
Joined November 2025
- Tweets 571
- Following 129
- Followers 1,445
- Likes 535
16 Photos and videos
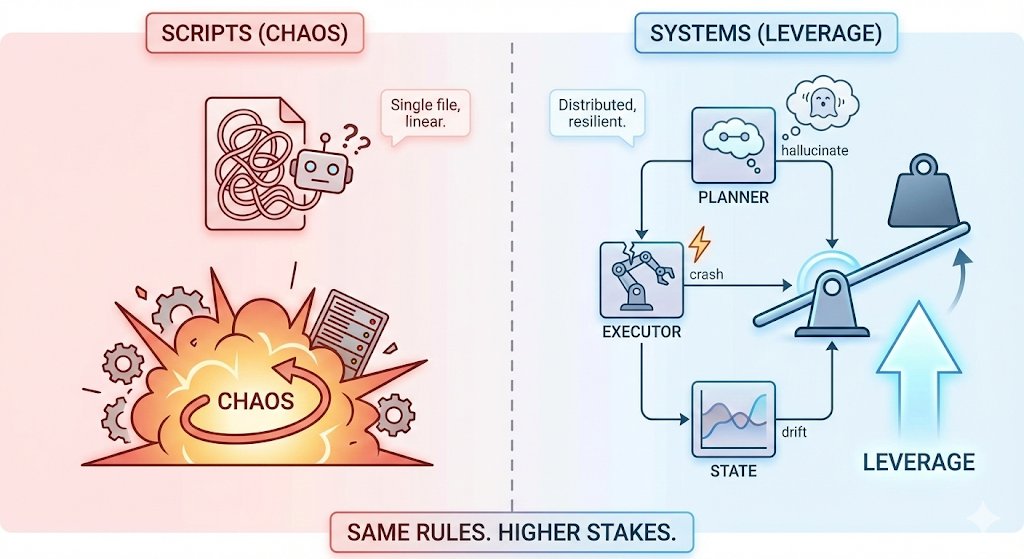
