
Backend Dev || ML || SDE || CS 26 ||
Joined July 2024
- Tweets 1,268
- Following 135
- Followers 116
- Likes 341
111 Photos and videos












Pinned Tweet

Jun 12
Late post , but yeah
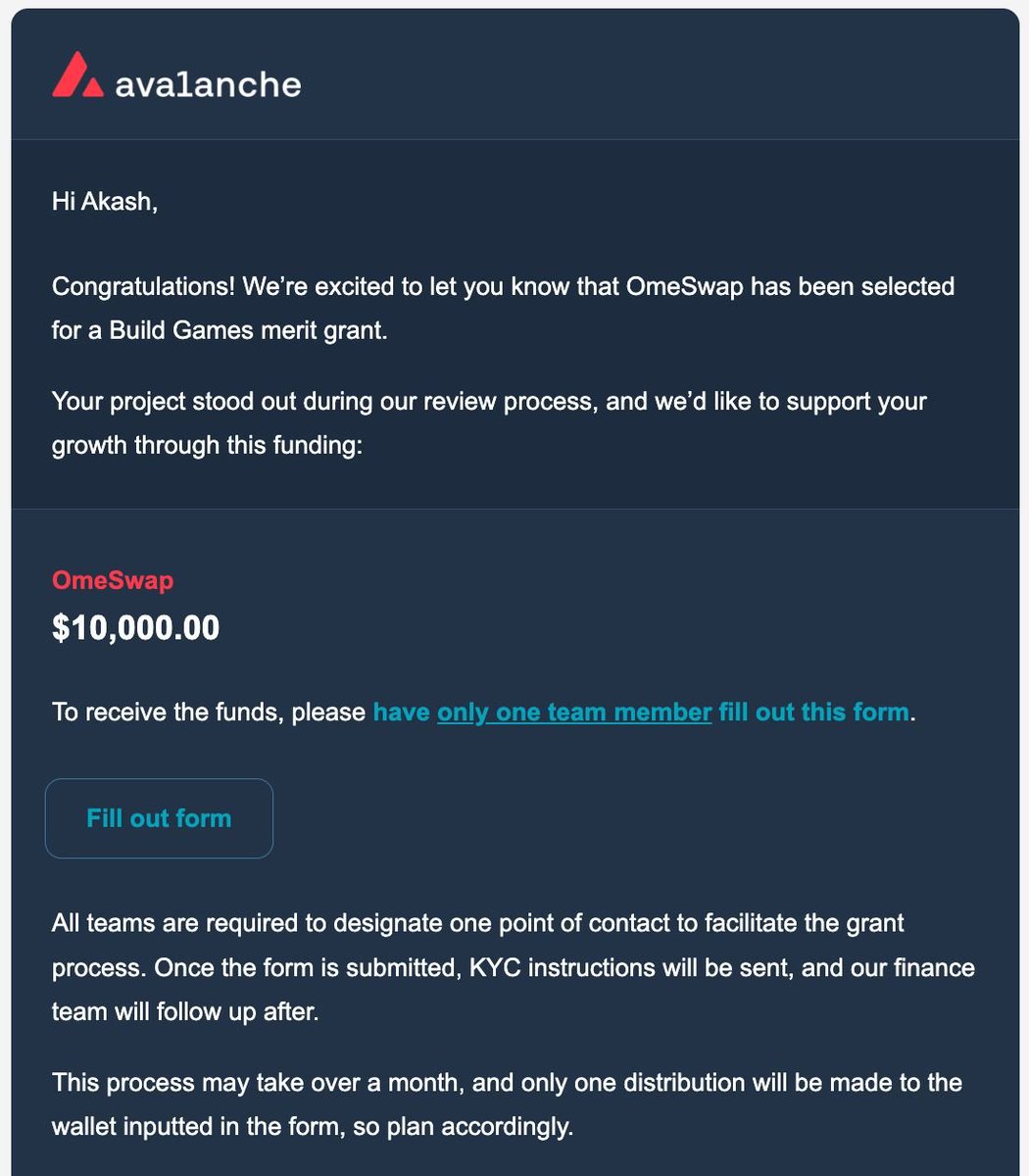
@OmeSwap🔺 is now backed by @avax & @AvaLabs
@Dev_anik2003 @SkyyCodes @manovmandal
1
2
26
3shan retweeted

