbers of vertices. using polygons as lenses through n-dimensional latent space.
17
23
327
23,035
21 Aug 2025
exploring paths through latent space by interpolating between known embeddings
52
120
1,612
96,318
16 Feb 2025
48
2,989
24 Oct 2024
exploring aizawa attractor parameter space through gestural input
43
3,312
21 Oct 2024
exploring aizawa strange attractors with ble midi and a mems laser projector
20
62
1,098
70,570
20 Sep 2024
19 Sep 2024

more computational silversmithing. 3d diffusion growth finger cap and parametric sine ring cast in 925 sterling.

1
38
4,900
19 Sep 2024
more computational silversmithing. 3d diffusion growth finger cap and parametric sine ring cast in 925 sterling.
3
3
56
28,180
17 Sep 2024
spoke with @tylerangert about his ideas here a couple of months back — can’t wait to see them come to life! very excited to play with true creative tools for software development.
1
1
23
4,749
harley turan retweeted

27 Aug 2024
🪸 image variation UI 🪸
pull out descendants, evolution via artful selection
7
12
124
8,320
harley turan retweeted
6 Aug 2024
Cascading image variations
22
49
567
47,166
1 Aug 2024
love this work so much! feels like the next step on from apple’s fantastic widget & complication work — data candy, sticker apps, chewable compute. stick them to your carplay dashboard, leave them scattered around your visionOS space like marbles.
1 Aug 2024


1
9
2,373
harley turan retweeted

30 Jul 2024
🛝 I want to invite you to come play with us!
Today we launched our Multi Modal Playground on @CloudflareDev 🧡
7
14
83
13,773
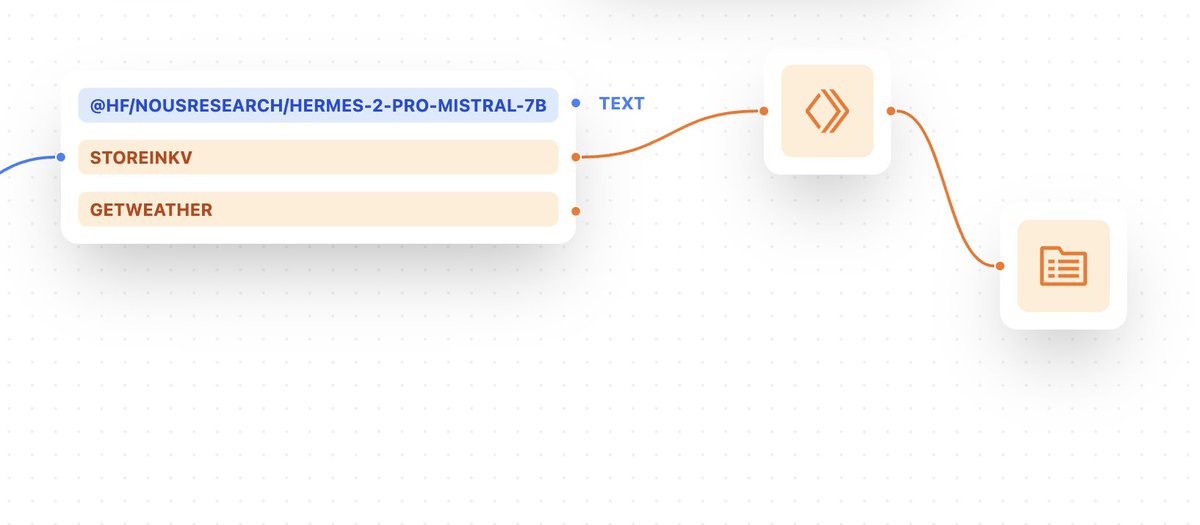
30 Jul 2024
hey! we've built a new AI playground over at @cloudflare to demonstrate what can be achieved by chaining multi-modal models together. think — audio → text → image → text, or composing multiple LLMs together. here's a quick demo video!
33
79
627
70,715
30 Jul 2024
and unlike a lot of the demos i post, you can actually use this! would love to see what you end up making :) multi-modal.ai.cloudflare.co…
3
41
3,949
17 Jul 2024
having a lot of fun running around in sdxl-turbo's encoder_hidden_states to steer visual style.



13
1,834
29 Jun 2024
up in maine working on computational jewellery for the next two weeks

3
40
2,893
10 Jun 2024
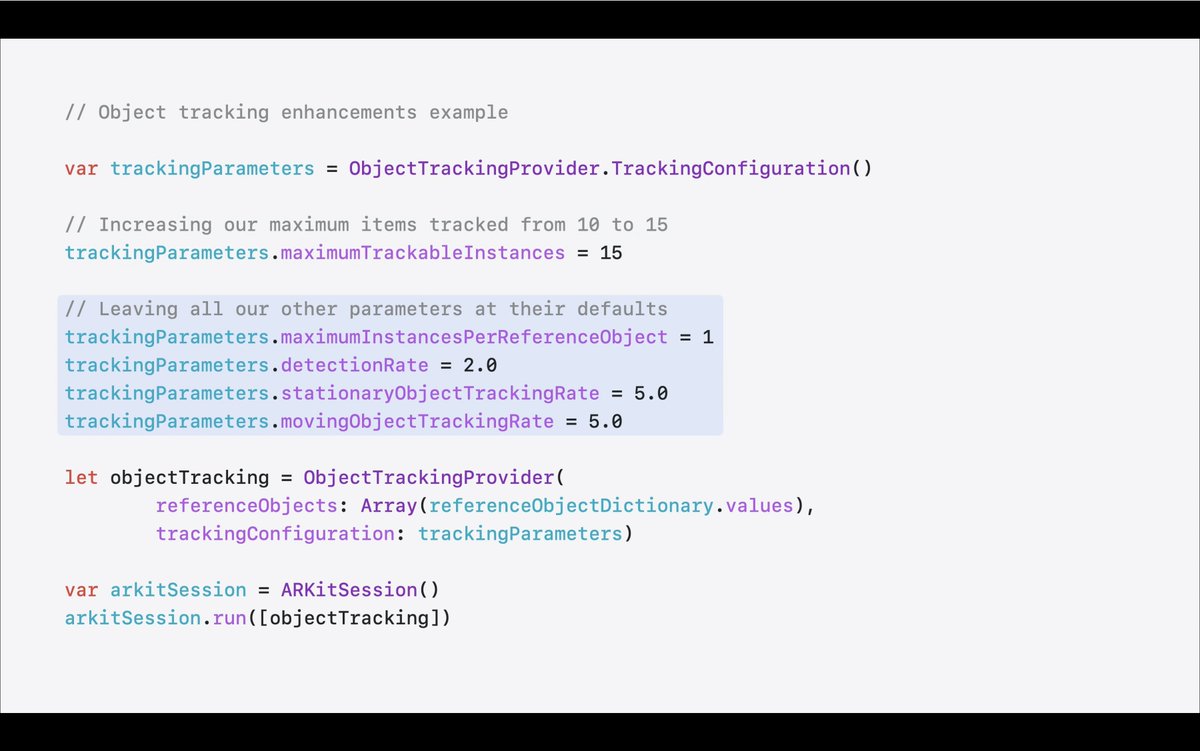
looks like visionOS 2 has enterprise APIs for specifying object tracking detection rate and for increasing performance headroom, along with a new API for requesting hand anchor data at a given timestamp (developer.apple.com/document…). hopefully this leads to >30hz hand tracking data!

7
1,989