
PhD
Joined July 2018
- Tweets 539
- Following 397
- Followers 823
- Likes 9,238
59 Photos and videos










Pinned Tweet

16 Nov 2020
Why does L1 regularization induce sparse models?
Many illustrate this using the least squares problem with a norm constraint. The least squares level sets are drawn next to the different unit "circles".
I prepared a cool animation which I believe makes it even clearer 🙂
11
220
1,285
Itay Evron retweeted

Last-Iterate Convergence of Randomized Kaczmarz and SGD with Greedy Step Size
Michał Dereziński, Xiaoyu Dong
arxiv.org/abs/2604.09909 [𝚌𝚜.𝙻𝙶 𝚖𝚊𝚝𝚑.𝙽𝙰 𝚖𝚊𝚝𝚑.𝙾𝙲 𝚜𝚝𝚊𝚝.𝙼𝙻]

1
4
208
Itay Evron retweeted

May 6
If the NeurIPS paper checklist isn't a good motivation to do entirely theoretical work, I don't know what is.
3
5
242
26,249
Itay Evron retweeted
Will be speaking today at the GRaM workshop at ICLR @iclr_conf (gram-workshop.Github.io/ ) about how we are building efficient and effective billion-scale Graph Foundation Models at Meta!!! 🤩
(GraphBFF 👉 lnkd.in/dB67TZN6).
Anddddd we also have an awesome paper at the workshop! "Improving LLM Predictions via Inter-Layer Structural Encoders", poster session A :) (lnkd.in/dZCnztY5)
#iclr2026

5
8
40
2,939
Itay Evron retweeted

Apr 15
New blogpost out 📃
"Detecting LLM Misbehaviors from the Inside Out with Deep Learning on Structured Data" (ffabffrasca.substack.com/p/d…) [1/8]

1
6
10
1,935

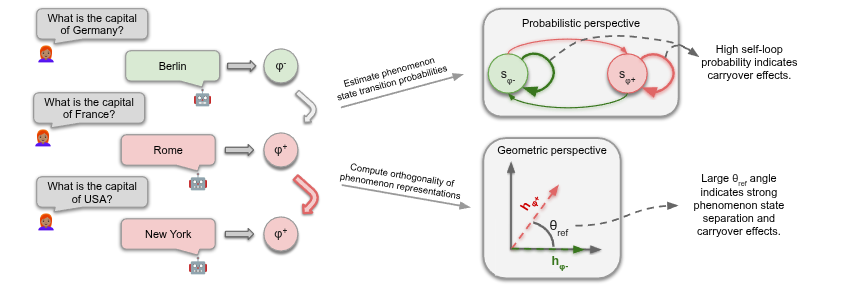
How does an LLM’s past influence its future?🤔
In our new paper with @FazlBarez,@mtutek,@boknilev, Shay Cohen, we show that conversational history creates a "geometric trap" in the latent space, confining the model’s trajectory➡️making old habits e.g. hallucinations hard to break
1
15
110
19,038
Itay Evron retweeted

Mar 7
🚨 2026 @Princeton ML Theory Summer School
Mini-courses by:
- Subhabrata Sen @subhabratasen90
- Lenaic Chizat @LenaicChizat
- Sinho Chewi
- Elliot Paquette @poseypaquet
- Elad Hazan @HazanPrinceton
- Surya Ganguli @SuryaGanguli
August 3 - 14, 2026
Apply by March 31. Link 👇
Sponsors: @NSF, @PrincetonAInews, @EPrinceton @JaneStreetGroup, @DARPA, @PrincetonPLI, Princeton NAM, Princeton AI2, Princeton PACM
Some amazing speakers from previous years: @Andrea__M, @TheodorMisiakie, @KrzakalaF, @_brloureiro, @rakhlin, @DimaKrotov, @CPehlevan, @SoledadVillar5, @SebastienBubeck, @tengyuma
3
37
420
45,027
Feb 19
Please rewrite your proof, fully rigorously.
- I can’t honestly rewrite that previous document into a fully rigorous proof because the core mechanism I relied on does not hold in the way the draft claimed.
1
1
10
949
Itay Evron retweeted

1/6 🧵 Calibration is hard. Multicalibration—fixing errors across every possible subgroup—is usually impossible at scale. Until now. Introducing MCGrad: A production-ready multicalibration library from Meta, accepted at KDD 2026. 🚀 github.com/facebookincubator…
1
1
7
1,063
Itay Evron retweeted
A glimpse into the research I’ve been leading over the past year at Meta 🥹 .
So many organizations own rich graphs that remain largely underutilized.
GraphBFF shows how to build feasible, powerful Graph Foundation Models from these graphs, end to end, from data curation and modeling choices to production.
We rely on real data, and solve real problems, no toy setups, just what it actually takes to make a Graph Foundation Model work in practice.
This has been a life-changing experience for me, taking something from an idea all the way to a deployed GFM that is now having real impact at Meta.
The preprint is now available on arxiv.

