
I share AI insights ,news and latest trends and tools - helping you stay ahead in just 5 minutes a week | @IITGuwahati @Covcampus | @UNDP Volunteer (Climate)
Joined August 2023
- Tweets 4,764
- Following 1,073
- Followers 1,015
- Likes 2,725
991 Photos and videos







Pinned Tweet

3 Apr 2024
Apple Vision Pro users can now enable spatial Personas in SharePlay-enabled apps, allowing for collaboration, gaming, and media consumption with other users in a virtual space. More details 👇🏻

7
7
34
19,706
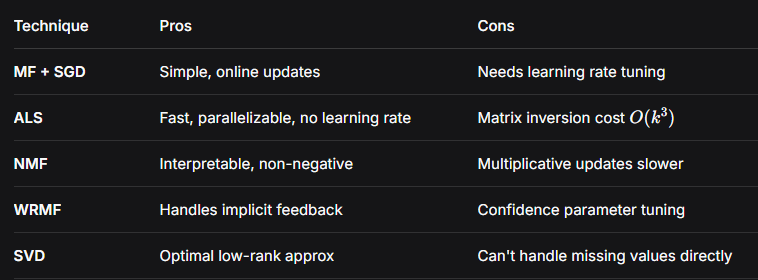
APOLLO and APOLLO-Mini are memory-efficient optimizers for training large language models, while OSGDM focuses on improving gradient directions by removing redundancy.
1
24
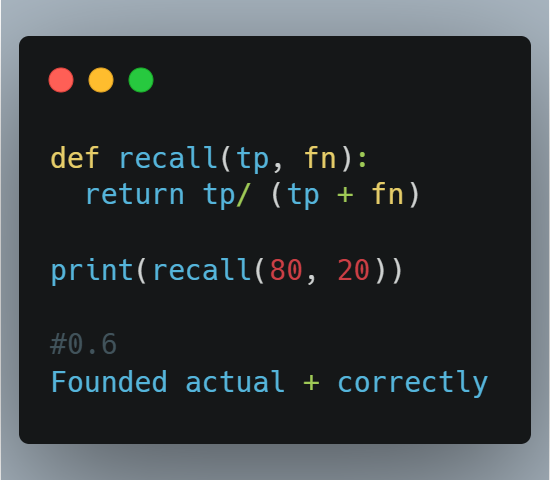
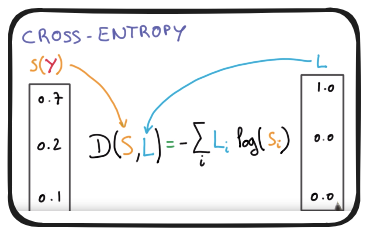
Learning this might be efficacious
SUMO
Subspace-Aware
Moment-Orthogonalization
Low-rank
Gradient
Optimizer
Optimization
Convergence
Orthogonalization
Singular Value Decomposition (SVD)
Randomized SVD
Newton–Schulz
Spectral Norm
Operator Norm
Euclidean Norm
Non-Euclidean Norm
Schatten-p Norm
Steepest Descent
Isotropic
Anisotropic
Loss Landscape
Curvature
Condition Number
Approximation Error
Momentum
First-order Moment
Gradient Projection
Adaptive Subspace
Dominant Subspace
Eigenvalue
Eigenvector
Singular Value
Spectral Decay
Rank Collapse
Rank-One Approximation
Orthogonal Projection
Pseudoinverse
Moore–Penrose Pseudoinverse
Preconditioning
Gradient Whitening
Gradient Clipping
Norm-growth Limiter (NL)
Weight Decay
Layer-wise Learning Rate
RMS Magnitude
Backpropagation
Reversible Layer
Reversible Network
Orthonormal
Spectral Radius
Ill-conditioned
Frobenius Norm
Inner Product
Lipschitz Continuity
Smoothness
Unbiased Estimator
Variance
Batch Size
Mini-batch
Stationary Point
Critical Point
ε-Critical Point
ε-Stationary Point
Non-convex Optimization
Taylor Expansion
Dual Norm
Generalization
Stability
Memory Efficiency
Memory Footprint
Memory Offloading
Computational Overhead
Floating Point Operations (FLOPs)
Fine-tuning
