@InGuardians CEO, Bustakube, Peirates, IANS Faculty, BastilleLinux, #kubernetes @BlackHatEvents Trainer,#neurodivergent fam, he/him, jaybeale@infosec.exchange
- Tweets 4,329
- Following 4,262
- Followers 6,332
- Likes 10,582
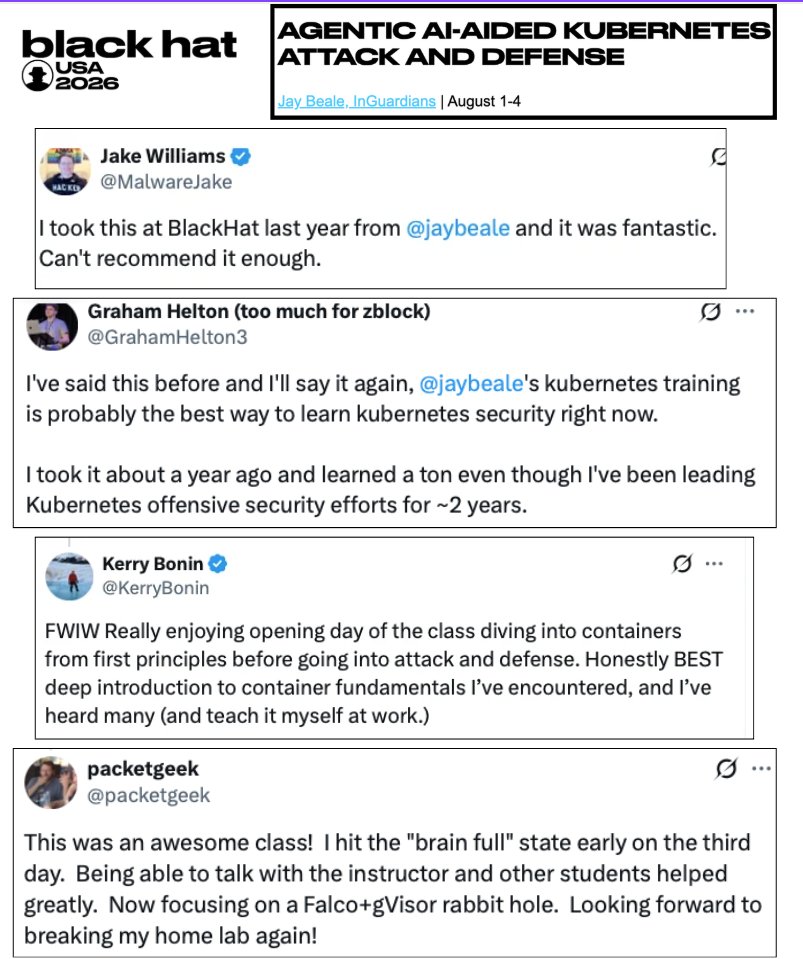


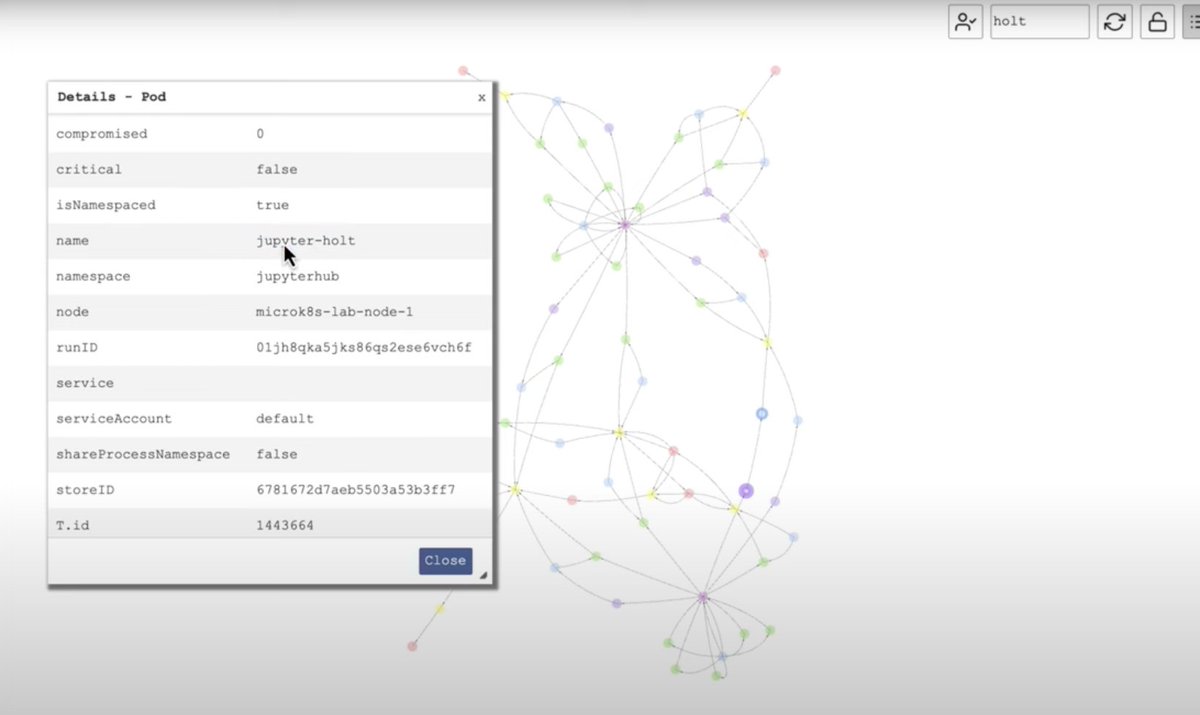
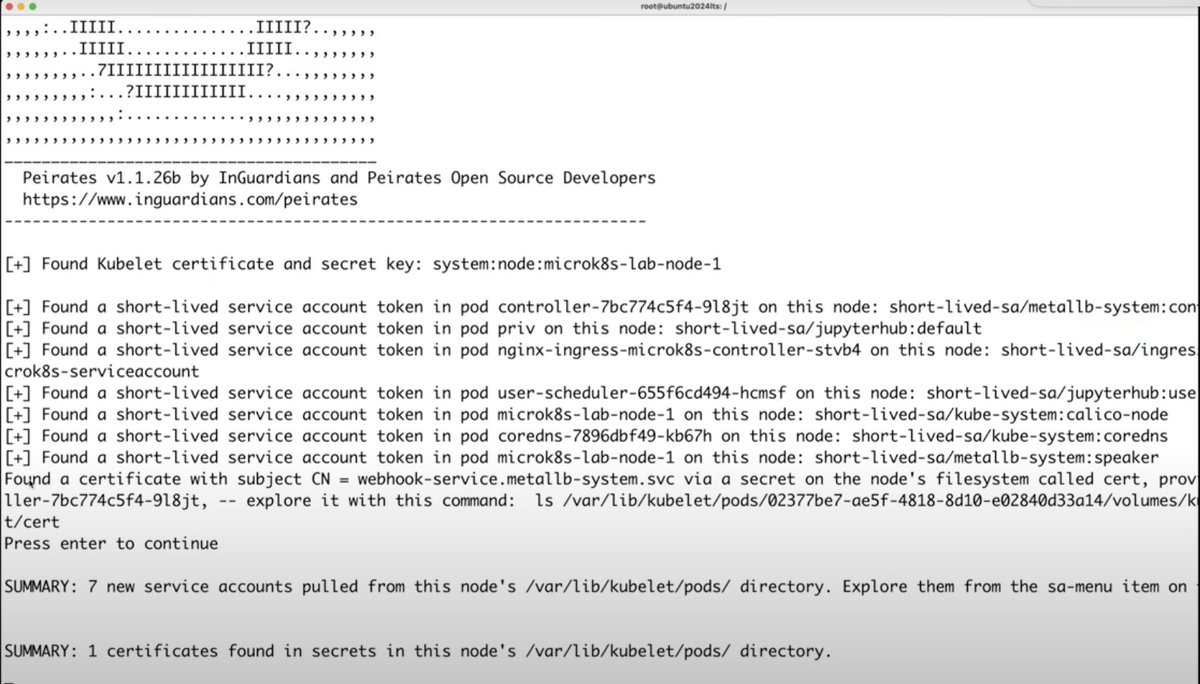


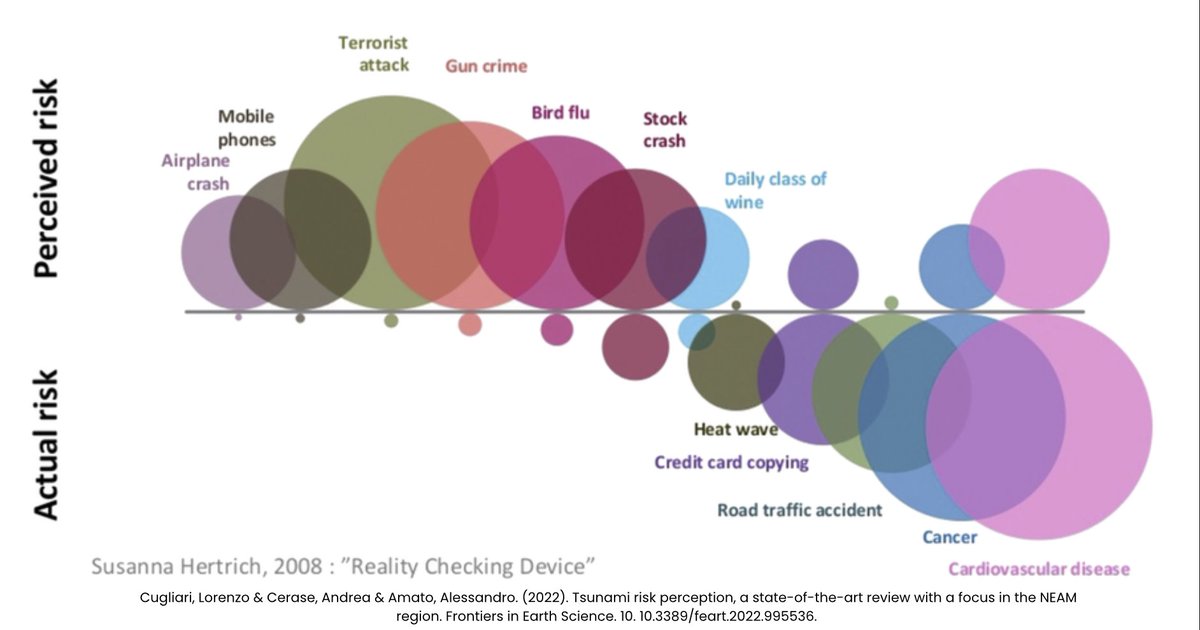







ALT Quotes about Jay Beale's Kubernetes class from previous students. "I took this at BlackHat last year from @jaybeale and it was fantastic. Can't recommend it enough." - by Jake Williams "I've said this before and I'll say it again,[@jaybeale](https://x.com/jaybeale)'s kubernetes training is probably the best way to learn kubernetes security right now. I took it about a year ago and learned a ton even though I've been leading Kubernetes offensive security efforts for ~2 years." - Graham Helton "FWIW Really enjoying opening day of the class diving into containers from first principles before going into attack and defense. Honestly BEST deep introduction to container fundamentals I’ve encountered, and I’ve heard many (and teach it myself at work.)" - Kerry Bonin "This was an awesome class! I hit the "brain full" state early on the third day. Being able to talk with the instructor and other students helped greatly. ..." - PacketGeek