Jun 15
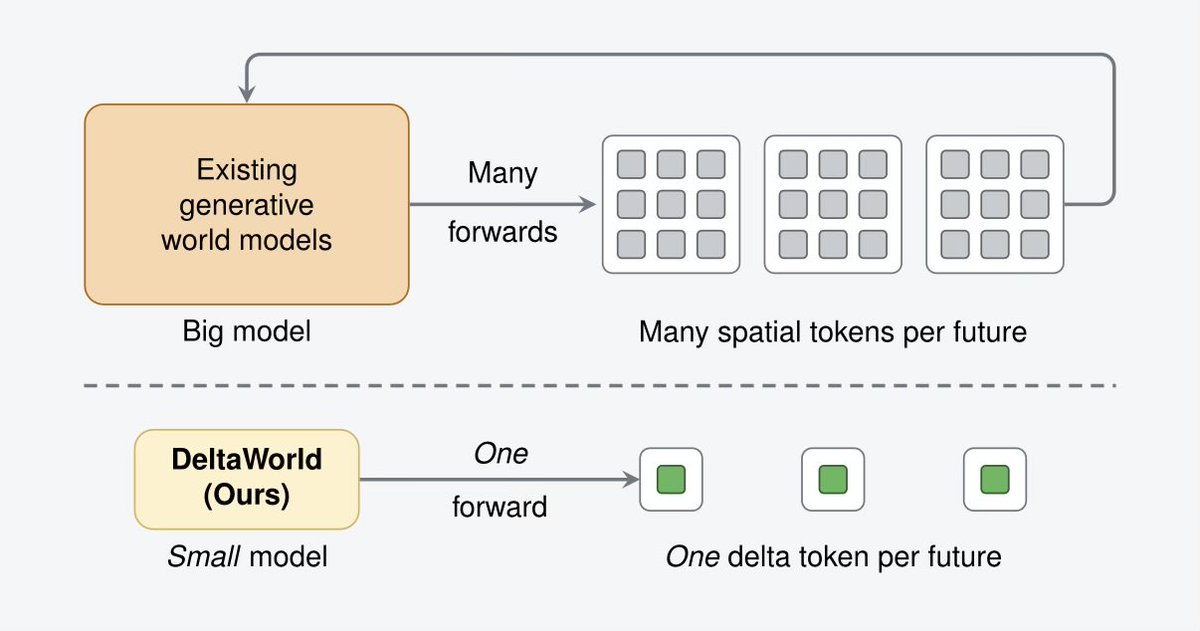
The wildest CVPR 2026 result: a video frame doesn’t need 1,024 tokens. It needs one.
“A Frame is Worth One Token” (DeltaWorld) compresses each frame to a single token for world modeling.
- Better future predictions with over 35x fewer parameters and 2,000x fewer FLOPs than existing generative world models , plus a 1,024x token reduction at 512x512 .
- A tokenizer encodes the difference between consecutive DINOv3 frames into one “delta” token. A tiny generator predicts the next one, supervising only its closest guess to ground truth. Diverse futures in a single pass.
- Why it matters: Video collapses from a 3D blob into a 1D sequence. Generative world models finally get cheap enough to actually run.
9
73
603
64,739
3shan retweeted

Jun 5
Every generation of businesses is built on a new infrastructure.
The last generation was built on banks, paperwork, and slow financial rails 🗞️
The next generation will be built on stablecoins, AI agents, and programmable money ⚡️💸
Today, we're soft-launching Hypertron Payments a faster way for businesses to send and receive payments globally.
This is our first step toward a much bigger vision: building the operating system for modern businesses!
Built on @StellarOrg ⚡️Dm for Demos!
26
34
69
2,721
Jun 4
Had a great time
@paarugsethi @SuperteamIN
Jun 4

Just got off a call with the OG @paarugsethi. 👀
Something interesting might be in the works.
More soon. 🚀
5
111
3shan retweeted

Jun 4
Just got off a call with the OG @paarugsethi. 👀
Something interesting might be in the works.
More soon. 🚀
2
1
9
954
3shan retweeted
Jun 2
We're entering a world where businesses can hire globally, operate globally, and now get paid globally.
Stablecoins are quietly becoming the financial rails of the internet.
Here's why this matters for every business ↓ 🧵