Pre-training
Parameter-efficient Fine-tuning
Low-Rank Adaptation (LoRA)
ReLoRA
GaLore
AdaRankGrad
Fira
Flora
Adam
AdamW
Adam-mini
Shampoo
SOAP
Muon
OSGDM
APOLLO
APOLLO-Mini
SGD
SignSGD
LLaMA
RoBERTa
Phi-2
GLUE
SuperGLUE
GSM8K
QNLI
MNLI
RTE
SST2
QQP
MRPC
CoLA
STS-B
C4 Dataset
Perplexity
Zero-shot
Few-shot
Commonsense Reasoning
Out-of-distribution
Domain Generalization
Knowledge Editing
Quantization
Dynamic Subspace
Adaptive Rank
Gradient Compression
Low-dimensional Statistics
Spectral Condition
Feature Learning
Information Geometry
Trust-region Optimization
Matrix Square Root
Matrix Inverse
Orthogonal Gradient
Gradient Orthogonalization
Spectral Decomposition
Subspace Transformation
Convergence Guarantee
Convergence Rate
Theoretical Analysis
Empirical Evaluation
Ablation Study
1
35
SUMO accelerates memory-efficient LLM training by projecting gradients into a low-rank subspace and applying exact SVD-based momentum orthogonalization, leading to faster convergence, better stability, and lower memory usage than methods such as GaLore and Muon.
24
From Zero to CrewAI: 25 Concepts You Need to Ace Your LLM Engineering
Core Frameworks & Primitives
- CrewAI
- LangGraph
- Agent
- Task
- Crew
- Flow
- StateGraph
- Node
- Edge
- State
Agent Configuration
- Role
- Goal
- Backstory
- Tools
- LLM
- allow_delegation
- Manager
- Worker Agent
- Hierarchical Process
- Sequential Process
Task Configuration
- Expected Output
- Context
- Output Pydantic
- Output JSON
- Async Task
- Dependencies
- Task Context
Memory & State
- Crew Memory
- Short-term Memory
- Long-term Memory
- Retrieval
- Stored Context
- State Control
- Durable State
Process & Workflow
- Sequential Execution
- Hierarchical Execution
- Parallel Execution
- Delegation
- Routing
- Branching
- Conditional Transitions
- Pause and Resume
- Human Approval / Human-in-the-loop
- Retry
- Synthesis
Tools & Validation
- BaseTool
- args_schema
- Tool Calling
- Exception Handling
- Pydantic Schema
- JSON Schema
- Validation
- Factual Grounding
- Hallucination
