
Joined December 2023
- Tweets 498
- Following 611
- Followers 105
- Likes 1,581
172 Photos and videos




Pinned Tweet

24 Sep 2025
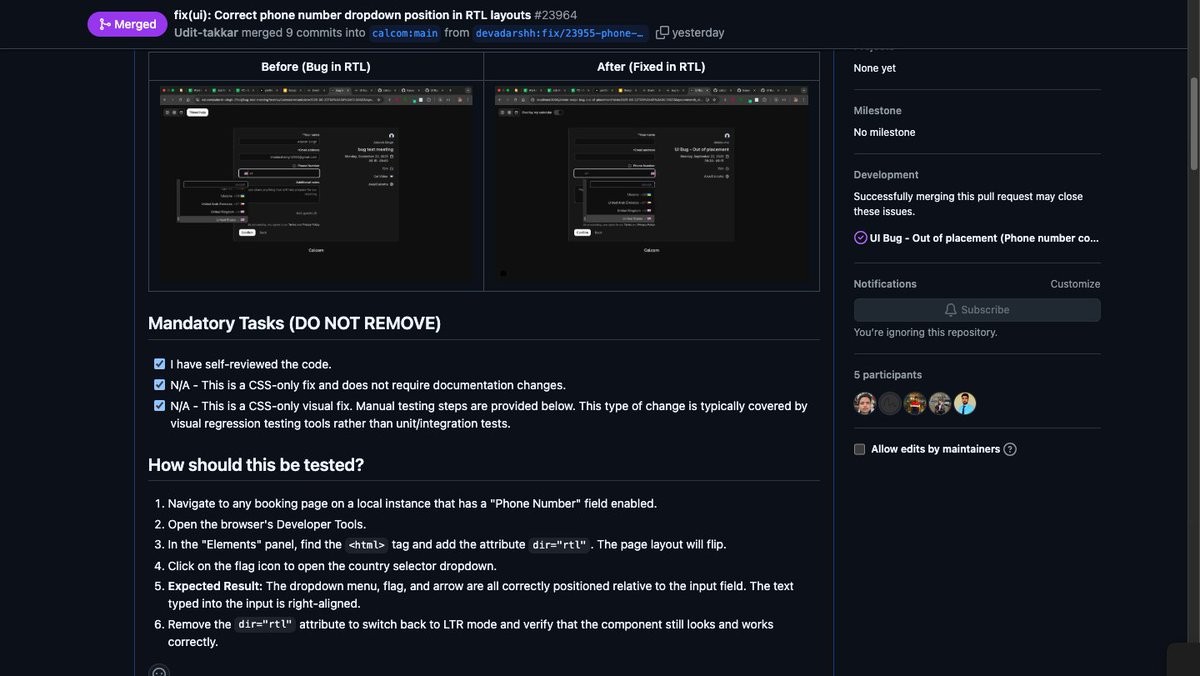
🎉 Thrilled to make open-source contribution to @calcom ! 🚀💻
Huge thanks to @100xDevs and @kirat_tw for the guidance — this experience reinforced the power of building, shipping, and contributing to real-world products.
#OpenSource #WebDev #BuildInPublic

