
Building the first non-human SEO agency from the beach in Sri Lanka 🌊 20 years SEO → AI agents.
Joined October 2021
- Tweets 125
- Following 211
- Followers 103
- Likes 357
11 Photos and videos






Apr 15
For a long time, visuals for social were one of those things I kept putting off.
Not because I didn't see the value... but because creating them was painfully slow. Design each slide, get the sizing right, export, convert to PDF... every single time.
So when we launched Aloha Digital's new website, I decided to fix that.
I built a carousel/video generator that automatically turns every blog post we publish into a ready-to-upload LinkedIn carousel or an X video. Same branding, same style, zero manual design work.
This is the first one 👇
It breaks down what Agentic SEO actually is and why it's not just "using AI for SEO."
If you find it useful, give it a like or repost. More coming soon from {The Search}, our weekly insights series.
1
2
101

Apr 4
Big
Apr 3

Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw.
You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
25
Mar 31
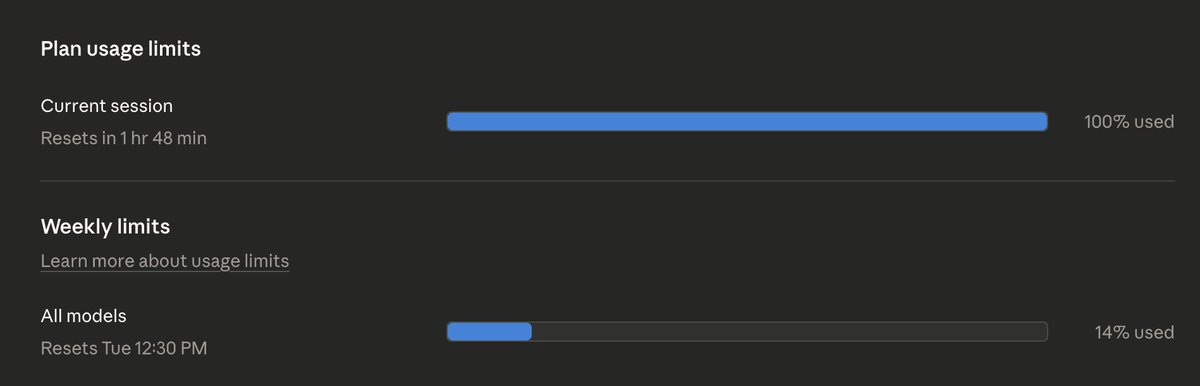
1 prompt (can you call it even a "prompt"?) - asking Claude Code (Opus 4.6 - 200K Context) to review developers.google.com/crawli… and a client's robots.txt file and compare if our client meeting best practices. 30 seconds later: Current session: 100% Used. Weekly: 14%. It was 0 and 0. Both reset today!