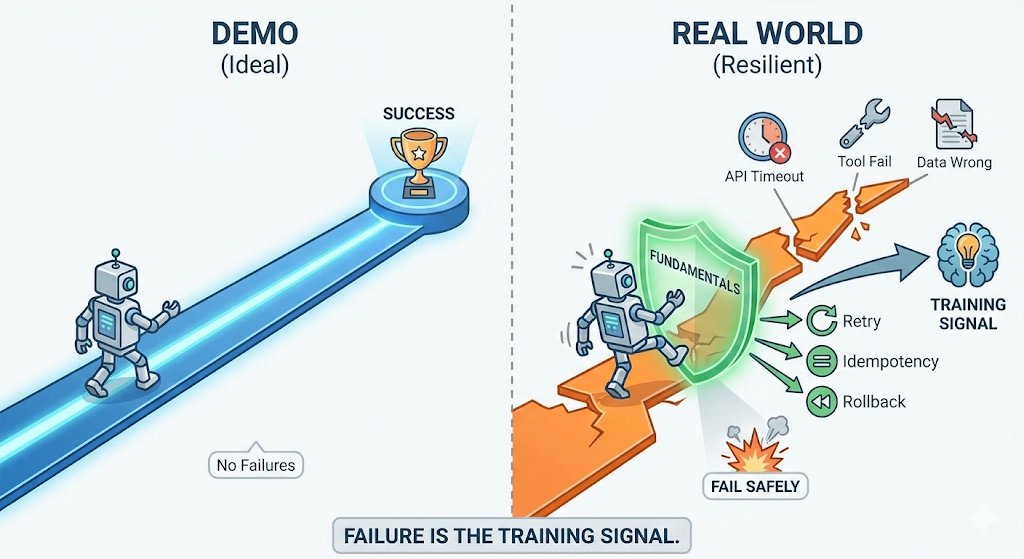
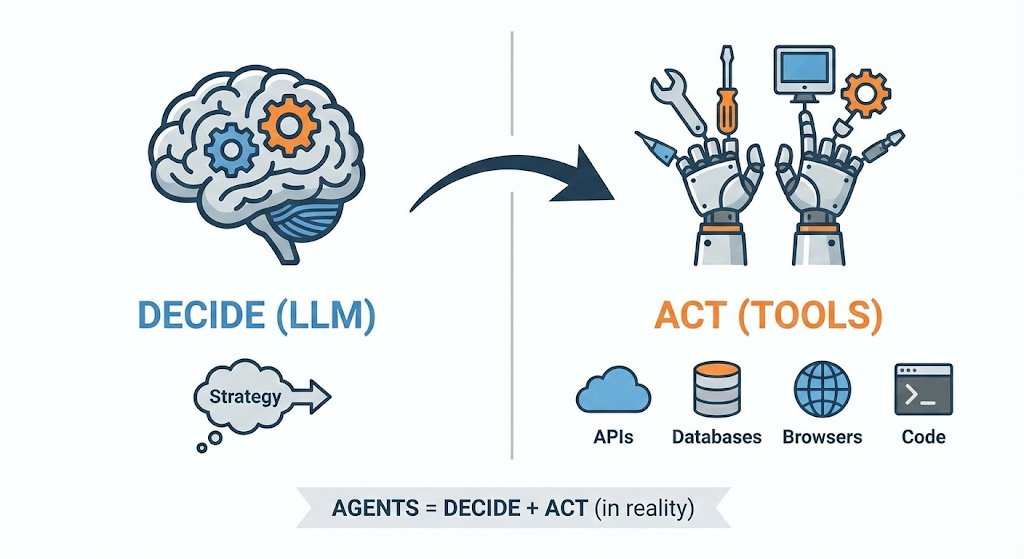

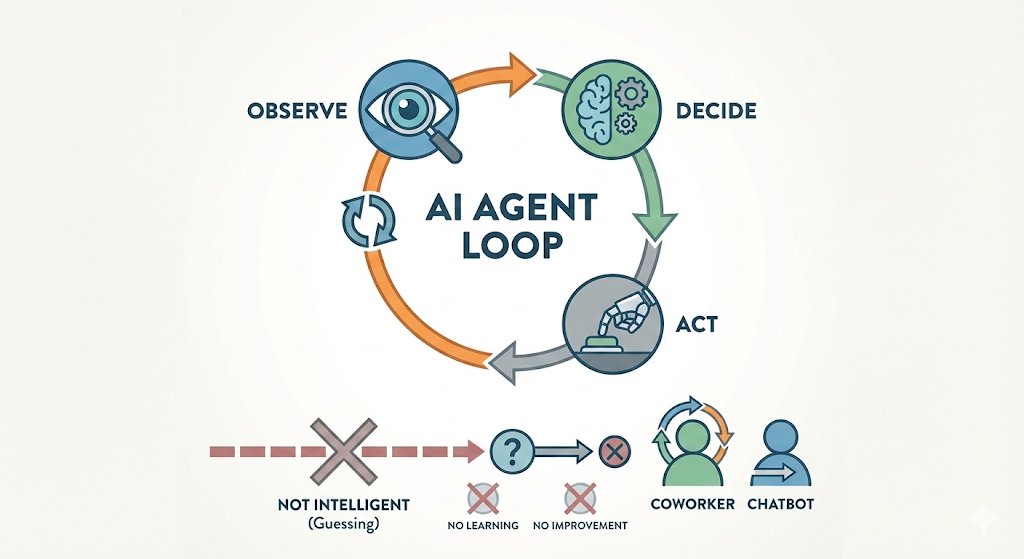
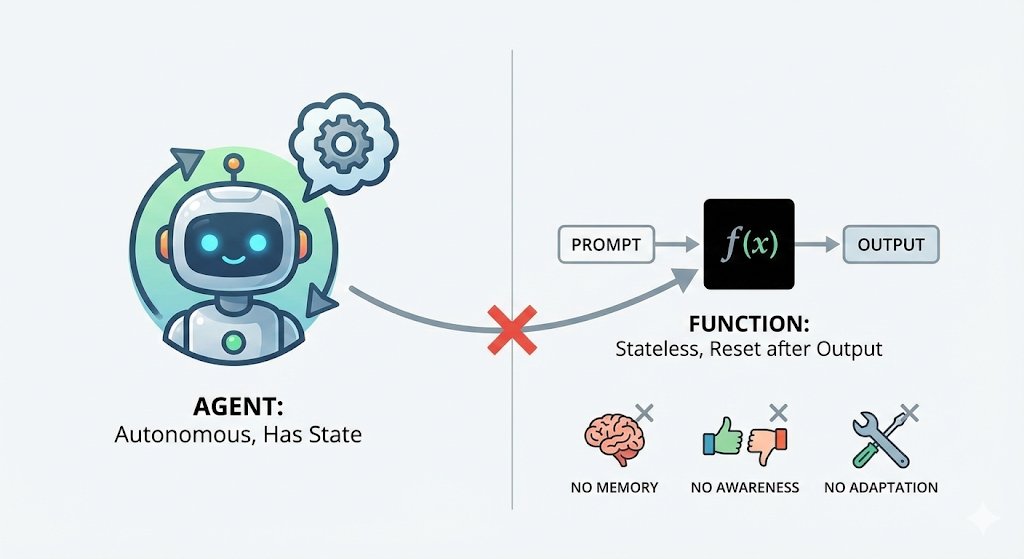