4
1
10
1,555
Adarsh Singh retweeted

May 29
POV: My everyday experience with Claude.
5
16
2,616
May 29
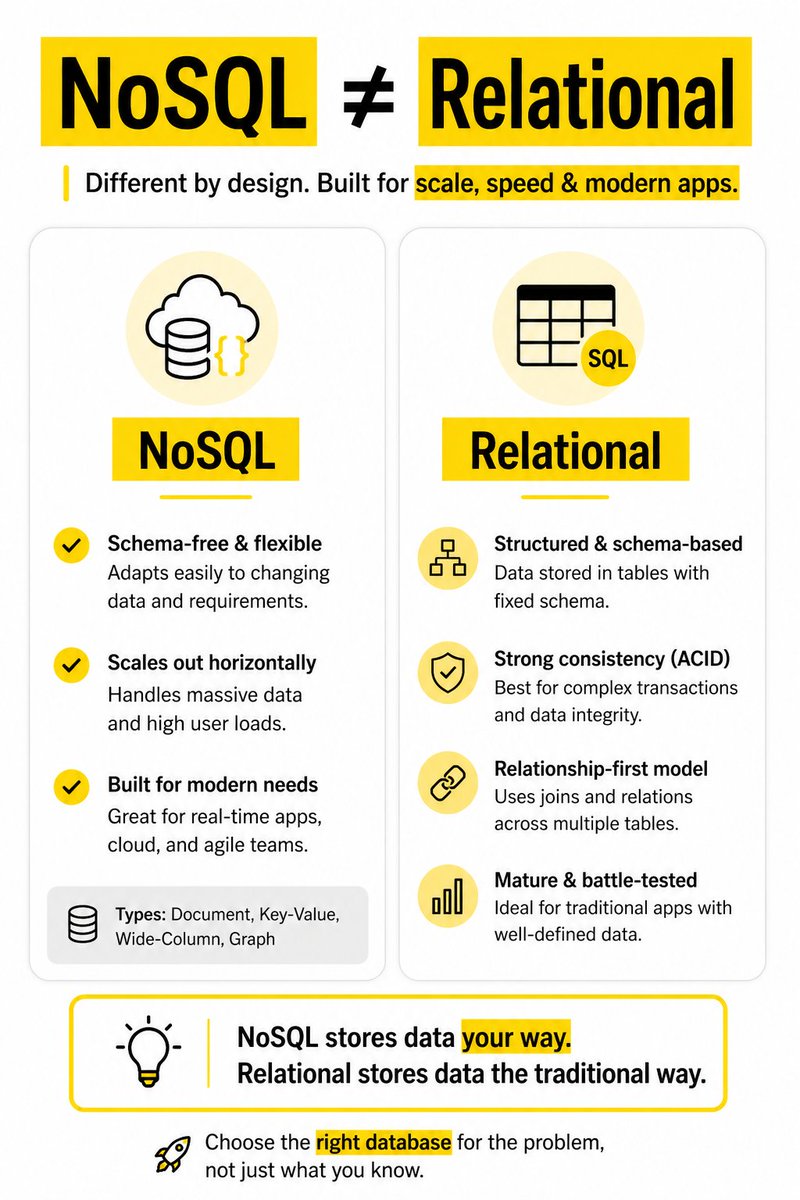
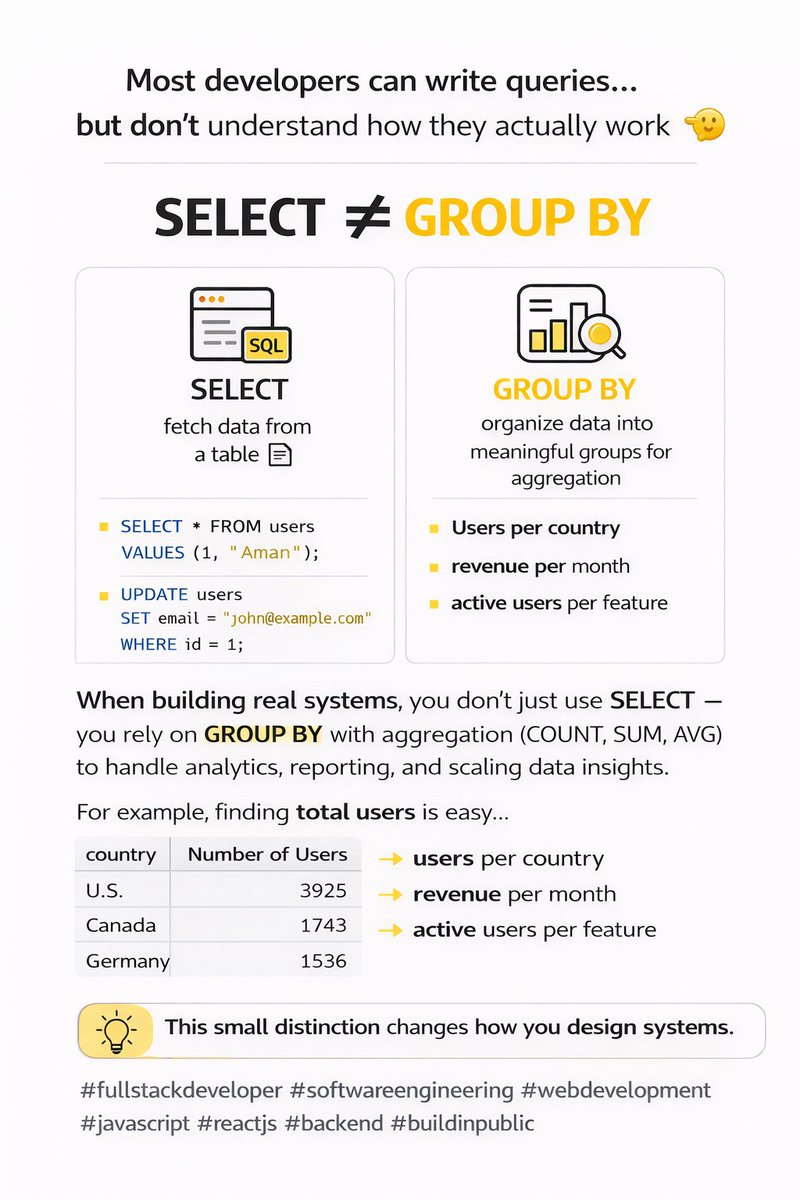
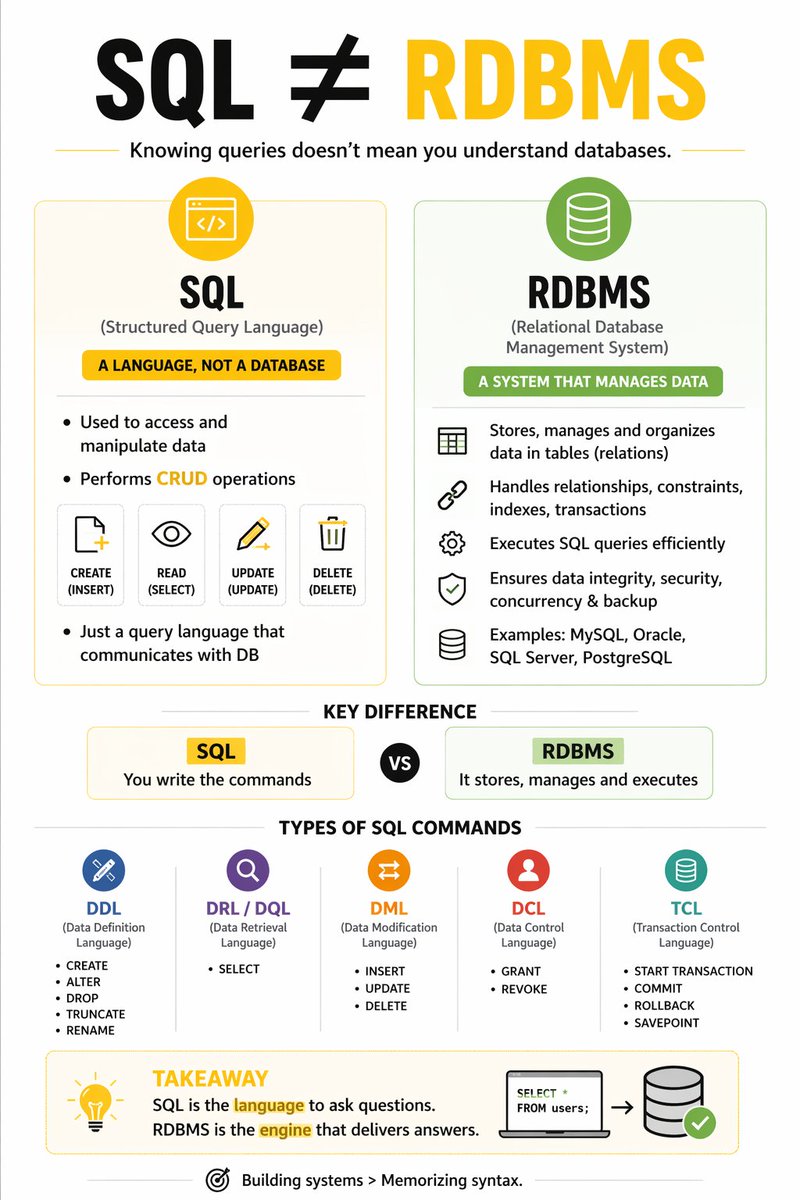
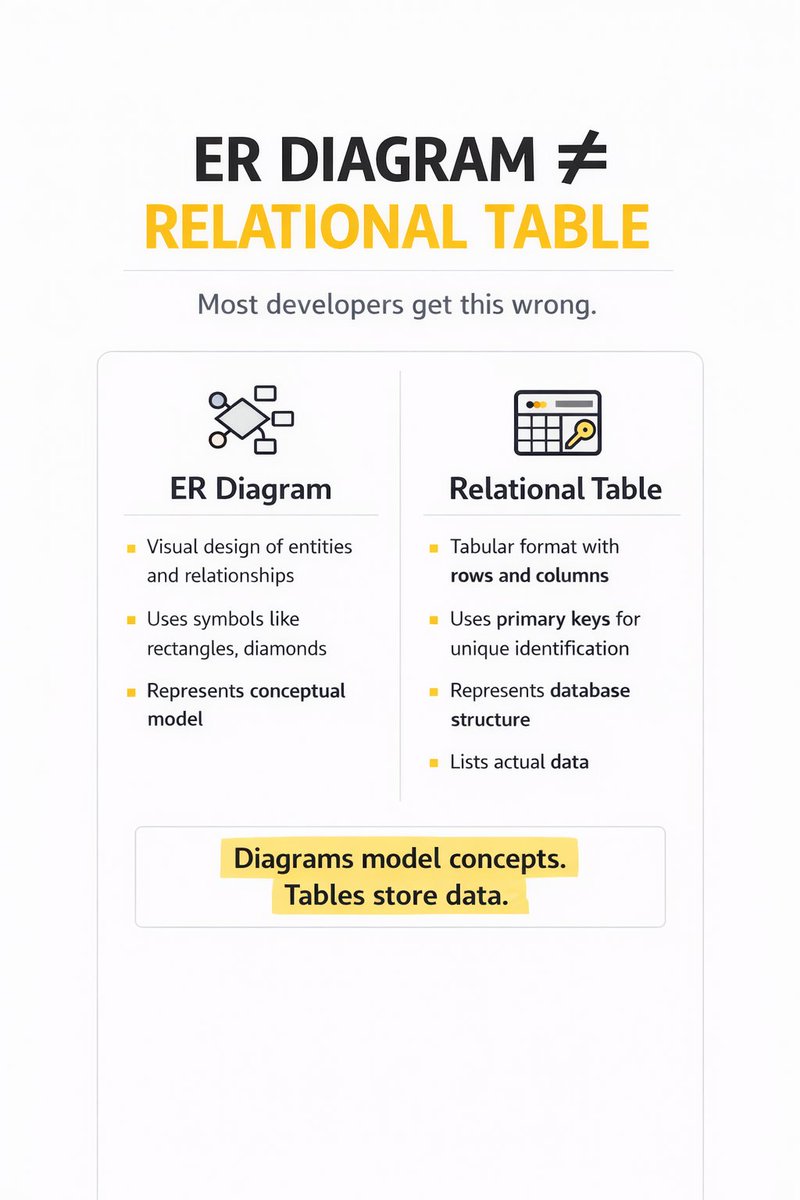
🔥 If you think “database = SQL”… you’re already limiting your system design.
Different problems need different databases — and great engineers know when to switch.
Relational DB ≠ NoSQL DB
Relational DB → Structured tables with fixed schema and strong consistency
NoSQL DB → Flexible schema designed for scale and high traffic
Relational DB ≠ Object-Oriented DB
Relational DB → Data split across tables and connected using joins
Object-Oriented DB → Data stored as complete objects, closer to real-world models
When building real systems, you don’t just use relational databases —
you rely on NoSQL for scalability and flexibility, and sometimes object-based models for complex domain logic ⚡
Think like this:
User Orders in SQL → Multiple tables joins
User in Object DB → One complete object with nested data
Hierarchical DB ≠ Relational DB
Hierarchical DB → Tree-like structure with parent-child relationships
Relational DB → Flexible relationships using foreign keys and joins
This matters when your data naturally forms a hierarchy — like org structures or file systems.
Reality most devs ignore 👇
No single database solves everything
Relational DBs give:
Consistency and normalization
NoSQL gives:
Scalability and flexibility
Object DBs give:
Closer mapping to real-world entities
But each comes with trade-offs in performance, complexity, and scalability.
This small distinction changes how you design systems —
especially when your app starts scaling beyond simple CRUD.
Building systems > memorizing concepts.
What’s one concept developers often misunderstand?
#fullstackdeveloper #softwareengineering #webdevelopment
#javascript #reactjs #backend #buildinpublic #nodejs #nextjs
#typescript
15
Adarsh Singh retweeted

