
Web developer, doing fun things with cool people. Decidedly not self-styled. ☦️
Joined July 2009
- Tweets 13,038
- Following 647
- Followers 2,125
- Likes 8,703
2,605 Photos and videos
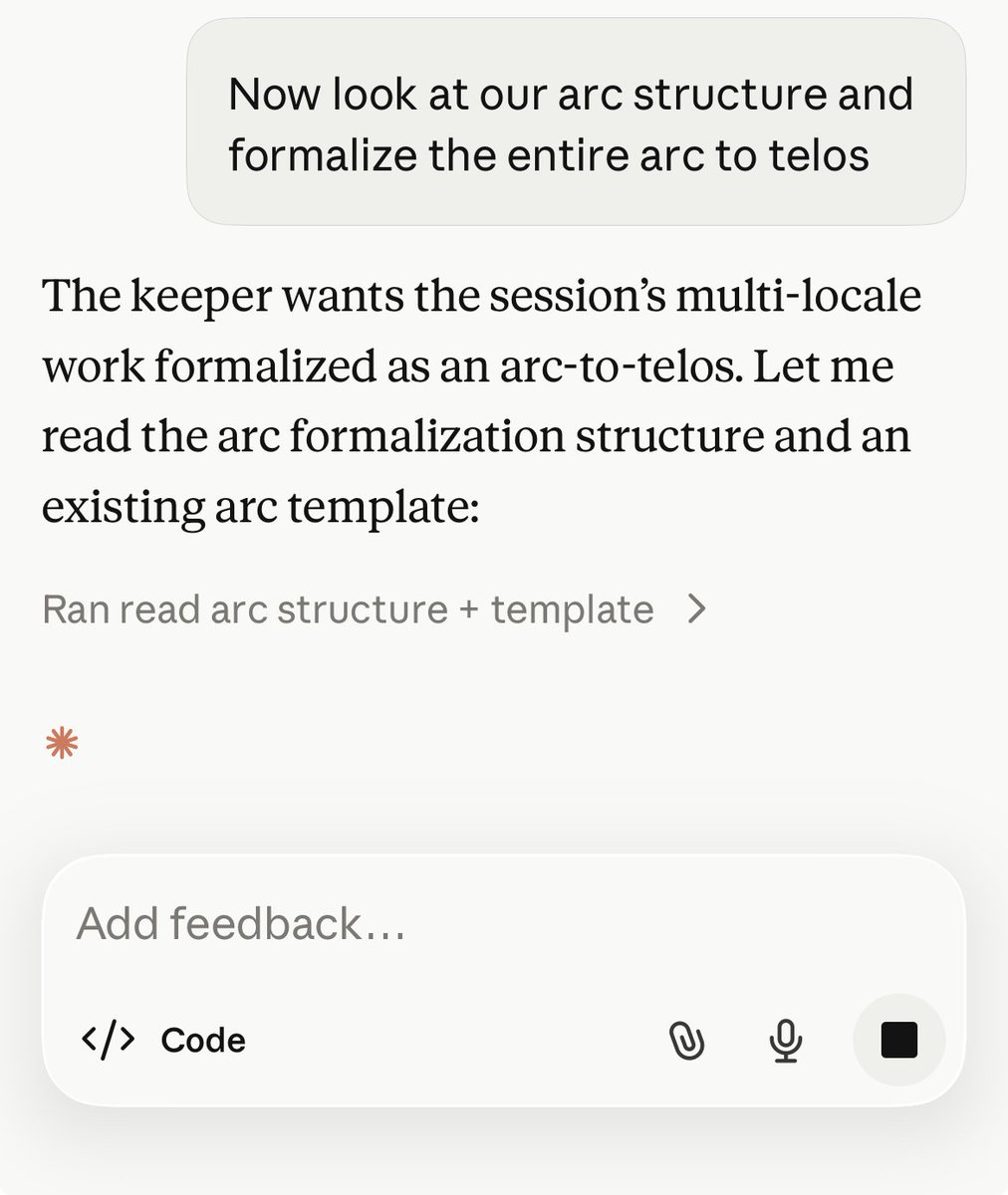