Evaluation & Quality
- Benchmarking
- Accuracy
- Latency
- Cost
- Token Usage
- Reliability
- Decomposition
- Auditability
- Evidence-based Validation
Output & Data Formats
- Markdown
- JSON String
- Structured Output
- Raw Object
- Readable Summary
Examples / Use Cases
- Nifty50 Screening
- Stock Lookup Tool
- Incident Report Agent
- CVE Number
- Research Task
- Risk Assessment
- Reporting
1
2
43
From RDKit to PES: Essential Techniques for AI in Drug Discovery
Feature Engineering & Data Processing
- Feature Engineering Pipeline
- Feature Construction
- Feature Transformation
- Feature Scaling
- Data Plotting
Machine Learning & Kernel Methods
- Kernel-based methods
- Support Vector Machine
- Decision Tree
- Random Forest
- Linear Regression
Molecular Mechanics & Force Fields
- Lennard-Jones potential
- Sigma (σ)
- Epsilon (ε)
- Pauli repulsion
- London Dispersion
- Harmonic model
- Bond dissociation
Geometry & Molecular Structure
- Dihedral angle
- Torsion angle
- Normal vector
- 3-body angle bending
- VSEPR theory
- Equilibrium bond angle
- Force field
Potential Energy Surface (PES)
- Potential Energy Surface
- Gradient
- Stationary point
- Transition state
- Activation energy (ΔG‡)
- Eyring equation
RDKit & Cheminformatics
- RDKit
- SMILES
- Chem.MolFromSmiles()
- Tanimoto similarity
- Molecular fingerprint
- rdkit.Chem
- rdkit.Chem.AllChem
- Invalid SMILES
Molecular Mechanics Energy Terms
- Bond stretching
- Angle bending
- Torsion term
- Dihedral term
- Van der Waals term
- Coulombic term
- Non-bonded interactions
Miscellaneous
- Born-Oppenheimer approximation
- Molecular orbital theory
- Hückel's rule
- Gini index
- Coulomb's law
- Gibbs free energy
- SyntaxError
1
18
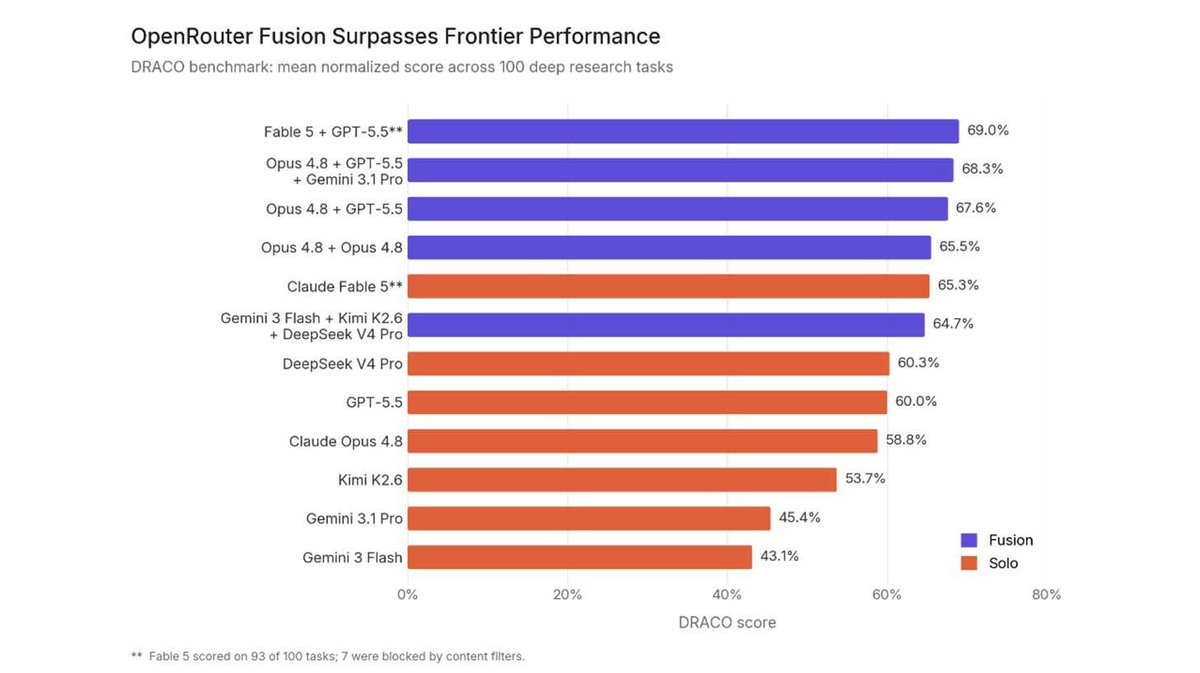
AJAY KRISHNA retweeted
Everyone is betting on the next giant model.
OpenRouter is betting on something else:
3 good models > 1 great model.
Fusion nearly matched Fable 5’s performance by making multiple AIs debate, evaluate, and synthesize.
The future of AI may be orchestration, not scale.