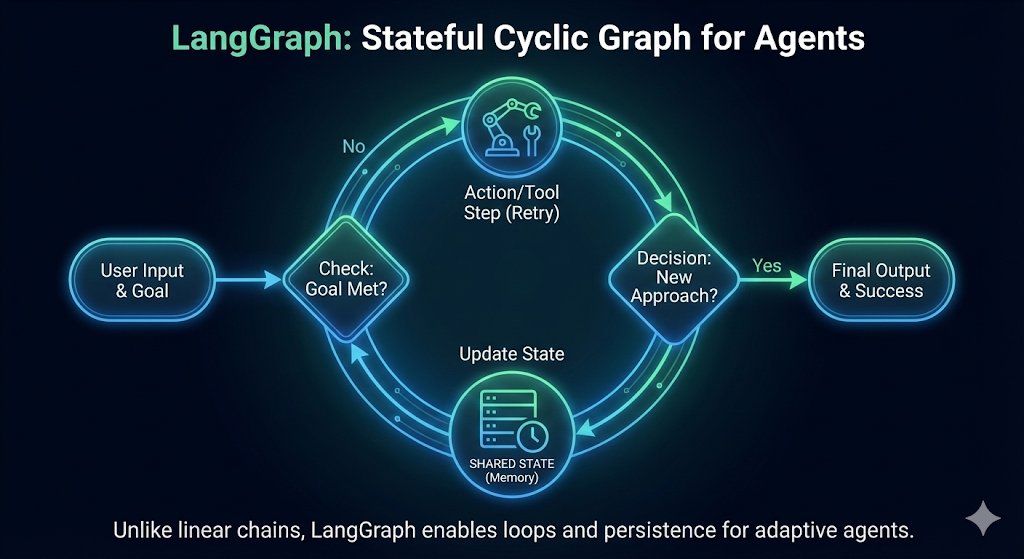
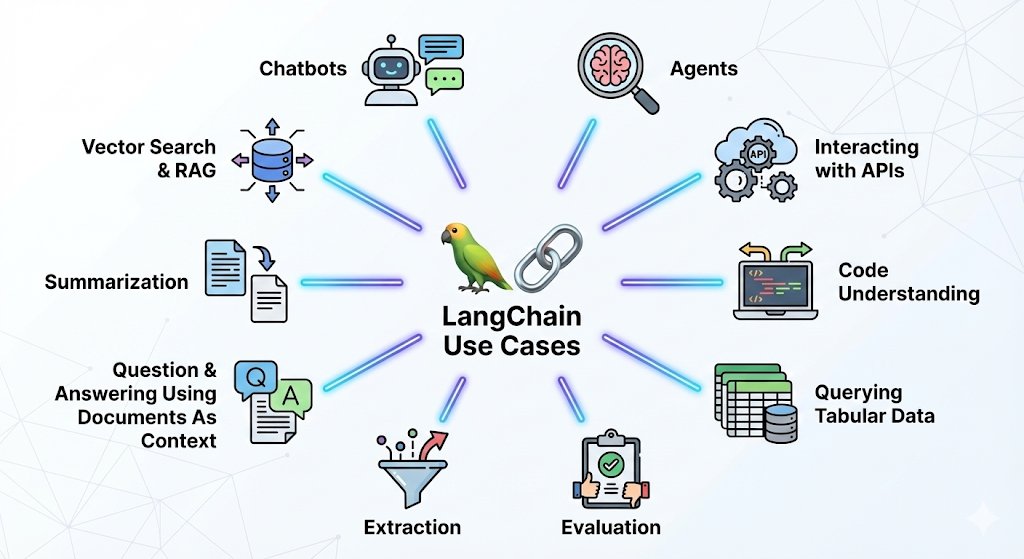
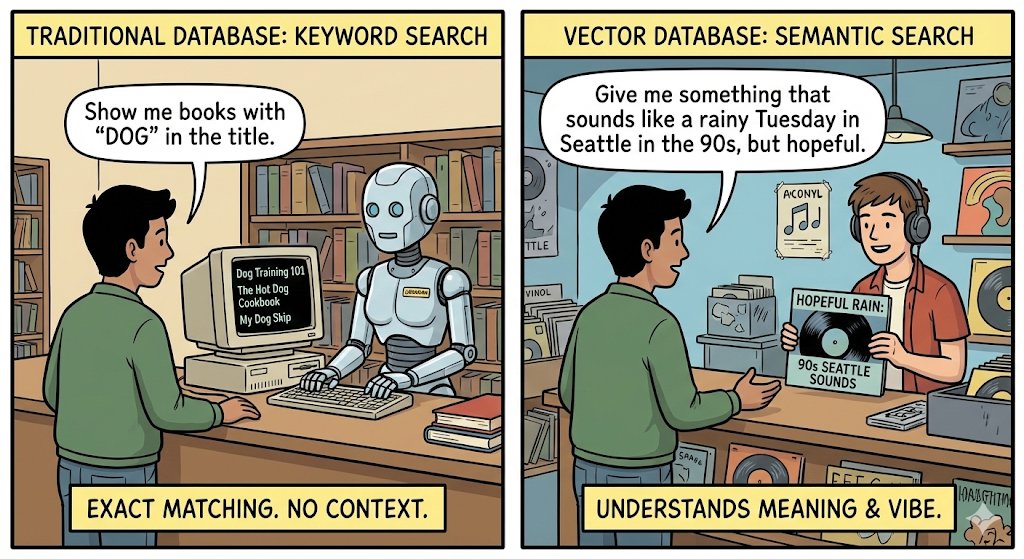
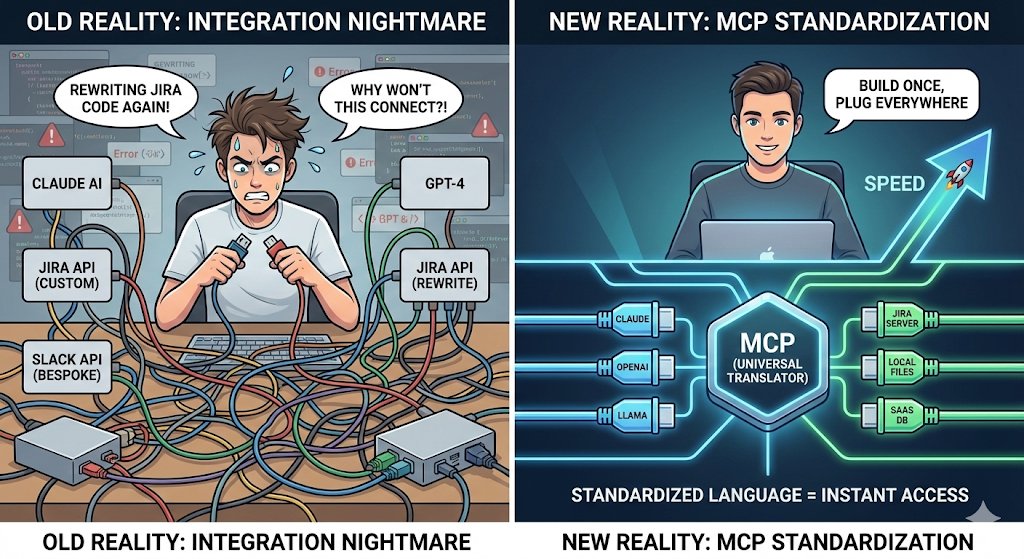