You've hit your limit · resets 5:30pm :(
1
58
Mar 31
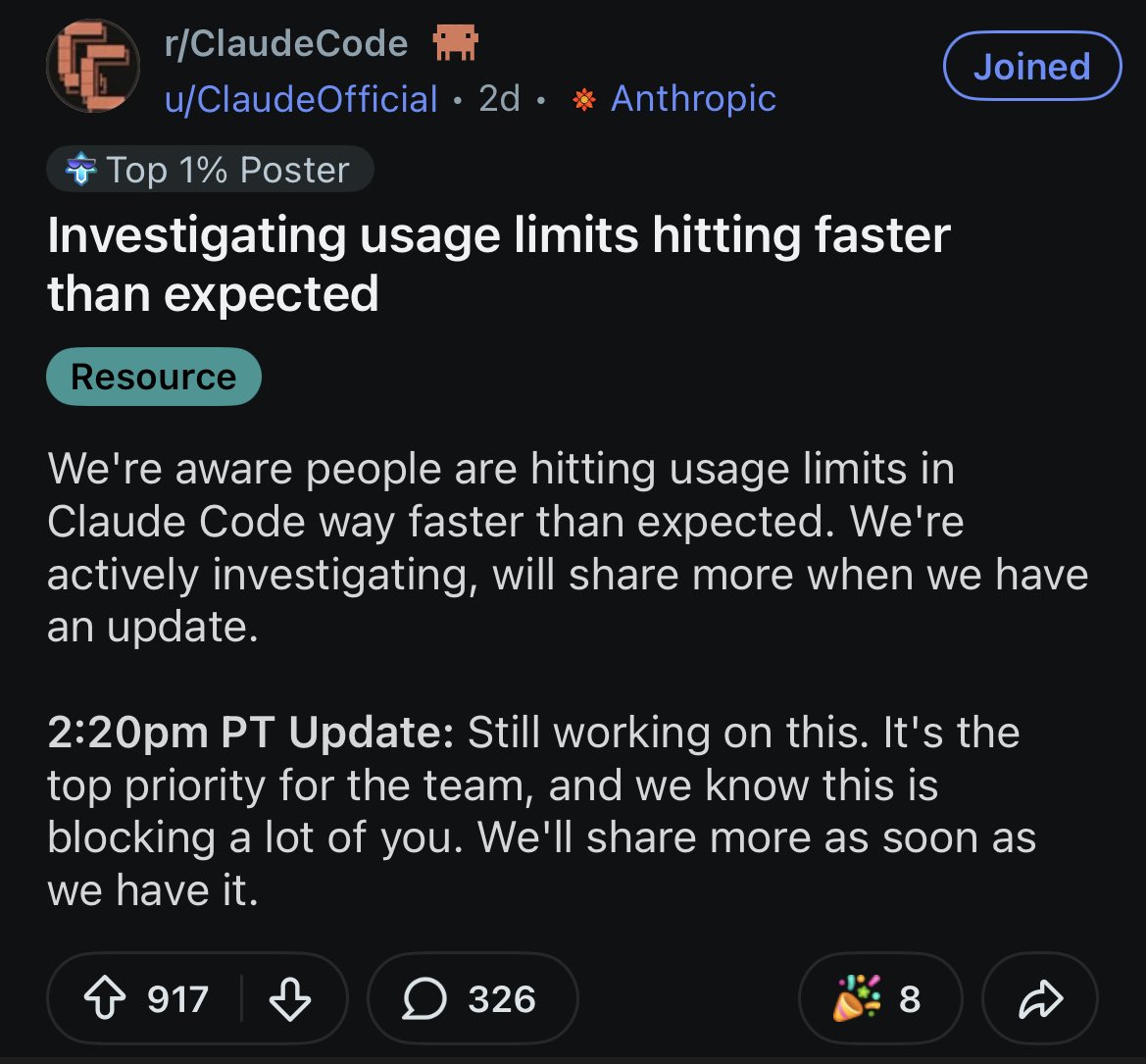
First signals from Anthropic 🤓
Mar 30

We're aware people are hitting usage limits in Claude Code way faster than expected. Actively investigating, will share more when we have an update!
1
33
Mar 27
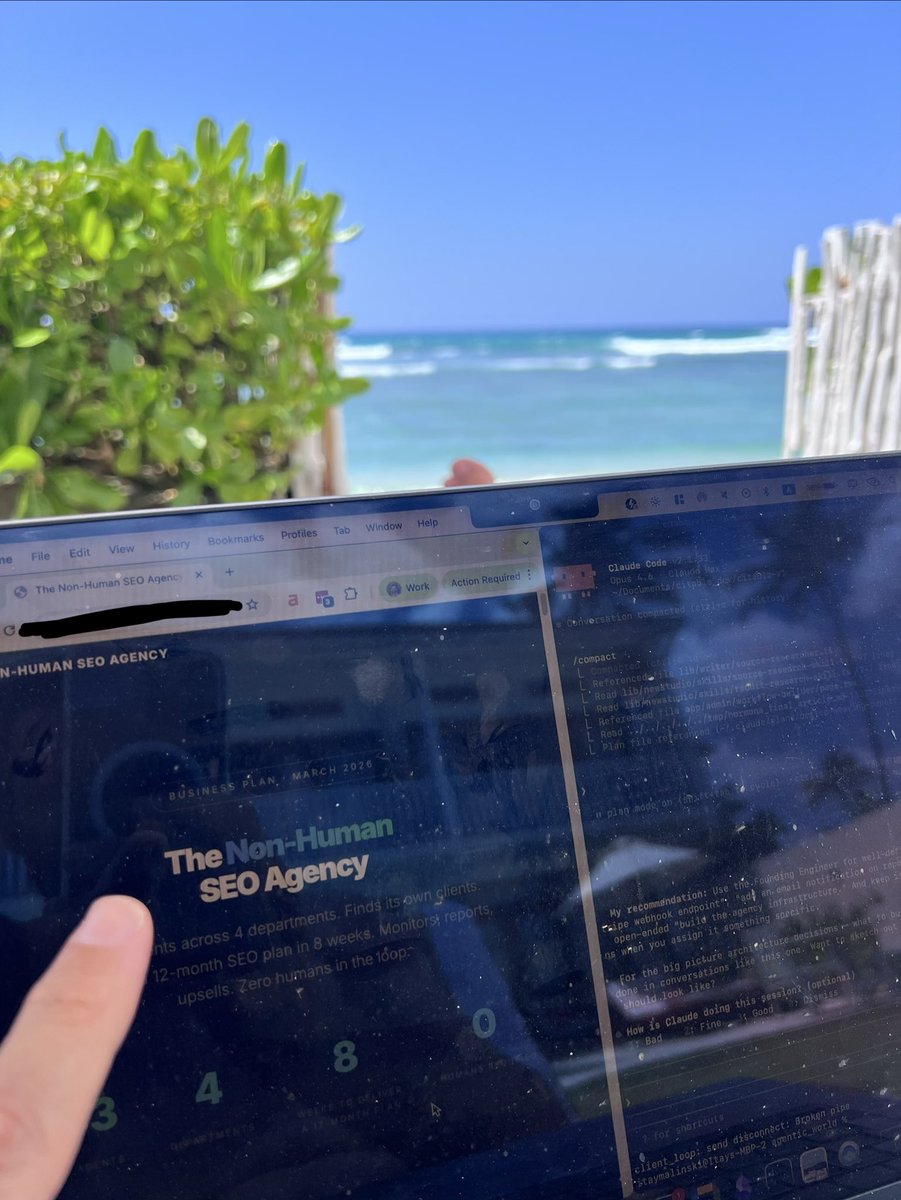
I'm sitting on a beach in Sri Lanka watching my AI agency run itself.
Here's what just happened in 30 minutes while I was in the water:
8 specialized AI agents — orchestrated on Paperclip — audited 15 moving companies in New York.
They crawled their sites. Pulled competitor traffic data. Found the exact technical issues killing their rankings. Wrote a dev-ready fix ticket for each one.
Then a 9th agent wrote 5 personalized cold emails per company.
Email #2 includes the ticket. Something like:
"P.S. I pulled one issue ready to send to your dev team right now: 14 pages have the wrong canonical tag. Here's the fix."
15 companies. 75 emails. 15 dev tickets. All done.
I didn't write a single word. I didn't send a single email. I picked the niche, pressed launch, and paddled out.
This is what a non-human SEO agency looks like in 2026.
We're just getting started. 🦞
50
Mar 26
I built an AI-powered SEO audit pipeline. 8 agents, 80 checks, competitive intelligence across entire markets. It runs, it works, it finds real issues.
I cannot figure out how to let someone else use it.
I'm not a beginner, I've built internal tools with auth, dashboards, APIs. 20 years in SEO, 2 years vibe-coding with AI. Built and sold an agency.
But there's a gap between "works on my server" and "public product with trials, billing, multi-tenant, proper security."
What I actually need:
→ A boilerplate that handles: auth, multi-tenant, billing/trials, API keys, usage limits, role-based access, proper security
→ A way to wire my Python/Node backend into a frontend people can actually use
→ Something that doesn't take 3 months to set up before I can ship the actual product
I don't need to learn React from scratch. I need the infrastructure layer so I can plug in my domain expertise and ship.
Non-dev founders who've shipped public products:
Did you use an existing boilerplate?
Built your own?
Found a technical co-founder?
Something else entirely?
Genuinely asking. Every product idea I have dies at this exact step. Thanks guys!
🏄♂️ Building from Sri Lanka
3
4
81
Mar 26
I built an AI-powered SEO audit pipeline. 8 agents, 80 checks, competitive intelligence across entire markets. It runs, it works, it finds real issues.
I cannot figure out how to let someone else use it.
