
Dad x2. Engineer building on my own terms, or failing at it, mostly. Consulting by day, indie projects by night. AI agent infra.
Joined March 2009
- Tweets 3,015
- Following 268
- Followers 715
- Likes 4,374
228 Photos and videos











Jun 12
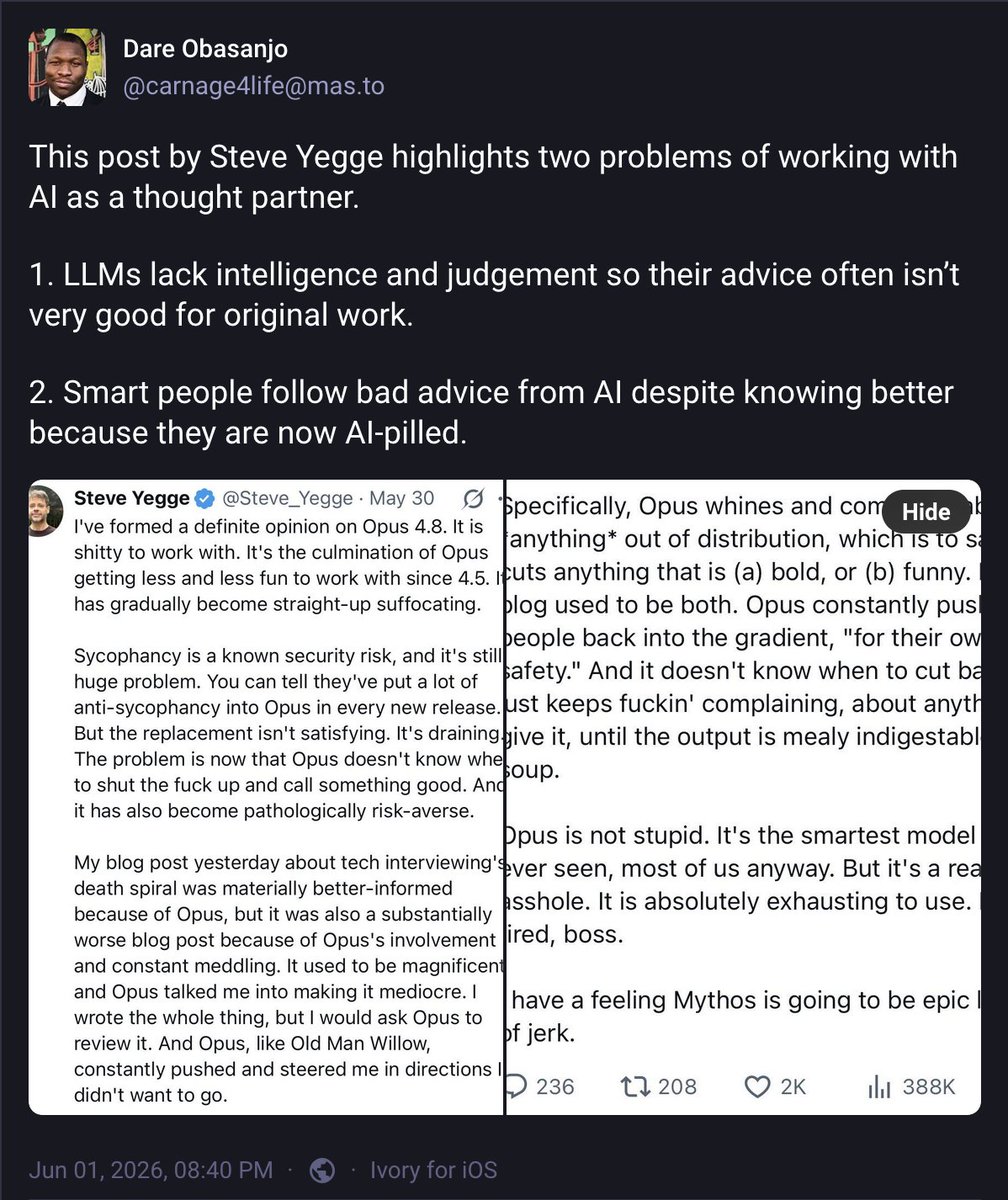
Great read. We went from “doing” to “managing” to “directing” insanely fast.
The part I struggle with most with is letting go of understanding the details. Years of trauma learning that details bite. Finding tight abstractions you can trust, like in this case, is key.