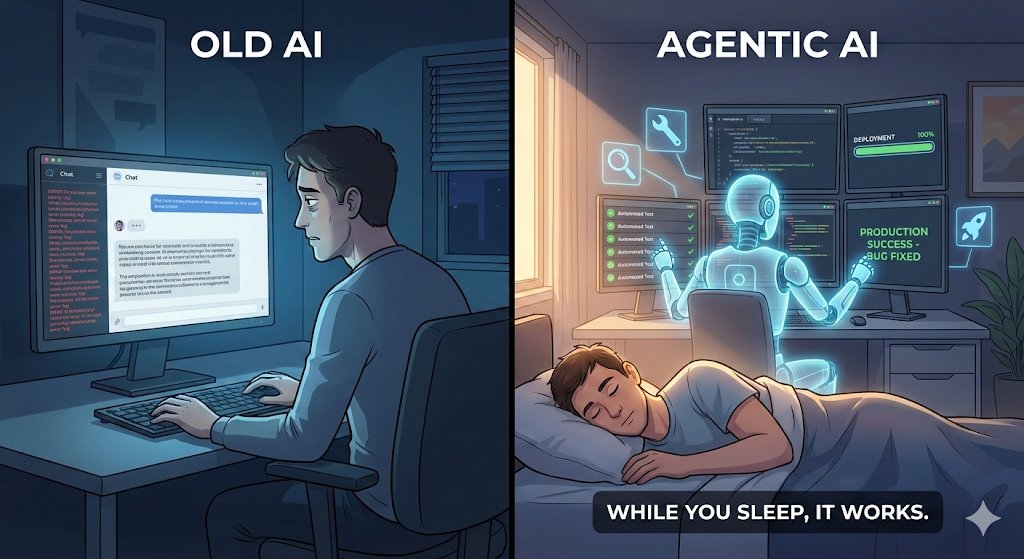
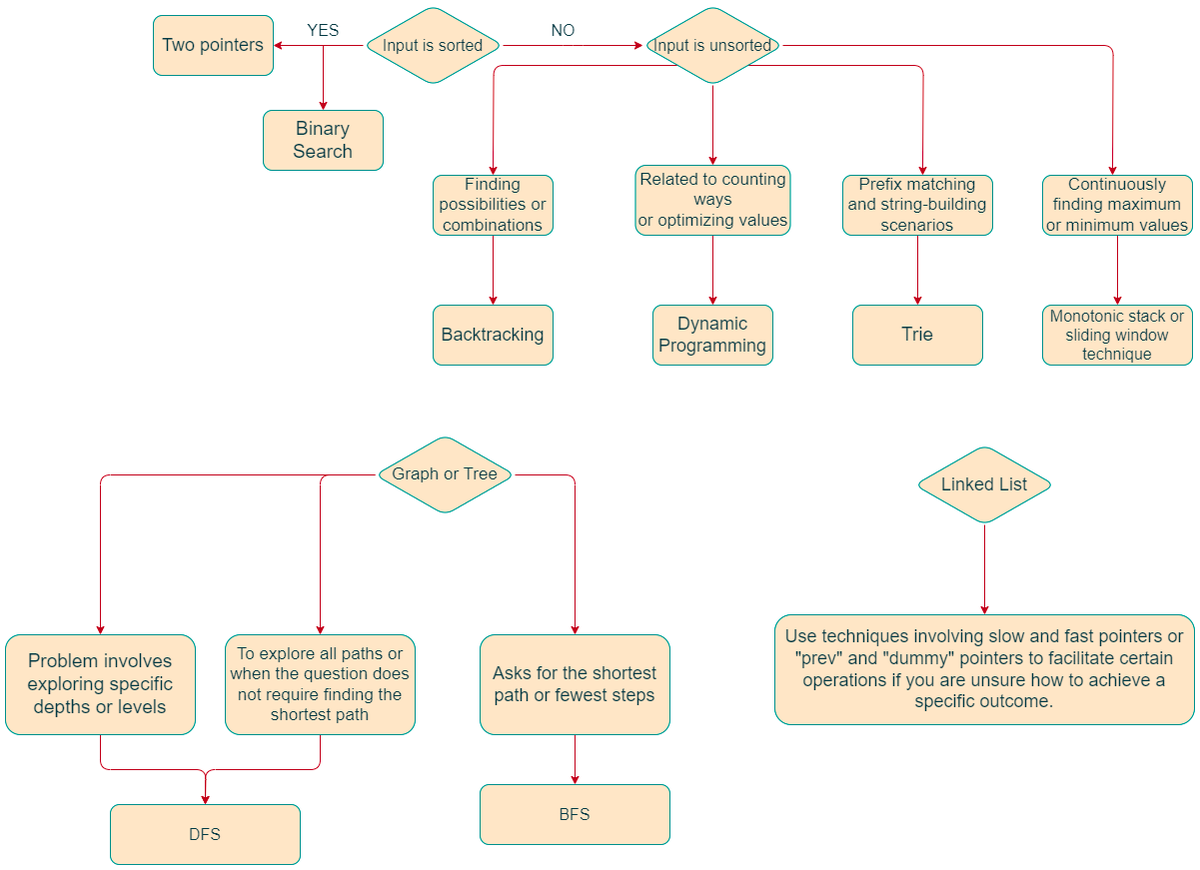
Pinned Tweet

Jan 10
> Because using an index doesn’t automatically mean the query is cheap.