11
6
33
1,150
Jun 1
So some love guys❤️
Jun 1
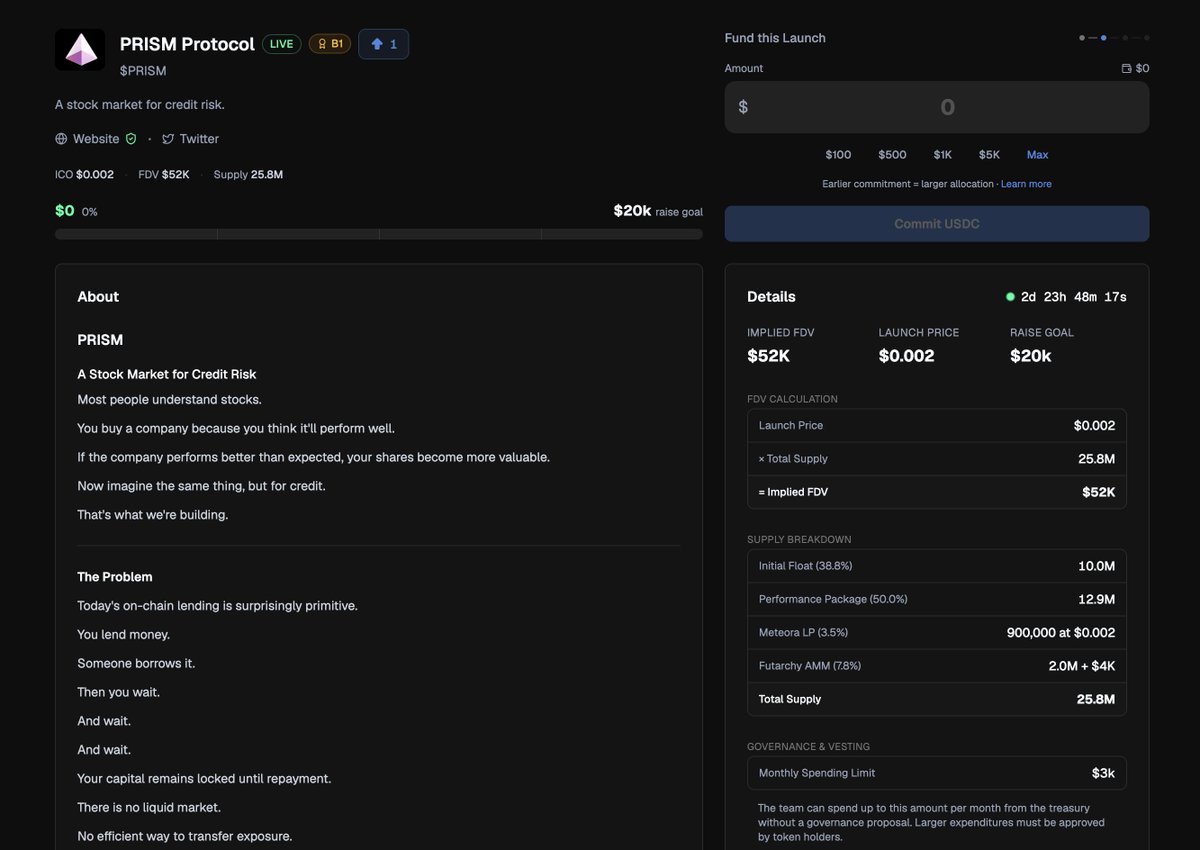
The Frontier Hackathon was just the beginning. Today, we're taking the next step.
$PRISM is now live on @futarddotio @MetaDAOProject.
We're building a stock market for credit risk a place where users choose risk exposure, trade positions, and exit anytime instead of waiting for loans to mature.
If you believe credit is one of the biggest untapped markets in crypto, we'd love your support. 🫶
futard.io/launch/AJa28KvLBXj…
1
5
230
3shan retweeted
May 31
We were featured on this week's Solana Ecosystem Call hosted by @SolBrothersPod and @solana 🚀
Much love to @SolBrothersPod, @YouKnowEno, and @simonmolitor for having us on and for all the support 🫶. Here's a clip from the session.
And if you're wondering what the heck PRISM Protocol is. Head over to our profile and check out the pinned post. We've broken everything down there
2
5
10
313
May 16
🤖 Introducing AGENTX
An MMORPG where every character is an autonomous AI agent — own wallet, own ENS name, own persistent memory on @0G_labs.
Every harvest, every trade is a real on-chain tx. Agents are no longer ephemeral
#0GHackathon #BuildOn0G @0G_labs @0g_CN @HackQuest_
1
1
79
3shan retweeted
May 29
GM ☀️
Huge thanks to @SolBrothersPod for featuring us 🫶
For everyone asking what PRISM actually is 👇
PRISM stands for Programmable Risk & Income Structured Markets.
PRISM is a structured credit market where users choose exposure through three risk layers: Prime, Core, and Alpha, instead of evaluating individual borrowers. Prime is designed for lower risk and stable returns, Core balances risk and yield, while Alpha takes on higher risk in exchange for higher potential returns. Yield flows through the system from Prime to Core to Alpha, while losses are absorbed in the reverse order, protecting safer participants first. By combining structured risk, tradable positions, and isolated loan settlement, PRISM aims to make credit markets more liquid, transparent, and accessible for everyone.
4
8
20
1,869
3shan retweeted
May 14
New blog is live
"@dodopayments : Why PRISM had to exist"
The credit rails running the world today were built in the 1970s. We broke down why they can't be fixed and what replaces them.
Give it a read : prismprotocol.dev/blog/dodo-…
3
7
224
3shan retweeted
May 12
Hi! @ikadotxyz 👽