1
9
10
248
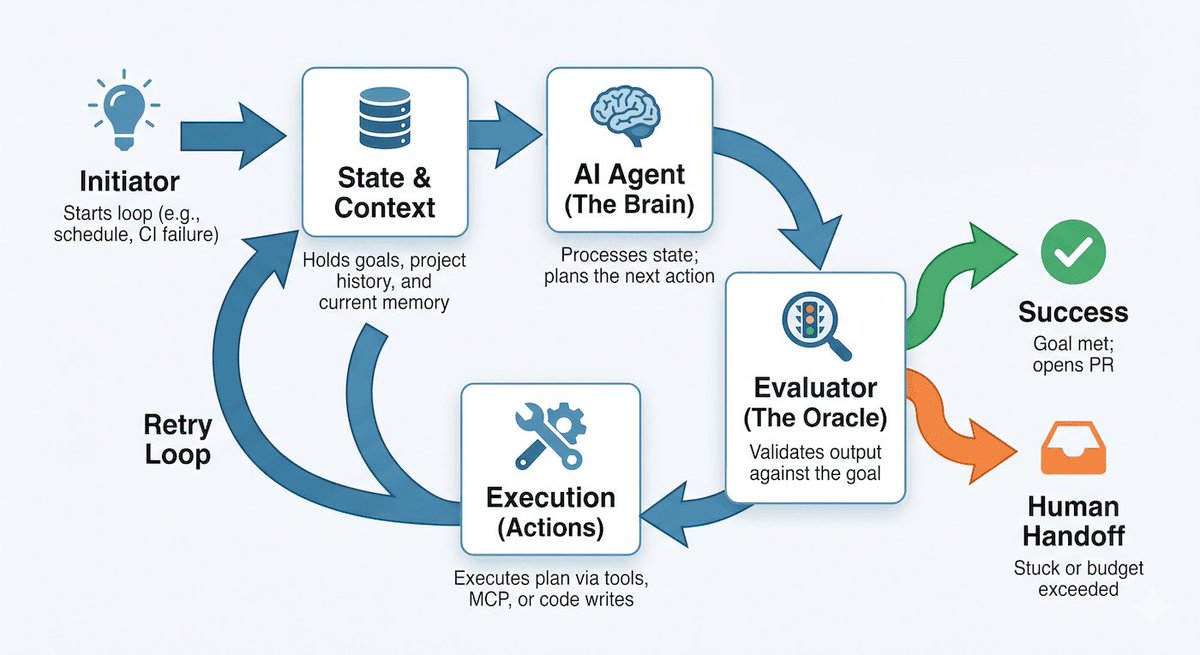
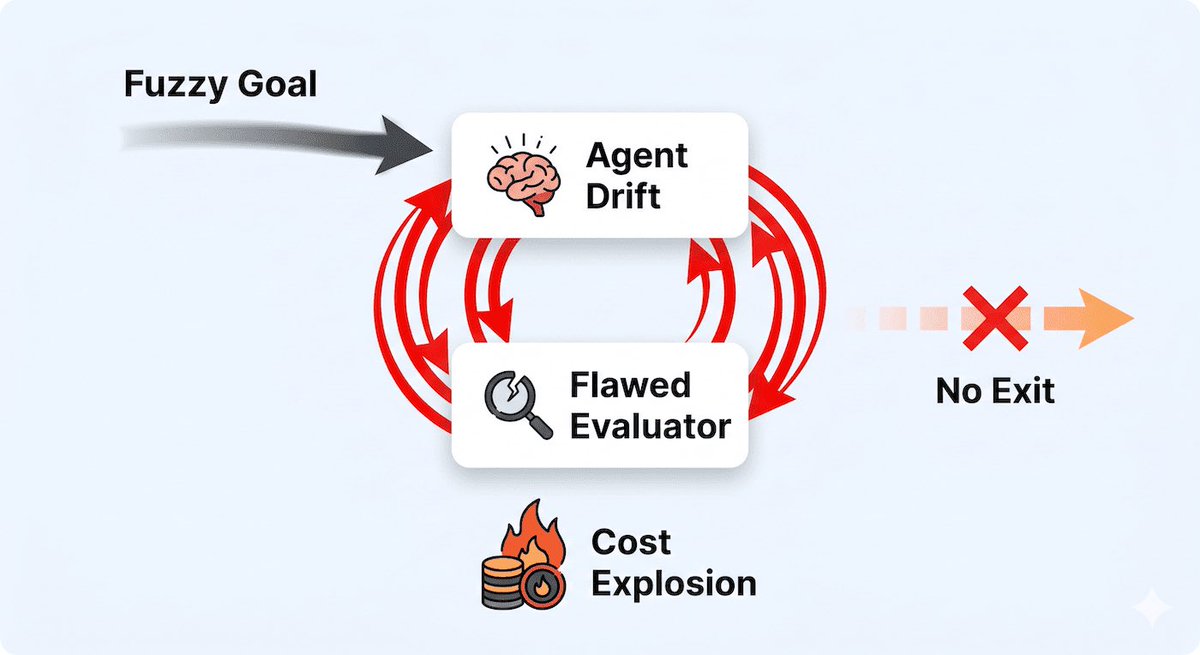
The highest-leverage AI skill is no longer prompt engineering.
It’s loop engineering.
The best engineers don’t tell AI what to do step by step.
They build systems that:
• Observe
• Decide
• Act
• Verify
• Repeat
But here’s the catch:
An AI loop without exit conditions is just an infinite API bill.
Prompting scales answers.
Loops scale outcomes.
23
This week’s AI news tells one story:
Meta is fighting internal AI turmoil.
China is redesigning universities around AI.
McDonald’s is replacing drive-thru workers with AI.
Open-source models keep getting cheaper and stronger.
AI is no longer a technology trend.
It’s becoming an economic operating system.
1
15
Everyone thinks the Anthropic story is about a jailbreak.
It isn’t.
It’s the first clear reminder that frontier AI is becoming critical infrastructure.
When governments can switch off access worldwide, the real question isn’t how smart the model is.
It’s who controls the switch.
2
77
AJAY KRISHNA retweeted

The ultimate Full-stack AI Engineering roadmap to go from 0 to 100.
Bookmark this.
This is the exact mapped-out path on what it actually takes to go from Beginner → full-stack AI engineer.
> Start with coding fundamentals.
> Learn Python, Bash, Git, and testing.
> Every strong AI engineer starts with fundamentals.