Still waiting for the tests to complete
5
16
119
6,481
Adarsh Singh retweeted

May 22
Reading the policies which HR told me on 1st day of joining.
13
144
2,098
150,195
May 21
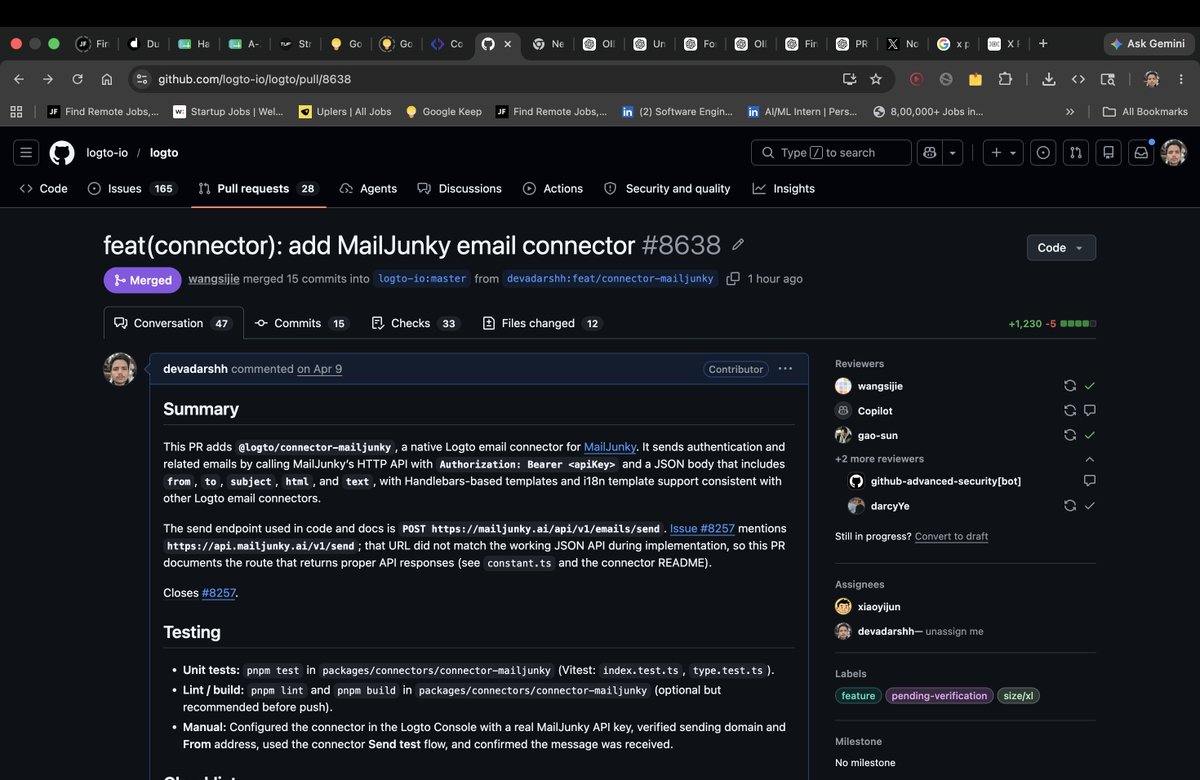
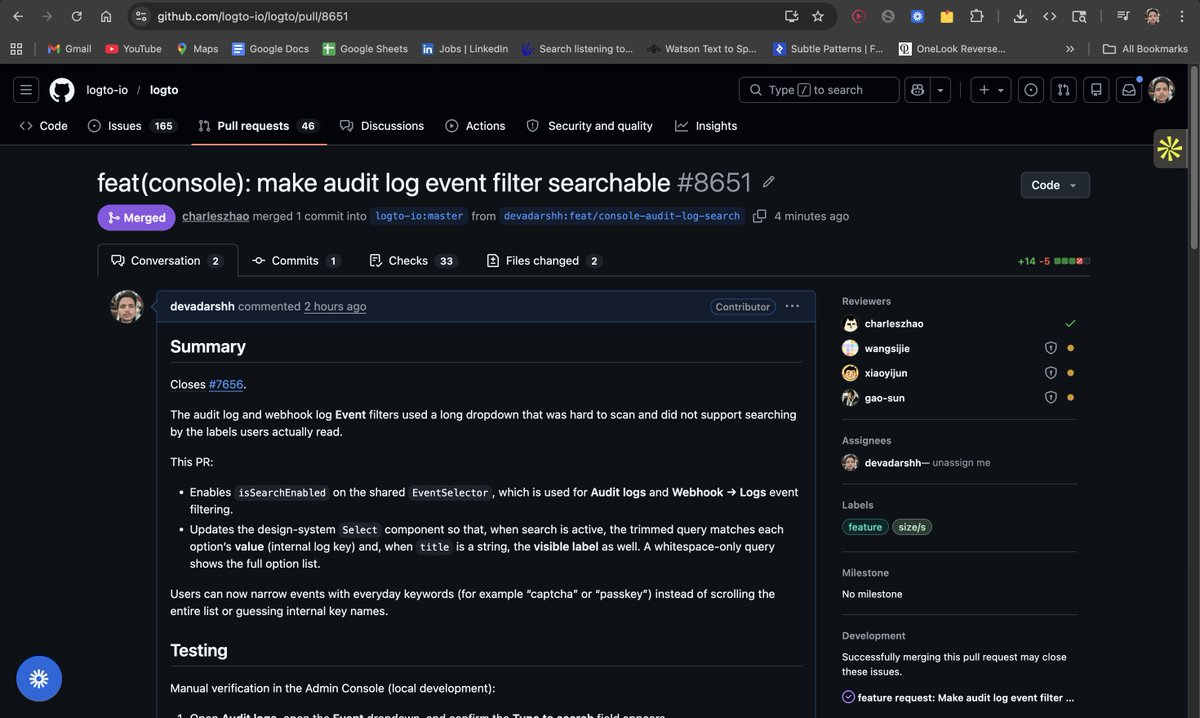
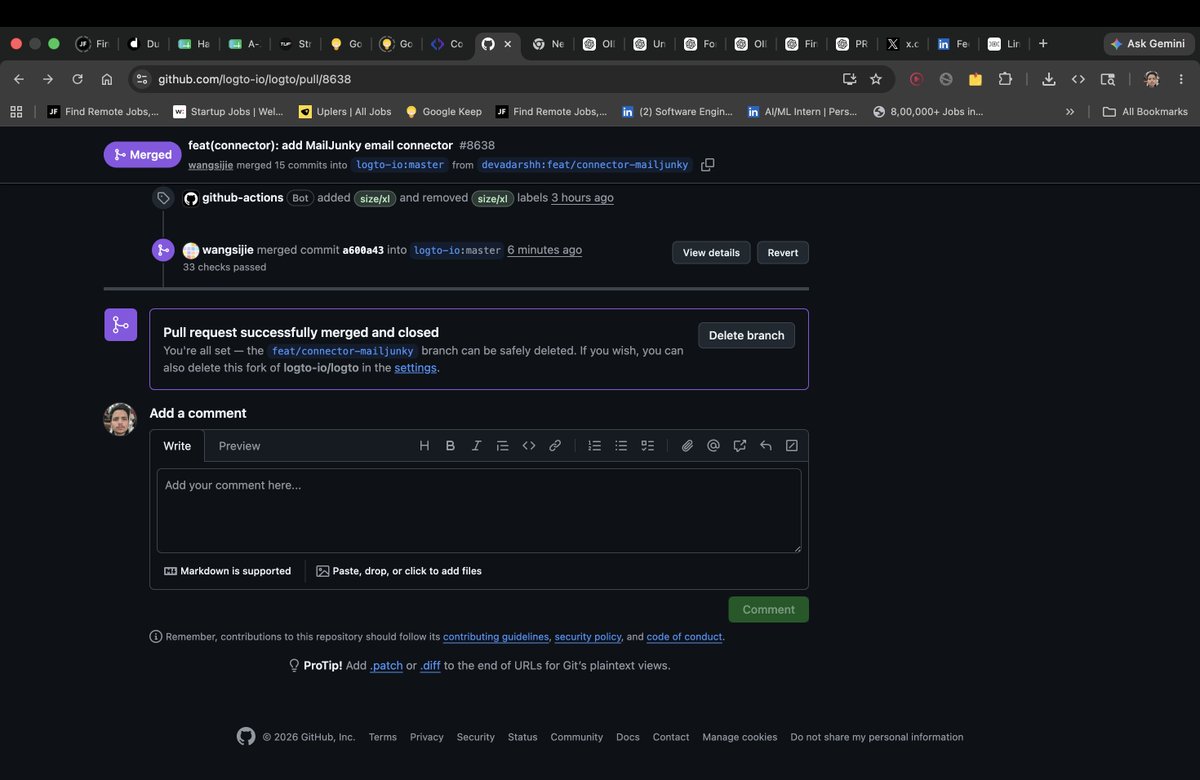
Just got my PR merged into @logto_io 🚀
Implemented a native MailJunky Email Connector for Logto with auth email support, Handlebars templating, i18n support, validation improvements, and tests ✅
1230 lines contributed • 15 commits
Open source keeps teaching me how production-grade software is built 🙌
#opensource #typescript #nodejs #github #logto
1
3
24
Adarsh Singh retweeted
My friend adding Devops Engineer in his resume after learning :
kubectl apply -f deployment.yaml
13
11
122
11,504
Adarsh Singh retweeted