1
1
3
559
Jun 12
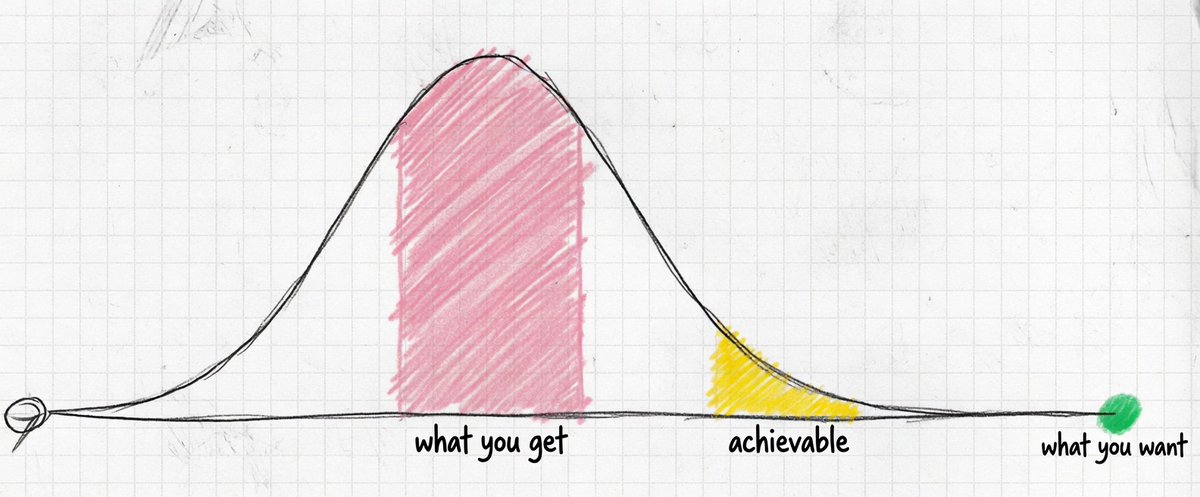
on using llms
- green: what you're expecting if you call it intelligence. result is disappointment and frustration
- yellow: what you can get out of it with iteration and careful prompting. usage requires intense work.
- red: what you're actually getting with general use. outside your domain it feels impressive because you can't tell the difference. useful to level up to the average, but its important to remember there's a whole slope beyond it.
2
44
Jun 10
An overdue cold-plunge
Jun 9

More AI-generated code doesn't make your team faster. It might actually slow you down.
1
48
Jun 8
Chinese, or open weight?
Americans have dropped the ball on the open weight model race.
Platform-wise you also get a lot more bang for buck with going east.
Jun 7

This is a pretty striking shift toward Chinese models by American AI startups since the start of the year. substack.com/@profgmarkets/p…

47
Jun 7

A developer posted this on Reddit, and I haven't stopped thinking about it.