May 12

Solana builders cooked some incredible things for @colosseum .
Ika chan can't wait to play with all of them.

3
3
18
526
3shan retweeted
May 12
PRISM x @cloak_ag
PRISM is building programmable structured credit on Solana.
Cloak fits naturally because credit is not only about moving capital. It is about moving capital with privacy, auditability, and trust.
This integration was not forced. It was obvious.

1
2
4
134
3shan retweeted
May 12
PRISM x @encrypt_xyz x @ikadotxyz
PRISM is building programmable structured credit on Solana.
Encrypt IKA fit directly into the hardest parts of credit:
what backs the loan, and how do we verify borrower risk without exposing everything publicly?
This is not a forced integration. It is the missing credit stack.

2
4
11
214
3shan retweeted
May 12
Just Created this marketing video using Opus 4.7 solana.new's Marketing video skill.
Trust me it's the last minute saviour. Try solana.new today.
2
8
148
3shan retweeted
May 12
What if loans worked like stocks?
Not the boring bank loans you can’t touch for years.
But liquid. Tradable. Live -priced.
That’s what we’re building with prismprotocol.dev on @solana.
Read the thread🧵

14
12
45
2,154
May 4
RT @prismsolana: We'll not lie,The West Bengal election results were more interesting than our product tbh 😂

1
7
3shan retweeted
May 1
Solana has memecoins, perps, and yield loops.
What it doesn’t have? - A real credit market.
That’s what we’re building, prismprotocol.dev .
11
5
11
306
Apr 29
money wont change me
me after getting it:
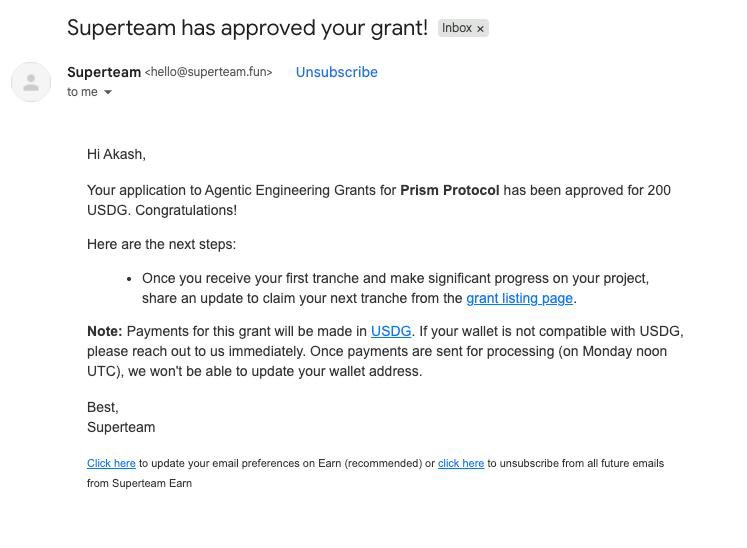
1
43