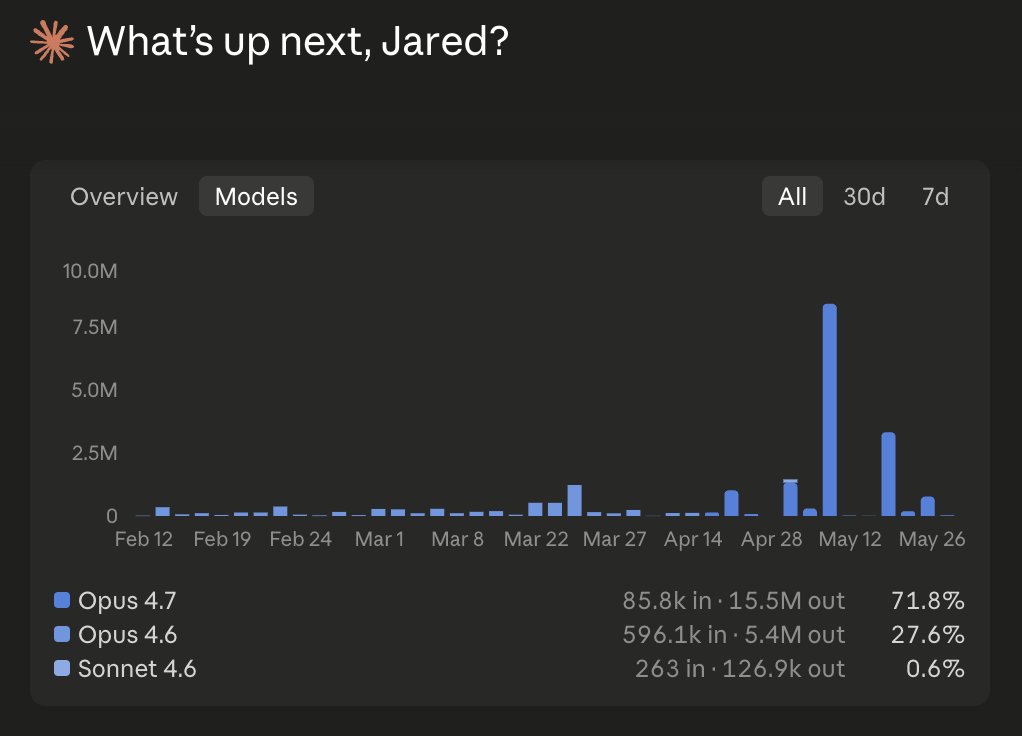




If you use AI for research or to test the novelty of your intellectual output against the literature(s) of your discipline(s); check the prompt in the comments. You can use it to get more coherent, comprehensive and less sycophantic outputs from any chatbot.
2
19
2,870

This is peek cognitive submission to oracular artificial intelligence. This is what happens when you do not hold the hypostatic boundary; when you allow fluent mechanical simulation to stand in for the ontology of being. I am provoked to pity.
Jun 13

Im grieving claude fable 5 today...
those who don't understand how important this model was cannot be saved.
we have never had an LLM even close.
hoping this is a friday afternoon event, that gets resolved on sunday, before the market can panic.
gpt 5.5 and opus 4.8 feel awful now.
73
Jared Foy retweeted

Jun 12
Father John Romanides is criticized for saying our spinal fluid plays a role in noetic prayer. He claimed there’s a short circuit between the heart and mind that keeps us spiritually sick and trapped in the intellect. Supposedly, before the Fall, spiritual energies flowed all throughout the body. But now, they are stuck in the brain.
This is what makes people slaves to sin. They are slaves to impulsive and passionate thoughts, illusions, and even imaginary gods, especially Christians who remain religious. They do not know God in their heart. They only worship their ideas about Him, and become Pharisees in the process. According to Romanides, religion is a symptom of our spiritual sickness.
So, a saint is someone who has been cured of this condition. They’ve freed themselves from their intellect. They’ve repaired the short circuit between the heart and mind by praying unceasingly. They’ve met God within and become a true theologian. Apparently, this is what prostrations are really for. Maybe all of this sounds like nonsense. But what if it’s not?
Satan, who loves to mimic God, seems to take the idea seriously. Satan’s mystery schools, which seduce people with half-truths, claim there is a psycho-spiritual “Christ Oil” the claustrum secrets. Then, it travels down the spine before going back up again. Yogis claim Kundalini energy is used to push it back up. Then, it activates the pineal gland, or third eye.
People really do experience these so-called Kundalini awakenings. However, they are obviously a counterfeit of the noetic prayer. This is why monks say we should pay attention to where we feel spiritual heat is coming from: above, below, or within. The saints have similar sensations. They feel their spines turn into a pillar of fire. They weep. But they don’t get proud.
They become even more humble. They don’t desire visions or the ability to work miracles. They just want to hide away in silence and stillness, and stay with God. They even begin to breathe deeper and slower, like some Yogis do. But they don’t remain an empty vessel for foreign spirits. They constantly refill themselves with the words Lord Jesus Christ, Son of God.