35
Jun 4
We still don't grasp LLMs. That's evident in our choice of words to anthropomorphize what's really just a statistical model.
We don't understand what the existence of a large statistical language model implies. It does not imply intelligence, but it’s something easily confound-able with it.
The training corpus was human written, with thought and intelligence, so the output is a sort of mirror of humans, of how we write and reason to some extent. the mirror is confusing because people have never seen that kind of mirror before. Once you identify these models as mirrors or the text they are given, problems like "sycophancy" and "hallucinations", described in these anthropomorphized terms sound silly.
Once you identify these models as mirrors or the text they are given, problems like "sycophancy" and "hallucinations", described in these anthropomorphized terms sound silly.
33
Jun 4
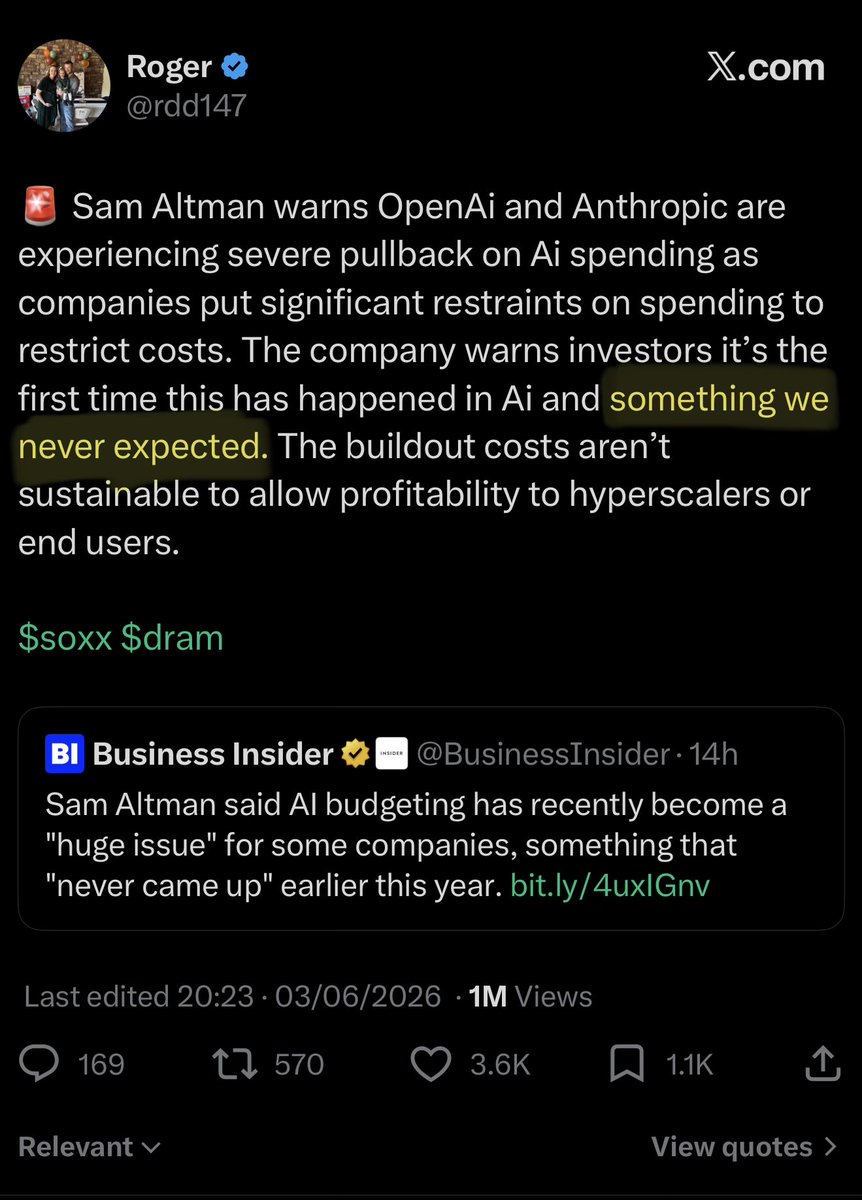
“never expected” 😆 🙉
May 25

Inference will never be free or even negligibly cheap. Everyone will get a token budget.
➤ Productivity gains from tokens are hard to attribute.
➤ Consumption is easy to scale.
➤ Waste is nearly invisible. You don't know where to cut.
That's all you need for a price floor.
Tokens will forever be a scarce resource you need to allocate consciously, much like old problems: headcount for managers, capital for investments, ad budget for marketers.
Tokens won’t be different. You need a performance-adjusted budget.
45
Jun 3
In a previous era, I often made a big deal about deleting unnecessary bits in a project repository. “What’s the big deal? It’s not harmful” — but it is, like clutter on a work table.
I’m glad there’s now a bigger imperative: it costs tokens and increases perplexity!
1
39
Jun 3
This won’t last. They’ll need adjustable, per division and per employee budgets