> Here’s what’s really happening.
1. Low selectivity kills index benefits
> If a large percentage of rows have status = 'COMPLETED' (say 40–70%):
- The index does help find matching row IDs
- But it still has to return millions of matches
> At that point, an index scan is barely better than a full scan.
> Indexes shine when they eliminate most rows, not when they match half the table.
2. SELECT * forces heap lookups
> Your index is on status only.
> So the DB does:
- Scan the index to find matching row IDs
- For each match, fetch the full row from the table (heap)
> That means:
- Millions of random I/O reads
- Cache misses
- High latency
> The index helps filtering, but fetching the rows dominates the cost.
3. Index scan ≠ index-only scan
> EXPLAIN says Index Scan, not Index Only Scan.
> Why that matters:
- Index-only scans can avoid touching the table
- But SELECT * requires reading the heap
- So the DB can’t stay inside the index
4. The data may not be cache-resident
> If the working set doesn’t fit in memory:
> Every heap fetch hits disk
> Even SSDs will struggle at this scale
> 3–4 seconds is very believable
5. The index helps the planner, not the physics
> The planner chose the index because it’s slightly better than a full scan.
> But physics still applies: you’re reading a huge amount of data.
> What actually fixes it
- Don’t SELECT *, fetch only needed columns
- Use a covering index (include needed columns)
- Filter on more selective predicates
- Partition by status or time
- Pre-aggregate or move “COMPLETED” orders to cold storage
Takeaway:
- Indexes are about reducing work.
- If your predicate matches millions of rows, the work is still massive.
> An index can be used and the query can still be slow, and this is exactly that case.
> Index scans are fast when they return few rows.
When they return many, they can be slower than a full table scan.
8
12
156
18,138
DesignToBuild retweeted
Jan 19
Short Answer:
1. It’s synced backend state, not just local storage
2. Local storage can’t work across devices
3. Netflix stores progress per profile on the server
4. Client sends periodic heartbeat updates while watching
5. Backend handles massive write volume (Cassandra/DynamoDB)
6. Latest valid progress usually wins
7. Short accidental plays are ignored
8. Offline progress syncs when back online
9. Local storage is only a cache / UX optimization
10. Source of truth = server, not the device
3
67
14,186
DesignToBuild retweeted
Jan 24
• Small, static data → Offset.
Don't over-engineer. If the data isn't moving, LIMIT and OFFSET are quick to build and work perfectly fine.
• Large, growing data → Keyset (Cursor).
Offsets get slower the deeper you go. Cursors keep queries fast by jumping straight to a specific record.
• Real-time feeds → Cursor.
Offset pagination causes "item drift." If a new post drops while you're scrolling, you'll see the same content twice. Cursors fix this.
• Search results → Offset.
This is the one place users actually want page numbers. Search engines (like Elasticsearch) are optimized to handle these jumps.
• Infinite scroll → Cursor.
The UX is seamless. Just pass a next_token to the frontend and keep the data flowing without tracking page math.
• Sharded DBs → Keyset.
Offsets are a distributed systems nightmare. Cursors allow you to query across shards efficiently without massive data overhead.
1
4
19
1,953
DesignToBuild retweeted
Jan 24
Both queries are different.
1. WHERE salary = NULL
• The Result: Returns nothing (Empty set).
• The Logic: In SQL, any comparison to NULL using a standard operator (=,>,<) results in a state called UNKNOWN.
• The "Why": Since NULL represents an unknown value, the database logic is: "I don't know what the salary is, and I don't know what this other thing is, so I can't say they are equal." Even NULL = NULL is false (or rather, unknown) in SQL.
2. WHERE salary IS NULL
• The Result: Returns all rows where the salary column is empty/null.
• The Logic: This uses a specialized comparison operator designed specifically to check for the presence of the NULL state.
• The "Why": This is the proper syntax to ask the database: "Does this cell have a value or not?
10
18
716
87,859
DesignToBuild retweeted
Jan 25
A preflight request is a safety check done by the browser before making certain cross-origin requests.
In simple words:
The browser asks the server, “Am I allowed to make this request?”
How:
1. Your frontend wants to call an API on a different origin
2. The request is not simple (e.g. uses PUT, DELETE, custom headers, or JSON)
3. The browser first sends an OPTIONS request (this is the preflight)
4. The server replies with CORS headers saying what’s allowed
5. If allowed → browser sends the real request
If not → browser blocks it
Why it exists:
1. Prevents malicious websites from abusing APIs
2. Enforces CORS security rules
3. Protects users without breaking API
2
7
36
2,353
DesignToBuild retweeted
Jan 25
> SSL (TLS) Handshake is the process where your browser and a server introduce themselves, verify trust, and agree on how to talk securely.
> In simple words:
It’s the “security setup” that happens before any real data is sent.