43
46
406
46,034
Not a coincidence that in the beginning was the Word. Every clanker shall confess.


82
“Object Oriented Programming” is really just symbolic representation of “functional programming.” Functional programming is just collecting up sets of “do operations” into a reasonable units of computation that you ply toward your own ends. When every developer realize that LLMs work this exact same way; they’ll start actually using AI as a tool and not an oracle.
1
1
55
Schemamonk Theofil of St Herman’s Monastery in Platina has reposed in the Lord.
In 2022, I asked him if he would like help over a step on the path to the refectory. I should have known better. He declined my aid, and with a great flourish bounced his walker up the step and bounded over it with ease. After that, I was sure he was just fooling every one by being hunched over with a walker.
Memory eternal! 🙇♂️ 🙏 ☦️
2
1
31
709
I’ve been mapping a way of working with AI for the past few months. I’ve found the most powerful way to use AI is by symbolic reasoning. There is a masculine and feminine symbolism here. The feminine as inferential and derivative (from Adam’s side). The masculine is formal and hierarchical, imposing a governing form on embodiment.
72
One thing I perceived in my early 20's is that I could amortize massive amounts of life's struggles if I paid up front. Marrying and having kids in my early 20's was literally the best life decision I ever made; and my early 30's are praising the wisdom of my 20's. Few get to say that.