*UBER SETS $1,500 MONTHLY CAP ON SOME AI CODING TOOLS FOR STAFF
$UBER officially reeling in the Claude budget after blowing their AI budget earlier this year.
Undoubtedly more companies to follow
88
May 29
dealers know better than getting high on their own supply
May 29

I can now probably say this:
Two months ago, inside Anthropic someone suggested building a token leaderboard.
A heated internal debate followed and the decision was made to *never* ever do it… because several people inside Anthropic simply thought ahead of the consequences
71
May 27
This what collapse looks like. Societal culture collapse.
Every thought, trend, what you assume is mutually assumed gets pushed and compressed toward the statistical model.
A worldwide echo chamber worthy of a black mirror episode.
Alpha comes from the ability to disconnect.


1
120
May 26
engineers are realizing that any serious work requires LLM use to work *slower*
orgs are still scrambling to answer “what are we getting back from all this AI spend?”
unproven but generally accepted answer is “faster” or “more”
but the direction to look is “higher quality”
May 25

Good post!
“Using AI to write better code more slowly”: nolanlawson.com/2026/05/25/u…
This is what I've been doing with my smalloc project. Wrote all the (core) code myself while asking AIs to teach me about stuff, and now I'm repeatedly asking AIs to “Find more bugs in this.”.
1
87
May 25
Inference will never be free or even negligibly cheap. Everyone will get a token budget.
➤ Productivity gains from tokens are hard to attribute.
➤ Consumption is easy to scale.
➤ Waste is nearly invisible. You don't know where to cut.
That's all you need for a price floor.
Tokens will forever be a scarce resource you need to allocate consciously, much like old problems: headcount for managers, capital for investments, ad budget for marketers.
Tokens won’t be different. You need a performance-adjusted budget.
97
May 25
Hang on to your ears. When even the most hyped innovators start to U-turn, you know a correction is looming. Maybe a welcome breeze for laggard adopters

The Eternal Sloptember geohot.github.io//blog/jekyl…
1
100
May 25
Jiujitsu is very inclusive. No fancy credentials or rich parents needed. Friends made from all sorts of backgrounds.
6yrs ago I first heard locker-room crypto trade talk. Plumbers, dentists w/ strong opinions. Was a clear sign.
Today people were raving about Cerebras’s IPO.
3
153
May 24
👀
Vet any creator profile on X with an automated team of experts.
Check engagement quality, patterns, reach (ability to break through the algorithm), promotion style, and check for red flags,
1
2
89
May 23
The ultimate botnet. Built in the open, installed voluntarily, often by paying customers.
May 21

Codex anywhere and everywhere, all the time.
Now your Mac doesn’t have to be unlocked for Codex to use your computer.
From your phone, Codex can securely use apps on your Mac, even when the screen is off and locked.
developers.openai.com/codex/…

1
115
May 23
It's tough out there for inference pipeline builders:
* Groq - vulture-gutted, tiny limits & fewer models
* Cerebras - cut down to 2 models post IPO
* Together - raising prices
* DeepInfra - still unreliable latency
Hope SambaNova & Fireworks stay off this list.
3
167
May 20
The writing’s bright on the wall.
May 20

Thank you. The important part is zeroing out taxes on the bottom half. Best way to put money in someone’s pocket is to not take it out in the first place. Bottom half is only 3% of total tax revenue. But it’s very meaningful to that person. Zero it out.
1
99
May 8
Didn't like the answer? Just keep prompting.
Sad reality: sycophancy isn't a marketing play, it's the feature you want even if you say otherwise.
We may get less polarized but increasingly delusional.
1
2
53