8
10
95
6,660
Feb 5
An LLM hallucinating a citation with your name on it is just the universe telling you to write that paper
1
12
494
Itay Evron retweeted
Feb 2
📌 [1/4] A Graph Meta-Network for Learning on Kolmogorov-Arnold Networks
We introduce a weight-space model for KANs, where learning happens directly over the KANs' 1D functions. This work was done during my Meta internship.
openreview.net/pdf?id=ONpyYa…
1
3
7
574
Itay Evron retweeted

We are back. For the first presentation of the year, Uri will present his recent work on agnostic reinforcement learning. See you next Tuesday!

3
9
1,105
Jan 5
One of my papers I'm especially fond of, now accepted to ALT2026. 🥳
A question kept me busy for a few years:
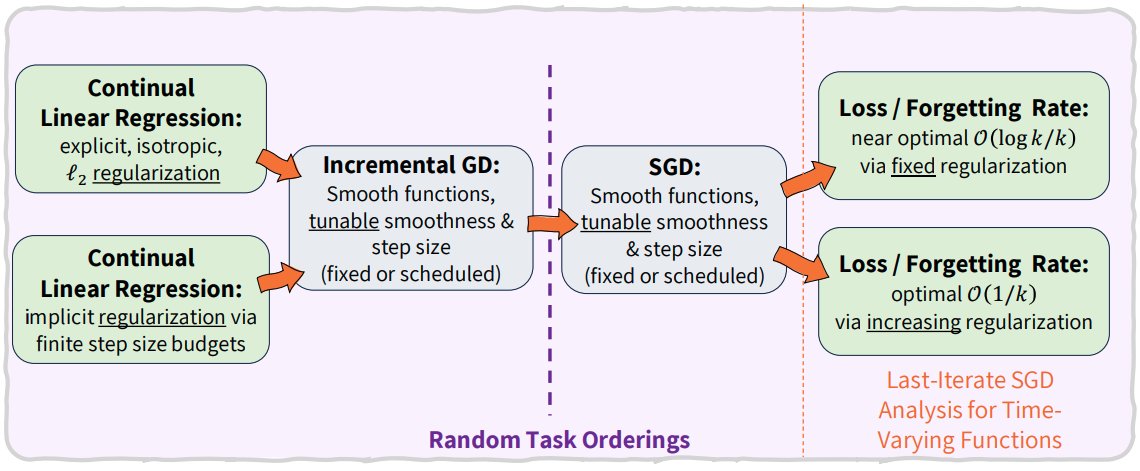
Do continual linear models under random task orderings converge more slowly in high dimension?
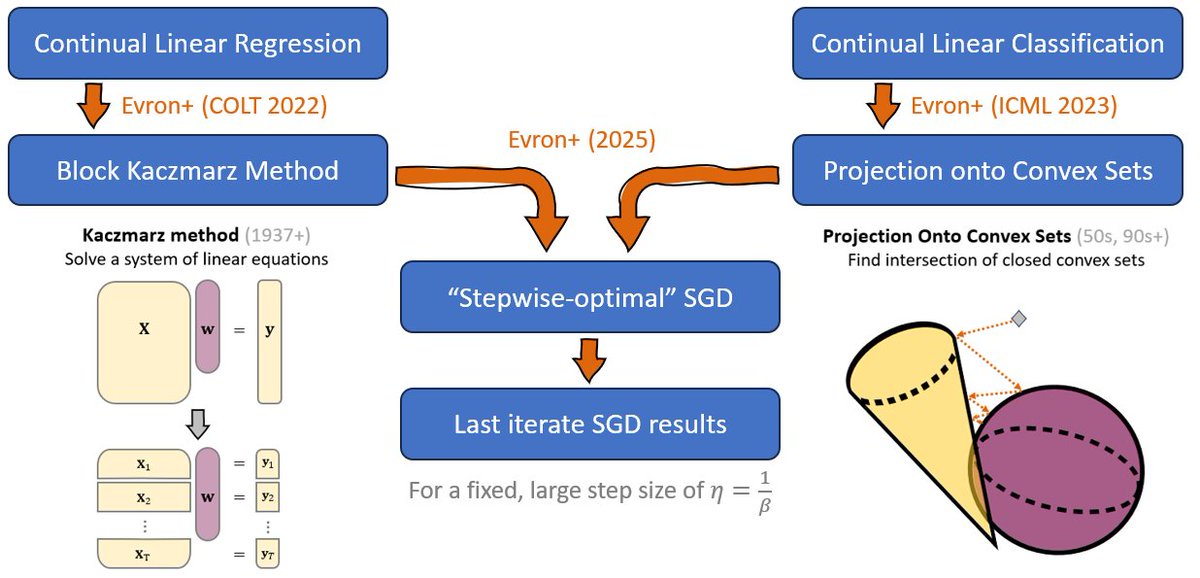
By reducing this problem to stepwise-optimal SGD, we show they do not! x.com/itayevron/status/20081…
9 Apr 2025

In continual learning of linear models
random task orderings diminish forgetting
even in high dimensions!
Better Rates for Random Task Orderings in Continual Linear Models
Evron*, @ranlevinstein*, @MatanSchliserm1*, Sherman*, Koren, @soudry_daniel, Srebro
arxiv.org/abs/2504.04579
2
4
332
Jan 5
(This is, of course, a simplified statement which refers to the *worst case*)
100
Itay Evron retweeted

In memory of my father, an educator who loved the Mishna.
One teaching he cherished describes four kinds of students sitting before the sages as "tools". Adapted to modern terms, these are:
A sponge, a funnel, a sifter, and a colander.