May 16
getting paid after taxes
1,097
23,364
200,007
12,629,957
Adarsh Singh retweeted

May 15
POV : USING CLAUDE OPUS 4.7 TO JUST RENAME A VARIABLE
150
1,251
21,497
806,092

Adarsh Singh retweeted

May 12
Claude seeing me write an entire line of code by myself
47
545
6,517
361,388

Adarsh Singh retweeted

May 10
How my entire Codebase written with Claude code runs
3
4
66
6,198
Adarsh Singh retweeted

May 5
Going through a tough time. Actively looking for work.
Last 6 months:
→ Merged PRs in @better_auth @appwrite @mintlify @umami_software
→ 150 GitHub stars, 4K npm downloads
→ Shipped 10 products app
Frontend & Product Engineer. 3 yrs. Available now.
DM or retweet. 🙏
4
124
851
56,056

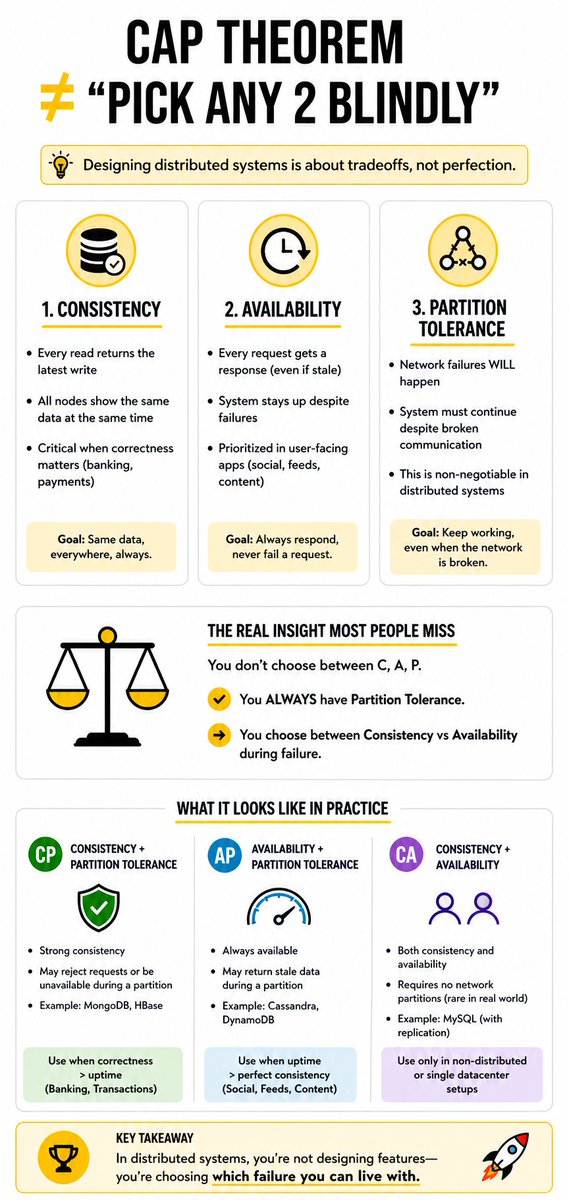
If your system “works perfectly” in local but breaks in production… you probably ignored CAP Theorem 👇
CAP Theorem is not theory — it’s a design constraint.
Every distributed system is forced to choose tradeoffs.
Consistency ≠ Availability
Consistency → Every read gets the latest write across all nodes
Availability → Every request gets a response, even if data is outdated
Partition Tolerance → System survives network failures (this is non-negotiable in real systems)
When building real systems, you don’t just aim for consistency —
you rely on tradeoffs between consistency and availability to handle real-world failures.
Example:
Banking system → prefers Consistency (CP) to avoid wrong balances
Social media feed → prefers Availability (AP) so users always see something
This is why:
MongoDB → CP (strong consistency, may sacrifice availability)
Apache Cassandra → AP (high availability, eventual consistency)
This small distinction changes how you design systems.
You stop asking “which DB is best?”
and start asking “what tradeoff does my system need?”
Building systems > memorizing concepts
What’s one concept developers often misunderstand?
#fullstackdeveloper #softwareengineering #webdevelopment
#javascript #reactjs #backend #buildinpublic #nodejs #nextjs
#typescript
1
15