I'm not a beginner, I've built internal tools with auth, dashboards, APIs. 20 years in SEO, 2 years vibe-coding with AI. Built and sold an agency.
But there's a gap between "works on my server" and "public product with trials, billing, multi-tenant, proper security."
What I actually need:
→ A boilerplate that handles: auth, multi-tenant, billing/trials, API keys, usage limits, role-based access, proper security
→ A way to wire my Python/Node backend into a frontend people can actually use
→ Something that doesn't take 3 months to set up before I can ship the actual product
I don't need to learn React from scratch. I need the infrastructure layer so I can plug in my domain expertise and ship.
Non-dev founders who've shipped public products:
Did you use an existing boilerplate?
Built your own?
Found a technical co-founder?
Something else entirely?
Genuinely asking. Every product idea I have dies at this exact step. Thanks guys!
🏄♂️ Building from Sri Lanka
2
45
itaymalinski retweeted

Mar 22
The most honest benchmark for agentic reliability I've seen in a while. If seven specialized agents all fail gracefully on an empty React shell, that's actually good system design. The real failure mode is agents that hallucinate content that isn't there. What does your pipeline do when the inputs are garbage?
2
1
1
61
Mar 23
I feel like my internet is dead. 🥵
Mar 23

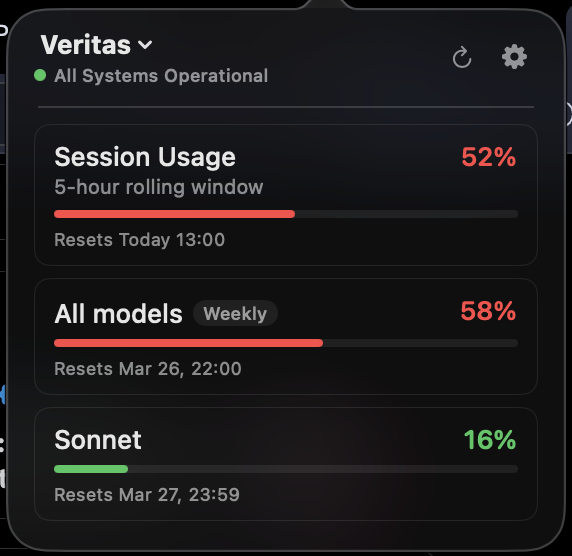
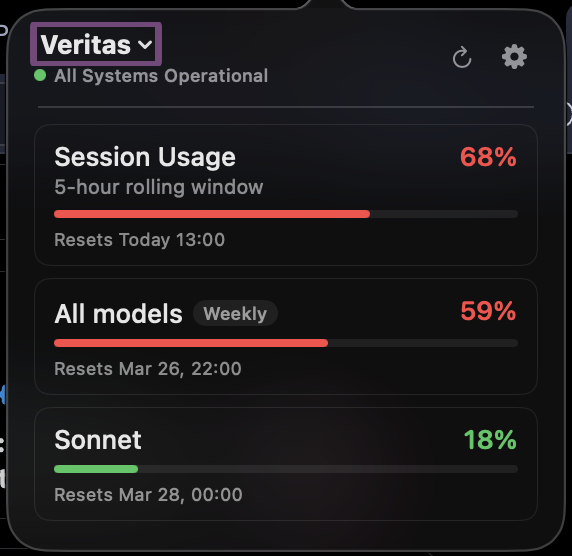
Something is up with Claude Code usage today. $200 Claude Max, 0%, 52% to 62%, then 68%, 76% and 84% in 5-hour rolling window in the time it took me to write this tweet. WTF, @AnthropicAI? I'm working on one GitHub PR for regression testing. Not folding proteins to cure cancer.
