
AI/ML Advocate @googlecloud | Vertex AI dude | Research, Open Models, Ray & TPU | Instructor @DeepLearningAI | Startup Advisor @ycombinator x Google Cloud
Joined February 2012
- Tweets 1,896
- Following 1,350
- Followers 1,853
- Likes 996
309 Photos and videos






Pinned Tweet

Apr 26
Presenting at the Next '26 Developer Keynote is one of those moments I'll remember for a long time.
Thank you to everyone who played a part.
Till the next Next!
5
1
16
1,372
Jun 12
Anthropic just announced a new batch of self-hosted sandbox providers, and Google Cloud is on the list with the GKE Agent Sandbox.
With this integration, Claude and the agent loop stay on the Anthropic platform, while every tool call runs in a gVisor pod on your cluster inside your environment, close to your data, in a pool that scales with demand.
Sample repo in 🧵
Jun 12

Claude Managed Agents can operate in a sandbox you control, on your own infrastructure or with any provider you choose.
Today we added new guides for @blaxelAI, @e2b, @googlecloud, @namespacelabs, and @superserve_ai, so you can choose the best fit for your use case.
1
2
13
3,205
Jun 11
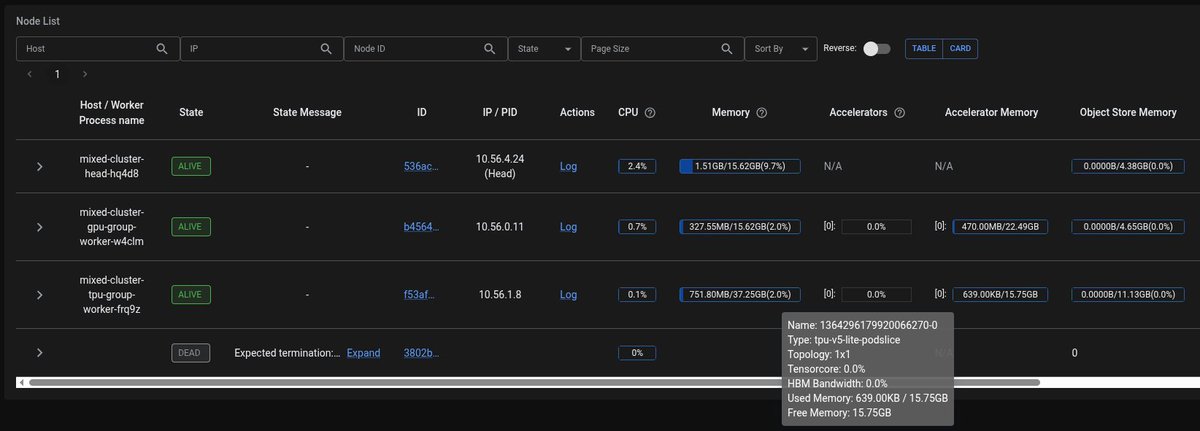
Ray's cluster dashboard now shows TPU tensor core utilization and HBM memory usage alongside GPU metrics, with smart column labeling for GPU-only, TPU-only, or mixed accelerator clusters.
1
96
Jun 1
I will personally realize two dreams here. Going to Japan and present with さん Kaz
Jun 1

6/10開催のAnthropic主催イベントCode w/ Claudeでは、 @ivnardini と私で"Building with Claude on GoogleCloud"を担当します。すでにオンサイトは満席ですが、オンライン視聴可能なのでぜひ。
claude.com/code-with-claude/…
1
5
4,207
May 31
With v2.1.158, Anthropic shipped Auto mode in Claude Code with Google Cloud
You can now run commands in Claude Code using Claude models on Google Cloud without stopping for permission prompts every time
code.claude.com/docs/en/chan…
2
3
1,142
May 24
Next Friday we are running a hands-on Claude Code on Google Cloud workshop together with the @AnthropicAI team in SF
Half day, Guided labs, and Live Q&A
Link
dev.to/googleai/google-cloud…
6
321
May 24
I looked into Keras Kinetic recently
Keras Kinetic is a framework that lets you run Keras and JAX workloads on Cloud TPUs by writing a training function and adding a decorator
Personally, it is one of the easiest ways I’ve seen to run a first TPU job so far
Here is a great blog post on fine tuning Gemma to speak Gen-Z slang using Kinetic
Blog
jigyasa-grover.github.io/Kin…
1
2
317
May 24
145
May 7
I spent some time testing elastic training capabilities on MaxText recently.
MaxText is Google’s open-source JAX library for the full LLM lifecycle scaling from one host to hundreds of TPU chips.
Pre-train with train method, run SFT/DPO/GRPO in the same package, and serve via vLLM.
It supports several models including Gemma, DeepSeek, Qwen, Kimi and more.
Docs
maxtext.readthedocs.io/en/ma…
Tutorial coming soon.
484
May 6
Wrapping up the demo for Code with Claude in SF.
If you’re around, I'm happy to talk. See you tomorrow!
1
326
Apr 29
Ray Serve now supports multi-host TPU slice deployments with gang scheduling.
Before, TPU slices required manual host counts and bundle replication, with no guarantee of a single co-located slice.
Now, Ray Serve uses Ray Core’s SlicePlacementGroup to pin deployments to one co-located TPU slice, matching Ray Train.
Code
github.com/ray-project/ray/b…
4
422
Apr 23
Anthropic released the public beta of Cowork on Third-Party Providers (3P)
Claude Desktop with Cowork and Code can now run using your own Google Cloud endpoint, billed as token consumption to your GCP project.
Docs
claude.com/docs/cowork/3p/ov…
2
7
744
Apr 19
vLLM v0.19.1 shipped a bunch of optimizations and fixes for Gemma 4
> Gemma 4 MoE quantization support
> Eagle3 speculative decoding for faster inference
> Streaming and tool-call bug fixes for production applications
1
1
7
646
Apr 16
Vertex AI Agent Engine Memory Bank just landed two features I’ve been looking for.
You can now push events yourself and decide when memories get generated.
Before, agent memory was passive. You knew conversations were flowing in, but you didn’t know when extraction happened.
Now you have
> ingest events method lets you push raw turns in per user (and force_flush if you want it now)
> generation trigger config sets idle-duration, fixed-interval, and event-count rules
Code
github.com/googleapis/python…
1
3
387