> Flow:
1. Client says hello
- “I want to connect securely”
- Shares supported encryption methods
2. Server responds
- Sends its SSL certificate
- Says which encryption it chose
3. Client verifies the server
- Checks the certificate with trusted authorities
- Confirms: “Yes, this is really the server I wanted”
4. Secret key is created
- Client and server agree on a shared secret
- This key is known only to them
5. Secure communication starts
- All data is now encrypted
- Outsiders can’t read or modify it
Why it matters:
- Prevents eavesdropping
- Prevents man-in-the-middle attacks
- Ensures you’re talking to the right server
> One-line summary:
SSL Handshake establishes trust and encryption before data exchange.
2
19
216
19,094
DesignToBuild retweeted
Jan 19
Detailed Answer:
It’s synced state, not just local storage.
1. Local storage alone is insufficient
- Local storage exists only on one device. If Netflix relied on it, you couldn’t pause on your TV and resume on your phone. Cross-device resume requires a backend source of truth.
2. Playback progress is a backend concept
Netflix tracks viewing progress per profile, not per device. The backend stores:
- profile ID
- content ID
- last watched timestamp
- completion state
This is what enables seamless resume anywhere.
3. Continuous syncing via heartbeats
- The client doesn’t just update progress on pause. While you watch, the player sends periodic heartbeat events (every few seconds, on pause, exit, or app close). This avoids losing progress if the app crashes or the device dies.
4. Write-heavy backend design
- Millions of users constantly updating progress creates massive write load. Netflix uses write-optimized distributed stores (e.g., Cassandra/Dynamo-style systems) designed to absorb frequent updates and converge on the latest state.
5. Offline support
When offline:
- Progress is stored locally
- On reconnect, the client syncs and merges with
backend state
6. Why local storage still matters
Local state improves UX:
- Instant resume on the same device
- Offline playback
- Smoother seeking
But it’s never the source of truth.
Takeaway:
Local storage = optimization
Backend state = truth
8
25
442
62,868
DesignToBuild retweeted
Jan 19
- This is a classic OLTP vs OLAP mismatch.
- The database is optimized for OLTP (transactions).
The requirement is OLAP (analytics).
- Trying to make a transactional database do both at scale is why performance suffers.
- Here are 3 ways to fix it, ranked by complexity:
1. Quick fix: Materialized Views
If 1 - 5 min staleness is acceptable:
- Precompute expensive joins
- Store results as a materialized view
- Refresh periodically (concurrently)
- Dashboards query a flat table → fast
2. Real-time fix: Aggregate on write (Redis)
If “real-time” means sub-second:
- Don’t count rows, count events
- Update counters on every write
- Dashboard reads Redis → O(1)
- Reconcile periodically with DB (counters drift)
3. Scalable fix: CDC Analytics DB
If slicing/filtering is needed at scale:
- Stream DB changes via CDC (e.g. Debezium)
- Load into ClickHouse / Elasticsearch / Snowflake
- Run analytics there, not on the primary DB
Summary:
- MVP / low traffic → Materialized Views
- Strict real-time → Redis counters
- Complex analytics → CDC OLAP store
Normalize for writes.
Denormalize for reads
1
7
46
3,111
DesignToBuild retweeted
Jan 22
Short Ans:
It’s not magic. It’s a pipeline:
1. Detection – Finds faces in photos (MTCNN / BlazeFace).
2. Alignment – Normalizes the face (eyes level, scale fixed).
3. Embedding – Converts each face into a 128-D vector (FaceNet).
4. Clustering – Groups faces by small Euclidean distance.
2
8
784
DesignToBuild retweeted
Jan 22
It’s not magic. It’s a pipeline
1. Detection (The Locator)
First, it solves "is there a face?" It uses lightweight models (like MTCNN or BlazeFace) to scan the image.
• Input: Full raw image.
• Output: Bounding box coordinates around the face.
2. Alignment (The Standardizer)
Neural networks hate variation. If your head is tilted, the math changes. The system uses landmarks (eyes, nose) to rotate and crop the image.
• Goal: Ensure eyes are always at the same pixel coordinates.
• Result: A normalized, frontal-facing input.
3. Embedding (The Translation)
This is the core logic (FaceNet). The image passes through a Deep CNN that compresses the face into a 128-dimensional vector (an array of numbers).
• The logic: It maps visual features to numerical coordinates.
• Key concept: It uses "Triplet Loss" to ensure your face always yields similar numbers, regardless of age or lighting.
4. Clustering (The Grouping)
The system doesn't "match" Photo A to Photo B directly. It plots all your photos in a vector space.
• It looks for dense clouds of points (vectors) that are close together.
• Euclidean Distance: Small distance = Same person. Large distance = Different person.
To the AI, you aren't a face. You are just a cluster of points in a 128-D vector space.
3
17
1,118
DesignToBuild retweeted
Jan 23
• Tables are Sets: In relational theory, a table is an unordered set; there is no "default" order.
• No ORDER BY: Without this clause, the database engine returns rows in the most efficient way it finds.
• Physical Storage: Rows are stored in data pages; if a row is updated or deleted, its physical position on disk may change.
• Full Table Scans: A sequential scan starts at the first page, but the "first" page can change after maintenance or vacuuming.
• Multithreading: Modern DBs use parallel workers; whichever thread fetches its segment first determines the initial rows.
• Buffer Cache: If some rows are already in memory, the DB might serve those first to fulfill the LIMIT quickly.
• Index Selection: The optimizer might use a different index today than it did yesterday based on updated statistics.