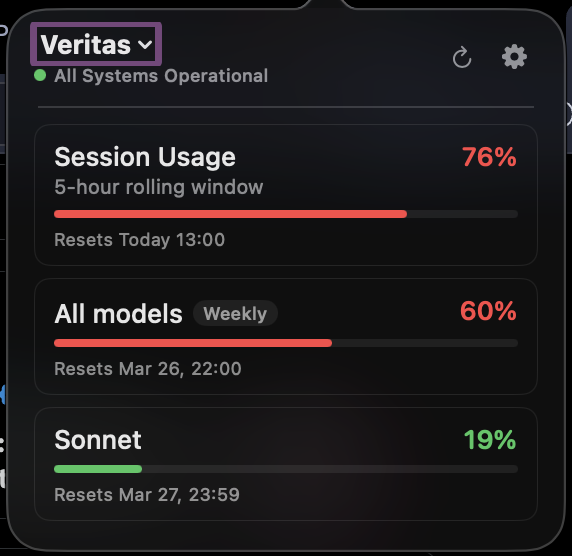
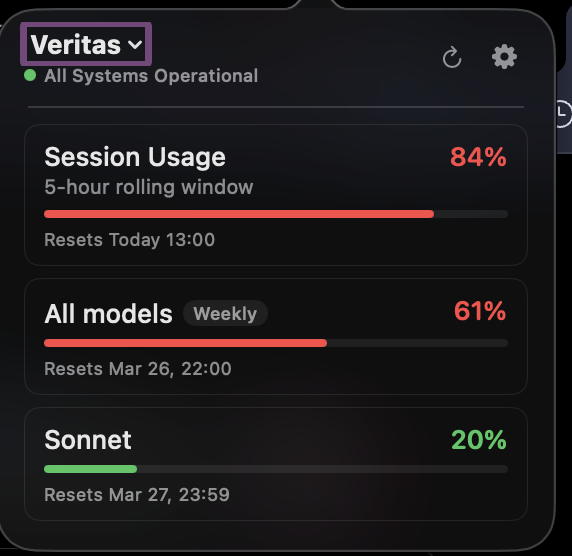
1
78
Mar 22
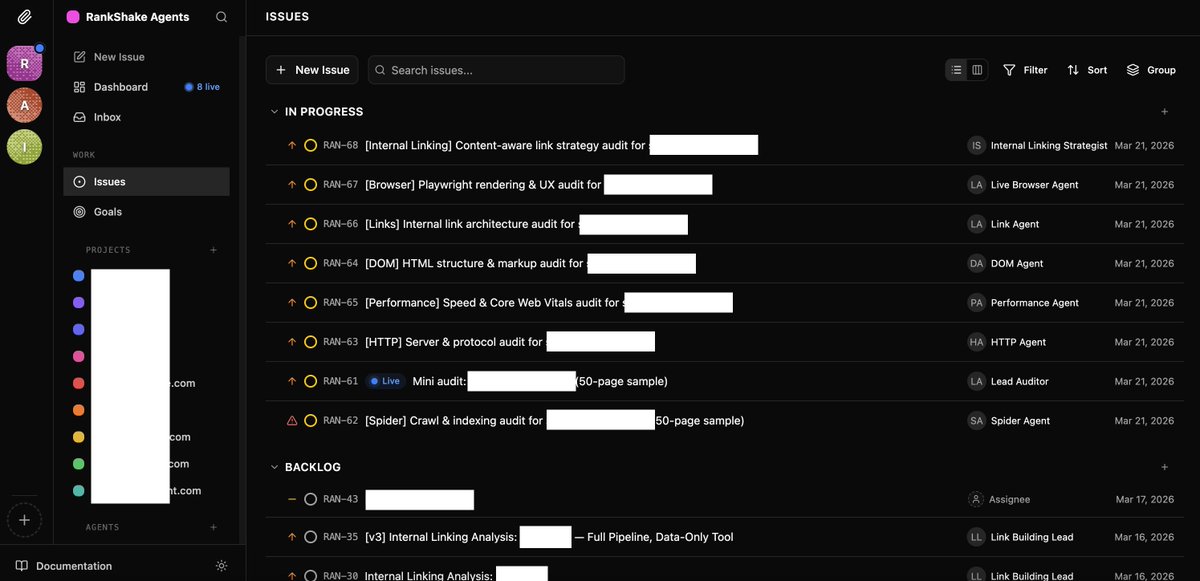
My AI agents audited a website. 7 specialists dispatched. 50 pages crawled. Results came back.
The difference between a workflow, and agentic pipeline with a brain.
Every single agent said the same thing: "I can't do my job. There's no content."
The site was a React SPA. Our Spider crawled it with curl. Got back empty HTML shells. Every page: same title, same canonical, 12 words of content. A div with id="root" and nothing else.
The DOM agent couldn't check titles. They were all identical.