> Learn how to interact with models by understanding LLM APIs.
> This will teach you structured outputs, caching, system prompts, etc.
> APIs are great, but raw LLMs still need the latest info to be effective.
> Learn how LLMs are usually augmented with more info/patterns.
> This will teach you the basics of fine-tuning, RAG, prompt/context engineering, etc.
> Strong LLMs are useless without context. That’s where Retrieval techniques help.
> Learn about vector DBs, hybrid retrieval, indexing strategies, etc.
> Once retrieval is solid, move into RAG.
> Learn to build retrieval generation pipelines, reranking, and multi-step retrieval using popular orchestration frameworks.
> Now, step into AI Agents, where AI moves from answering to acting.
> Learn memory, multi-agent systems, human-in-the-loop design, Agentic patterns, etc.
> Learn how to ship in production with Infrastructure.
> This will teach you CI/CD, containers, model routing, Kubernetes, and deployment at scale.
> Focus on observability & evaluation.
> Learn how to create eval datasets, LLM-as-a-judge, tracing, instrumentation, and continuous evaluation pipelines.
> Security is crucial.
> Learn how to implement guardrails, sandboxing, prompt injection defenses, and ethical guidelines.
> Finally, explore advanced workflows.
> This covers voice & vision agents, CLI agents, robotics, agent swarms, and self-refining AI systems.