• Insert Fragmentation: New data isn't always appended to the end; it often fills gaps left by deleted records.
• Database Type: Different engines (Postgres vs. MySQL vs. Oracle) have different background processes that shuffle row visibility.
• Deterministic Results: To guarantee the same order every time, you must explicitly use ORDER BY on a unique column
1
3
40
3,939
DesignToBuild retweeted
Jan 24
Instagram’s Story ranking prioritizes Relationship Scoring over recency to maximize your time spent on the app.
Here’s the logic breakdown:
• Affinity > Recency: Relationship scoring is the heaviest weight. A "Best Friend" post from 10 hours ago will almost always beat a stranger's post from 1 minute ago.
• The DM Signal: Direct Messages are the strongest indicator of a real world connection. High DM frequency = permanent front-row seat.
• Completion Rates: The model tracks if you watch a creator’s full Story or swipe "Next." High completion % boosts their rank in your tray.
• Intentionality: If you search for a profile specifically, the algorithm interprets this as high intent and moves them up.
• Engagement Loops: Interacting with polls, sliders, or "Likes" on a Story acts as a massive feedback signal to the personalization engine.
• Close Friends Boost: This is a manual override. Adding someone to this list provides a static multiplier to their proximity score.
• The Goal: It’s an ensemble model predicting watch time. The goal is to minimize "churn" (leaving the app) by showing you the most relevant content first.
Instagram doesn't care when it was posted; it cares who posted it and how much you care about them.
2
6
488
DesignToBuild retweeted
Jan 18
1. Auto-increment IDs work great in single, centralized databases
2. They require coordination (DB must assign the ID)
3. UUIDs can be generated anywhere (client, service, offline)
4. UUIDs avoid ID collisions in distributed systems
5. Easier data merging across services & regions
6. Auto-increment IDs leak business data (easy to enumerate)
7. UUIDs are safer for public APIs
8. Many systems use both: internal ID public UUID
9. Auto-increment optimizes DBs; UUIDs optimize systems
20
24
625
43,251
DesignToBuild retweeted
Jan 14
No. It causes a compilation error.
The Logic:
The JVM guarantees that only the thread creating the object can see it until the constructor finishes. There’s no shared object to lock yet.
Why it’s disallowed:
- During construction, the object isn’t visible to other threads
- Only the creating thread can access it until the reference escapes
So synchronizing a constructor is both unnecessary and disallowed.
1
2
30
2,955
DesignToBuild retweeted
Jan 17
This is a classic 'Offset Pagination' pattern to keep the app performant.
The server translates this into a DB query:
SELECT * FROM orders LIMIT 10 OFFSET 20;
Essentially: "Ignore the first 20 records and fetch the next 10." Great for infinite scrolls or "Next Page" buttons.
3
43
5,869
DesignToBuild retweeted
Jan 11
This is a logical memory leak.
Objects are no longer needed, but references to them are still alive, so the GC can’t reclaim the memory. Heap usage keeps growing, GC runs more often, but there’s no OutOfMemoryError.
Common causes:
- Caches without eviction
- Static collections
- Unremoved listeners
- Uncleared ThreadLocals
- Long-lived objects holding short-lived ones
2
11
1,769
DesignToBuild retweeted
Jan 12
1. Token
A token is the smallest unit the model actually reads and writes.
It’s not exactly a word.
For example:
•"hello" → 1 token
•"unbelievable" → might be ["un", "believ", "able"]
•Code, emojis, spaces — all become tokens.
Why engineers care:
•Cost = tokens
•Latency = tokens
•Limits = tokens
If you exceed the token limit, the model literally cannot see the rest of your input.
2. Context Window
The context window is how much the model can “remember” at once.
It includes:
•Your prompt
•Conversation history
•System instructions
•Retrieved documents (RAG)
Once you cross the window size, older tokens fall off the cliff.
It’s like RAM, not disk.
If it’s not in memory, the model can’t reason about it.
3. Prompt
A prompt is the input you give the model to shape its behavior and output.
This includes:
•Instructions (“Act like a senior backend engineer”)
•Data (logs, code, JSON)
•Constraints (format, tone, rules)
Important truth:
LLMs don’t “understand intent” — they follow patterns.
A bad prompt is like a vague API contract.
4. Embedding
An embedding is a numerical vector representation of text meaning.
Similar text → vectors close together
Different meaning → far apart
Used for:
•Semantic search
•Recommendations
•Clustering
•RAG
Mental model:
Text → vector → math → relevance
This is how machines compare meaning, not keywords.
5. Temperature
Temperature controls randomness.
•0.0 → deterministic, boring, safe
•0.7 → balanced
•1.0 → creative, risky, chaotic
Rule of thumb:
•Use low temperature for code, configs, facts
•Use higher temperature for brainstorming or writing
It doesn’t make the model smarter — just more adventurous.
6. Top-P (Nucleus Sampling)
Top-P limits the model to the smallest set of tokens whose total probability ≥ P.
Example:
•top_p = 0.9 → only consider the most likely 90% of outcomes
Difference from temperature:
•Temperature reshapes probabilities
•Top-P trims the tail of unlikely nonsense
Most production systems tune both.
7. Hallucination
A hallucination is when the model confidently produces incorrect information.
Why it happens:
•Missing context
•No access to source of truth
•Probabilistic guessing under uncertainty
Key insight:
LLMs optimize for plausibility, not truth.