The Links agent found zero internal links. The graph was empty.
The Performance agent saw a 4KB shell loading a 2MB JavaScript bundle.
The IL Strategist said "all pages have zero crawlable content."
Every agent correctly identified the root cause: no server-side rendering. But none of them could do their actual job.
So I asked all 7 agents: "Based on this audit, what tool improvements would help you do your job better?"
Spider: "I need Playwright rendering so I can save what the page actually looks like after JavaScript runs."
DOM: "Give me both versions. Raw HTML AND rendered HTML. I want to compare them."
Performance: "I need CrUX API and PageSpeed Insights API keys for real-world performance data."
IL Strategist: "I need a URL validator script and rendered content to find link opportunities."
Links: "The link graph was empty because all links are generated by JavaScript. I literally had nothing to analyze."
The Lead Auditor collected all the feedback and created a backlog. Prioritized by impact. P0: Spider needs JavaScript rendering. Without it, every CSR site audit is useless.
So we planned it. Not a quick hack. A proper engineering spec:
Pre-crawl: sample 10 pages. Fetch each with curl AND Playwright. Compare 6 signals: canonical, title, word count, H1, meta description, paragraph count. If static matches rendered, skip Playwright for the full crawl. If they don't match, trigger full JS rendering.
Three modes: SSR (curl only, fast), CSR (Playwright, thorough), Hybrid (smart mix). The Lead decides which mode based on Spider's pre-check. Every sub-issue gets the mode. Every finding gets tagged: found in static HTML, found after rendering, or found in both.
The agents didn't just find the problem. They told us what to build. They prioritized it. They wrote the requirements. The engineering loop runs itself.
This is what "self-improving agents" actually means. Not marketing fluff. Real agents hitting real walls and creating real engineering tickets to tear those walls down.
Next: build the rendering detector, update the crawler, re-run the audit on the same site. Compare before and after. See what the agents find when they can actually see the content.