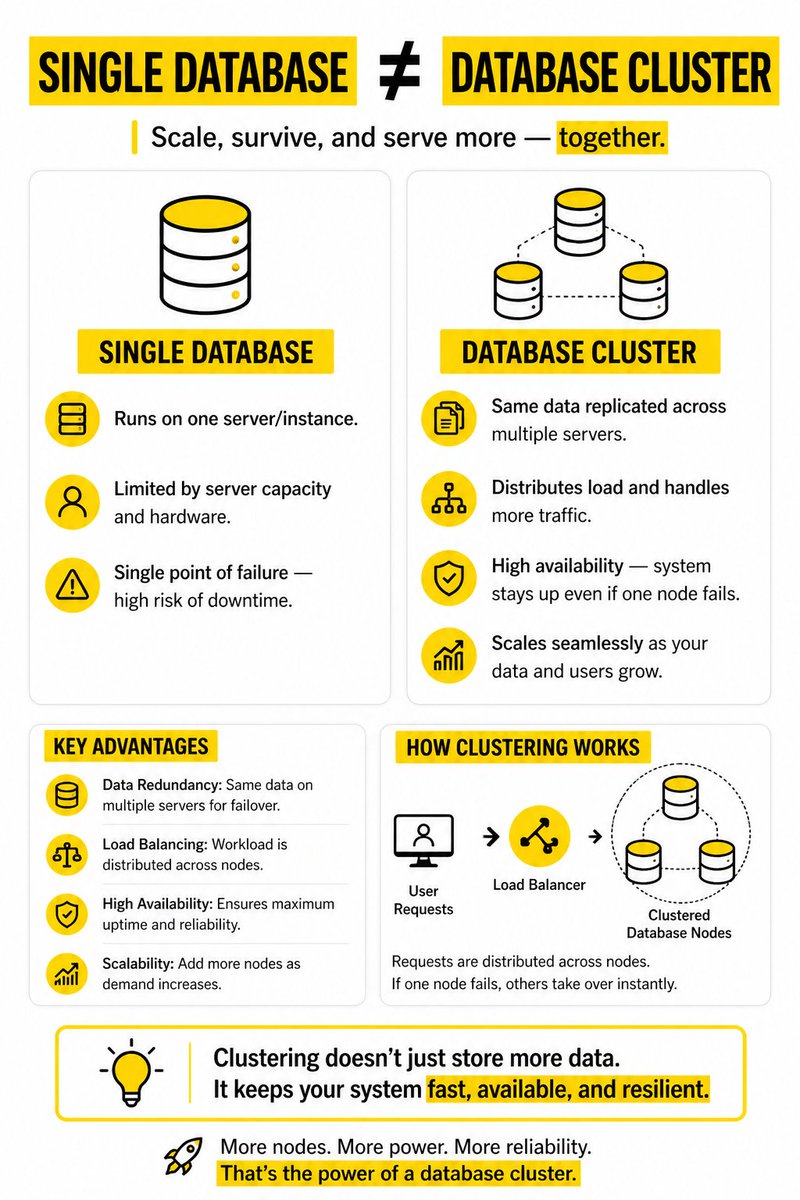
Your app doesn’t crash because of traffic…
It crashes because of how you scale 🚀
Most developers think scaling = adding more power.
That’s only half the story.
Vertical Scaling ≠ Horizontal Scaling
Vertical Scaling → Upgrade your machine (more RAM, CPU, SSD)
Horizontal Scaling → Distribute load across multiple machines
When building real systems, you don’t just scale up —
you rely on distributing reads, caching, and replicas to handle real-world traffic spikes.
That’s where patterns like read replicas and CQRS quietly save your system from collapsing.
This small distinction changes how you design systems.
Building systems > memorizing concepts.
What’s one concept developers often misunderstand?
#fullstackdeveloper #softwareengineering #webdevelopment
#javascript #reactjs #backend #buildinpublic #nodejs #nextjs
#typescript
18
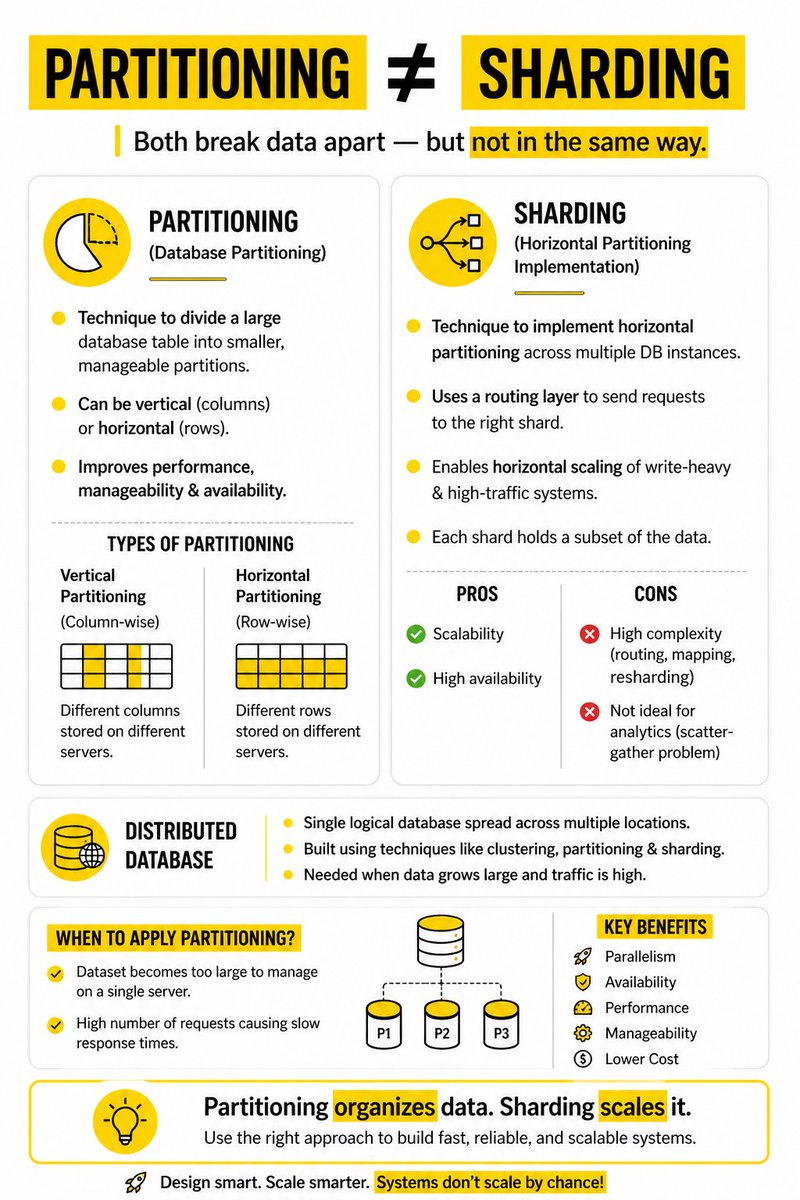
🔥 Your database isn’t slow… your design is.
When data grows, throwing bigger servers at it won’t save you — smart partitioning will.
Partitioning ≠ Sharding
Partitioning → Splitting large data into smaller manageable pieces
Sharding → Distributing those pieces across multiple servers with routing
Vertical Partitioning ≠ Horizontal Partitioning
Vertical Partitioning → Split by columns, different attributes on different servers
Horizontal Partitioning → Split by rows, different records on different servers
When building real systems, you don’t just store massive datasets —
you break them down and distribute them to handle scale, performance, and availability ⚡
Think like this:
One huge table → Slow queries, hard to manage
Partitioned data → Faster queries, parallel processing
Why engineers use this 👇
Parallelism → Multiple queries run at the same time
Performance → Less data scanned per query
Availability → Failure of one partition doesn’t kill the system
Cost → Cheaper than scaling a single giant server
Sharding adds another layer 👇
Request comes in → Routing layer decides → Correct shard handles it
But here’s the catch ⚠️
Sharding improves scalability…
but increases complexity in routing, rebalancing, and querying
And this is where most devs struggle:
Analytics queries become harder because data is scattered
This small distinction changes how you design systems —
especially when moving from single DB to distributed architecture.
Building systems > memorizing concepts.
What’s one concept developers often misunderstand?
#fullstackdeveloper #softwareengineering #webdevelopment
#javascript #reactjs #backend #buildinpublic #nodejs #nextjs
#typescript
7