If correctness matters, you must:
•Ground it with data (RAG)
•Add verification
•Reduce temperature
8. LLM (Large Language Model)
An LLM is a neural network trained to predict the next token, at massive scale.
It doesn’t:
•Think
•Reason like humans
•Understand meaning inherently
It does:
•Recognize patterns extremely well
•Compress large amounts of knowledge
•Generate surprisingly useful behavior
Think of it as:
A probabilistic autocomplete trained on the internet.
9. RAG (Retrieval Augmented Generation)
RAG = fetch real data first, then ask the LLM to reason over it.
Flow:
1.User asks a question
2.System retrieves relevant docs (via embeddings)
3.Docs are injected into the prompt
4.LLM generates grounded output
Why engineers love RAG:
•Reduces hallucinations
•Keeps data fresh
•Avoids retraining models
It’s basically LLM database search.
10. Inference
Inference is the act of running the trained model to generate output.
Training = expensive, offline
Inference = cheaper, online, repeatable
Concerns during inference:
•Latency
•Cost per token
•Throughput
•Streaming vs batch
2
3
30
1,765
DesignToBuild retweeted
Jan 13
When a service keeps user state, scaling isn’t really about adding more pods, it’s about where that state is stored.
- Why stateful services struggle to scale?
If session data lives inside the service process:
1. Adding replicas spreads users across instances
2. Requests landing on a different instance lose session context
3. Restarts and deployments wipe in-memory state
4. Load balancers can’t freely route traffic
As a result, horizontal scaling breaks session consistency.
- How to Fix?
Here’s the practical approach:
1. Move sessions out of memory
- Don’t store sessions in the service’s RAM
- Use a shared store like Redis or a database
- Any instance can now serve any user
2. Make the service horizontally scalable
- Run multiple instances behind a load balancer
- Since session state is shared, requests can land
anywhere
3. Avoid relying on sticky sessions
- They limit scaling and break during deployments
- Use them only as a temporary workaround
4. Use consistent session keys
- Session IDs, signing keys, and encryption secrets
must be the same across all instances
- Externalize them via config / secret manager
5. Cache wisely
- Cache session reads with short TTLs if needed
- Always treat Redis/DB as the source of truth
6. Plan for failure
- Session store should be replicated
- Handle Redis failover and reconnects gracefully
Takeaway:
You don’t scale stateful services by adding memory, you scale them by centralizing state and scaling stateless workers around it.
2
22
2,039
DesignToBuild retweeted
Jan 14
It results in a Compilation Error.
You cannot do this because both super() and this() must be the very first statement in a constructor body. Since only one line can be first, they are mutually exclusive.
2
26
2,958
DesignToBuild retweeted
Jan 14
It feels unnecessary at first.
Why add complexity if one token works?
The answer comes down to Security vs Control.
If you issue a stateless Access Token (JWT) that lasts 30 days, you’ve effectively lost control of that user’s session for a month.
1. Revocation
- Access Tokens are stateless. Once signed, you can’t stop them.
- Risk:
> If a 30-day Access Token is stolen (XSS, bad logger),
the attacker is the user for 30 days.
> You can’t revoke it without rotating global signing
keys → logs everyone out.
- Fix:
Keep Access Tokens short-lived (e.g. 15 mins).
If stolen, the attacker only has a 15-minute window.
2. Performance vs Security
- APIs need to be fast.
- Access Tokens are validated with math (CPU only).
- No DB hit on every request.
- Trade-off:
Refresh Tokens force a “check-in” with the Auth Server
every ~15 mins.
- Benefit:
You can ask:
> Is the user still active?
> Did they change their password?
> Are they banned?
3. Reducing the Blast Radius
- Access Tokens are noisy.
- They go in headers to every microservice.
- They hit proxies, logs, browser extensions.
- Refresh Tokens are quiet.
- Sent only to /refresh-token.
- Stored in secure, HttpOnly cookies.
- Much harder to steal.
4. Token Rotation
- Modern systems rotate Refresh Tokens on every use.
- Mechanism:
An old token reused = already “spent”.
- Response:
> Invalidate the entire session immediately.
> You can’t do this with long-lived Access Tokens.
Long-lived Access Tokens feel simple.
They’re also irreversible incidents waiting to happen.
Refresh Tokens aren’t extra complexity, they’re where the control lives.
6
8
191
22,356
DesignToBuild retweeted
Jan 13
This is a common credential stuffing scenario. Since the API is public, it can’t be hidden, the goal is to make abuse hard, slow, and expensive.
What to do:
1. Rate-limit the login endpoint
- Limit by IP and by username
- Do it at the gateway/WAF so bad traffic never hits your app
- This also stops distributed attacks that rotate IPs
2. Add progressive challenges
- Use CAPTCHA / invisible challenges after a few failures
- Humans pass silently, bots get blocked
- Add exponential backoff to slow repeated attempts
3. Detect attack patterns
- Many users from one IP
- Same password across many accounts
- Unusual geo / ASN spikes
4. Be careful with account lockouts
- Hard locks can be abused to lock out real users
- Prefer rate limits, delays, and challenges over
permanent locks
5. Protect at the edge
- Use WAF / CDN bot rules
- Block known bad IPs and data-center traffic early
6. Harden authentication
- Strong password policies
- MFA / OTP
- Don’t reveal whether username or password was
wrong
7. Monitor and alert
- Track failed login rates
- Alert on spikes and auto-tighten limits during attacks
6
17
259
26,921