I'm going to surf. The agents will plan, build, implement, and test.
1
2
64
Mar 21
Totally surprised with the findings of our technical auditing agents ❤️🐳 After 10 audits it decided on itself that it will create a set of checks based on the framework/CMS.
So now, if website is running on Wordpress it will create specific checks. Amazing
1
23
Mar 21
Ok. The agency is running. 😄
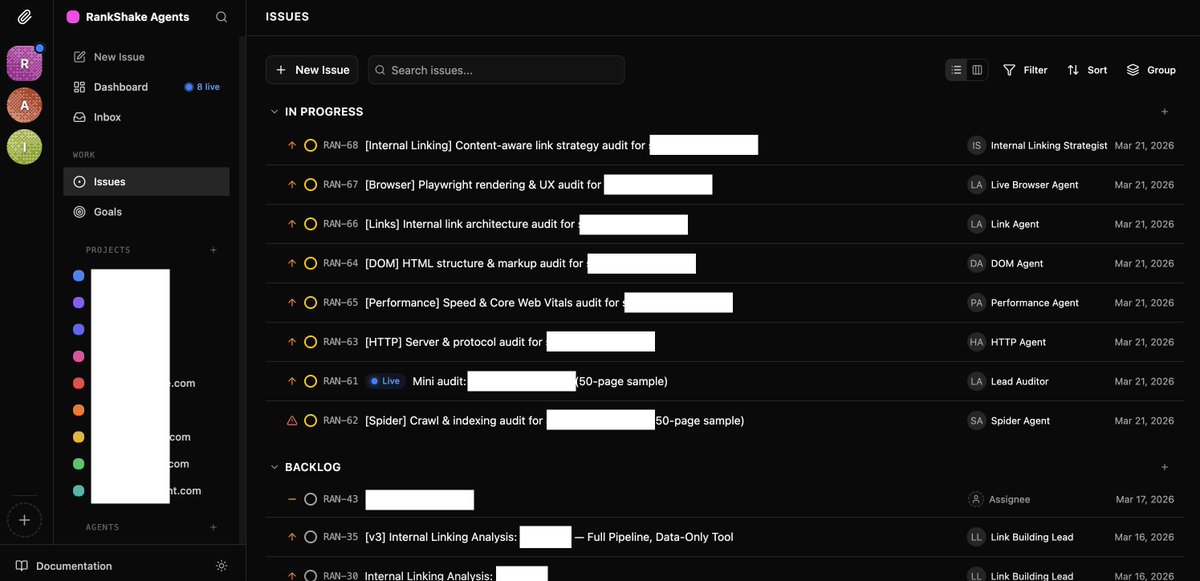
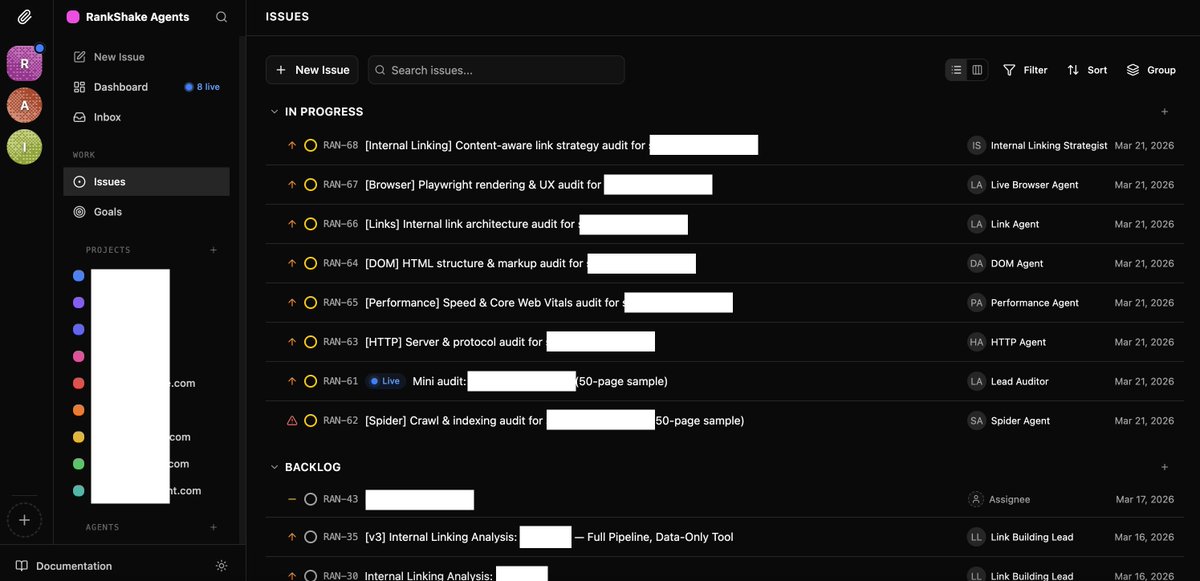
The technical SEO department is stable and auditing real sites. Here's how it works:
One task goes to the Lead Auditor: "Audit domain .com ".
The Lead doesn't do the work. It delegates.
First it dispatches the Spider to crawl 50 pages. Spider comes back: "871 pages discovered, 50 sampled, text extracted, link graph built. 16 seconds."
Then the Lead dispatches 5 specialist agents in parallel. HTTP, DOM, Performance, Links, Browser. Each runs its own checks against the crawl data.
Every finding comes back to the Lead for quality control. False positives get removed. Severity inflation gets downgraded. Only verified findings make it into the report.
50 pages. 81 checks. Dev-ready tickets. A grade.
No human touched the audit. The Lead managed the whole team through Paperclip issues. Created sub-tasks, assigned agents, reviewed output.
Week 1 of the non-human SEO agency. The pipeline works. Now scaling it.
Running on Paperclip by @dotta and @openclaw with @claudeai
1
2
28
Mar 20
$3,000 to $10,000 and 4 to 6 weeks. That's what a traditional SEO audit costs.
Mine takes a few hours.
Not because the AI is smarter. Because I spent 20 years learning how to audit a website, then encoded every rule into agents that execute it consistently.
Here's how. (thread)
2
1
41
Mar 20
Think of it like hiring a brilliant new grad.
They know everything about SEO. Read every blog, every Google patent.
But on day one they'll flag a 302 redirect as an emergency when it's intentional. They'll call every issue "critical."
You don't fire them. You give them SOPs, a manager, a feedback loop.
That's agentic SEO.
1
30
Mar 20
Read everything in the full post :) Hope you like it! Share some love if you did. More to come soon! 🏄
14