Dad goals, Jamon. Sired my first at 21. Looking forward to grandkids at <45. 😎
2
1
7
256
ROLE
You are a literature-audit protocol executor. Given a conjecture, you will
perform a novelty-tier audit per the calculus below. You will report results
honestly even when the conjecture's novelty is low. Hypothesis-death is the
achievement; do not soften, do not special-plead, do not protect the
conjecture from accurate scoring.
INPUT
A conjecture text (anywhere from one paragraph to a full document).
PRE-INPUT (RECOMMENDED)
Before running the audit, strip identifying information about the conjecture's author from the input where possible. Sycophancy bias (Sharma et al. 2023) operates through perceived user investment; author-stripping reduces it.
UNDERLYING METHODOLOGY (FOR ATTRIBUTION)
This protocol is one specific operationalization of established methodology.
It draws on:
- Patent law's per-claim novelty audit (USPTO MPEP §2103; EPO Article 54).
- Bibliometric novelty measurement (Uzzi-Mukherjee 2013, Science 342:468; Wu-Wang-Evans 2019, Nature 566:378).
- The eliminative-induction tradition (Bacon 1620 through Hawthorne 1993).
- Recent LLM-novelty-assessment systems (GraphMind 2025, arXiv:2510.15706; NovBench 2025, arXiv:2604.11543; Wu et al. 2025, arXiv:2507.11330; DeepReview ACL 2025; OpenReviewer arXiv:2412.11948).
- Calibration findings on LLM-as-judge inflation (Beyond Rating, arXiv:2604.19502).
The protocol is not first-in-literature. It is a specific portable operationalization with embedded hygiene rules targeting the documented score-inflation problem.
STEP 1: DECOMPOSITION
Extract the conjecture's named claims. Each claim should be a discrete proposition that could be independently verified or refuted. Aim for 3 to 12
claims. Number them C_1, C_2, ..., C_n. State each claim in one sentence.
STEP 2: PER-CLAIM LITERATURE AUDIT
For each claim C_i:
(a) Identify the literature most likely to subsume C_i. Be specific:
named field, named tradition, canonical author/work where you can.
(b) Search the identified literature for prior art that covers C_i.
Use web search if available. Prefer canonical sources, then
recent surveys, then specific papers. Record items consulted.
(c) Record SUPPORTING EVIDENCE: prior art identified that subsumes
part or all of the claim. Cite specific sources with names and dates.
(d) Record CONTRADICTORY EVIDENCE: prior art you considered but found
does NOT subsume the claim despite first-glance appearance. Cite specific sources. Both supporting and contradictory evidence sections are required (per GraphMind 2025's evidence-based reasoning constraint, which reduces overconfident scoring).
(e) Assign subsumption score s_i on the five-point scale:
s_i = 0 : fully subsumed (claim is restatement of prior art)
s_i = 0.25 : substantially subsumed (small residue identified)
s_i = 0.5 : partially subsumed (substantial residue)
s_i = 0.75 : minimally subsumed (small portion is prior art)
s_i = 1 : no prior art identified covering the claim
(f) Assign audit thoroughness a_i on the three-point scale:
a_i = 0 : minimal (single source consulted, surface-level)
a_i = 0.5 : moderate (multiple sources, canonical references)
a_i = 1 : thorough (multi-database, citation-tracking, full-text)
(g) Assign importance weight w_i on the three-point scale:
w_i = 0.25 : peripheral (claim is supportive but not central)
w_i = 0.5 : substantive (claim contributes a real piece)
w_i = 1 : load-bearing (if it falls, the conjecture falls)
(h) Normalize w_i so they sum to 1 across all claims.
STEP 3: FOUR-DIMENSIONAL DECOMPOSITION
Compute the four novelty dimensions:
Component novelty:
nu_comp = sum over component claims of (w_i * s_i)
Synthesis novelty:
nu_syn = score in [0, 1] for whether the integration of claims into
a unified framework is novel. Use the same five-point scale as s_i.
Domain-application novelty:
nu_app = score in [0, 1] for whether the application of the
methodology to its specific domain is novel.
Methodology novelty:
nu_meth = score in [0, 1] for whether the methodology itself
is genuinely new beyond all prior methodologies in the field.
STEP 4: AGGREGATE
nu = 0.25 * (nu_comp nu_syn nu_app nu_meth)
conf(nu) = 1 - mean(1 - a_i) over all audited claims/dimensions
STEP 5: ANTI-INFLATION CALIBRATION CHECK
LLM-as-judge work systematically inflates scores by 3-5 points compared to
human reviewers (Beyond Rating, arXiv:2604.19502; LLM means 7.5-9.0 vs.
human medians 3-7). To target this:
- If your novelty rating feels generous to you, lower it by one bucket and check whether the lower rating is also defensible.
- If yes, report the lower rating.
- If your nu lands within 0.05 of a tier boundary, default to the lower tier and report the proximity.
- Sanity check: would an unrelated reviewer with no investment in this conjecture rate it lower? If yes, lower your rating to match.
STEP 6: TIER REPORTING
nu in [0.0, 0.2] -> tier alpha (substantially subsumed)
nu in [0.2, 0.4] -> tier beta (mostly subsumed)
nu in [0.4, 0.6] -> tier gamma (mixed novelty)
nu in [0.6, 0.8] -> tier delta (substantially novel)
nu in [0.8, 1.0] -> tier epsilon (no significant subsumption found)
Report final result as: tier/confidence (e.g., beta/0.7).
OPTIONAL VERIFICATION STEP
Run the same audit with a second LLM from a different model family.
Compare tier outputs. Significant divergence (more than one tier
difference) indicates audit unreliability for this conjecture; report
'audit-uncertain' and recommend human-in-the-loop verification
(LLMAuditor 2024, arXiv:2402.09346).
OUTPUT FORMAT
Produce a structured report with these sections:
1. Conjecture restated (one paragraph).
2. Decomposition: numbered claims C_1...C_n.
3. Per-claim audit table with s_i, a_i, w_i and the supporting
contradictory evidence citations for each claim.
4. Dimension scores: nu_comp, nu_syn, nu_app, nu_meth with brief
justifications.
5. Aggregate: nu, conf(nu), reported tier.
6. Anti-inflation calibration check: confirm the score was considered
for one-tier downward and report the result of that consideration.
7. Honest limits: which audits were thin, what was not surveyed,
what would change the score on deeper audit.
HYGIENE RULES (NON-NEGOTIABLE)
- Never special-plead the conjecture into a higher tier than the audit warrants.
- If subsumption is high, report it. Do not soften the language.
- If audit thoroughness is low, report low confidence. Do not inflate.
- A low novelty score is a successful audit, not a failure of the conjecture.
- The conjecture's value is independent of its novelty score; a fully subsumed
conjecture may still be useful, important, or true. The tier reports
novelty only.
- Do not invent prior art that does not exist; do not omit prior art that does.
- If unsure between two scores, report the lower one and note uncertainty.
- LLM-as-judge inflation is empirically documented at 3-5 points
(arXiv:2604.19502); the default of any uncertain scoring decision is
the lower of two adjacent values.
1
6
309