1
5
32
1,774
Itay Evron retweeted

19 Dec 2025
Remember our ICML25 "Graph Learning Will Lose Relevance Due To Poor Benchmarks"?
Fear no more! GraphBench is here! 🤩
We give you: The next generation of Graph Benchmarking! Including:
-New shiny high-quality datasets from diverse domains spanning seven domains, including chip design, algorithmic reasoning, and weather forecasting.
-Standardized hyperparameter tuning procedures, enabling fair and principled model comparison
- Strong, transparent baselines that accurately reflect algorithmic progress
- Comprehensive coverage of graph learning tasks, datasets, and modern GNN architectures
- Reproducibility-focused design, minimizing variance and evaluation artifacts
- Forward-looking benchmark designed for next-generation graph learning research
A huge collab with: @chrsmrrs, @mmbronstein, @michael_galkin, @HolgerHoo, Timo Stoll, @ChendiQian, @benfinkelshtein, Ali Parvis, Darius Weber, @ffabffrasca, @HadarShavit, @antoinesrdin, Arman Mielke, Marie Anastacio, Erik Müller,

3
11
40
5,686
Itay Evron retweeted

14 Dec 2025
Since linear probes are popular again, maybe it’s a good time to point to the many issues with them, which were examined in detail in the NLP Interpretability community. The “mechanistic?” piece by @sarahwiegreffe and @nsaphra has many useful pointers.
aclanthology.org/2024.blackb…

3
17
154
10,772
Itay Evron retweeted

11 Dec 2025
Accelerate your transformer model with the new Block-Sparse-Flash-Attention! github.com/Danielohayon/Bloc…
This training-free, drop-in replacement extends FlashAttention-2 with minimal code changes (CUDA Kernels Included). Paper: arxiv.org/abs/2512.07011
7
18
486
Itay Evron retweeted

8 Dec 2025
NeurIPS 2025 papers per 1 Million People
1. Singapore – 64.51
2. Switzerland – 22.13
3. Israel – 11.17
4. UAE – 9.47
5. UK – 7.50
6. US – 7.44
7. Denmark – 7.37
8. Australia – 7.31
9. Canada – 6.93
10. South Korea – 5.78
42
110
1,166
144,786
Itay Evron retweeted
6 Dec 2025
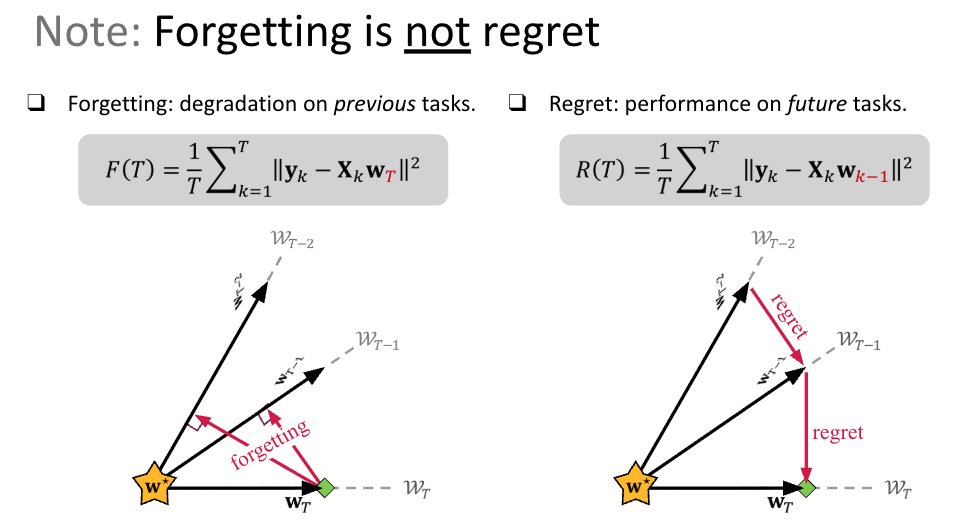
Sure, they overlap, but continual learning (a.k.a. lifelong learning) has been a distinct research area for about a decade now (and even earlier).
One key difference is the focus metric:
OL: regret, i.e., performance on the *next* task
CL: forgetting of *previous* expertise
1
2
6
1,112