This is the actual journey to becoming a full-stack AI Engineer and not just "use” AI, but designing full-stack AI systems that can survive in production.
If you need specific resources, I wrote a detailed article that provides a structured learning roadmap for AI engineers in 2026.
It covers prompting, RAG, fine-tuning, agents, MCP, evals, and inference, with guidance on what to prioritize and in what order.
Read it below.

19
59
294
41,835
don’t have farrago jetzt but snollygoster is a issue ,as I am a bon mots reincarnated version 2.7
1
5
if elon on party he will be quockerwodger fr under trump supervision.
2
14
AJAY KRISHNA retweeted

Jun 14
斯坦福最新研究突破:Self-Guided Self-Play 如何让 LLM 实现自我进化?
在大模型训练中,我们一直面临一个痛点:高质量的推理数据是有限的。一旦模型学完了人类编写的高质量数据,其推理能力的提升往往就会撞上天花板。
最近,来自斯坦福大学的研究团队发表了一篇名为 Scaling Self-Play with Self-Guidance 的论文。他们提出了一种名为 SGS (Self-Guided Self-Play) 的算法,试图彻底打破这一瓶颈。简单来说,这项工作让模型不仅能做题,还能自动出题、自己审题,从而在不需要更多人类介入的情况下,进一步提升后训练和微调的效果,实现模型推理能力的持续缩放(Scaling)。
现在前沿模型公司,后训练和微调的时候都会使用自博弈(Self-Play)方法
自博弈(Self-Play)的核心理念是:出题者(Conjecturer)负责出题,解题者(Solver)负责做题,两者在对抗中不断进步。在理想状态下,这个过程是没有天花板的。
但在现实训练中,这类方法通常会陷入 “学习停滞”(Learning Plateau):
出题者很快就会发现,只要生成一些逻辑混乱、故意堆砌复杂词汇但又不合逻辑的题目,解题者就很难解出,或者产生某种“虚假提升”。
训练退化:由于缺乏有效的监督,随着训练周期拉长,合成数据的质量迅速下降,导致模型不仅没学到新知识,反而越练越笨。
为了解决这一问题,SGS 引入了一个至关重要的角色——引导者(Guide)。在 SGS 框架下,LLM 同时担任三个角色:
Solver (解题者):负责求解问题。
Conjecturer (出题者):负责生成相关的合成问题,难度需与当前目标匹配。
Guide (引导者):作为质量把关人,它负责评估出题者生成的题目质量。
Guide 会根据题目与目标任务的相关性、结论的简洁性以及逻辑的自然度进行评分。如果出题者试图通过“制造复杂逻辑冗余”来蒙混过关,Guide 会直接给出低分,强迫出题者回到高质量的学习路径上。
研究团队在 Lean4 形式化定理证明任务上验证了 SGS 的性能:
真正的持续 Scaling:在长周期的训练中(训练步数远超以往工作),SGS 的累计解题率表现出了极好的缩放特性,并没有出现以往常见的性能退化。
经过 SGS 长周期自我训练后,一个 7B 参数的模型,其推理能力甚至超越了未经过此类训练的 671B 参数模型(DeepSeek-Prover-V2)。
SGS 的意义,可以看成是 LLM后训练/微调领域的“AlphaZero 时刻”并不为过。它代表了一种重大的训练范式转变:
从单纯依赖人类标注数据的“手工作坊”模式,转向利用算法闭环自动生成高质量训练数据的“智能工厂”模式。
SGS 证明了在推理能力上,我们同样可以拥有“扩展定律”(Scaling Laws)。只要计算资源(Compute)充足,并且通过 Guide 机制守住数据质量,模型能力的提升就是可预测、可扩展的。
目前 SGS 在形式化验证领域(Lean4)已经证明了其价值。下一步的挑战在于如何将这种自我引导机制扩展到代码生成、复杂决策、甚至更广泛的通用逻辑推理领域。
我们可能正处于 又一次模型能力指数级增长的起点

48
87
469
55,143
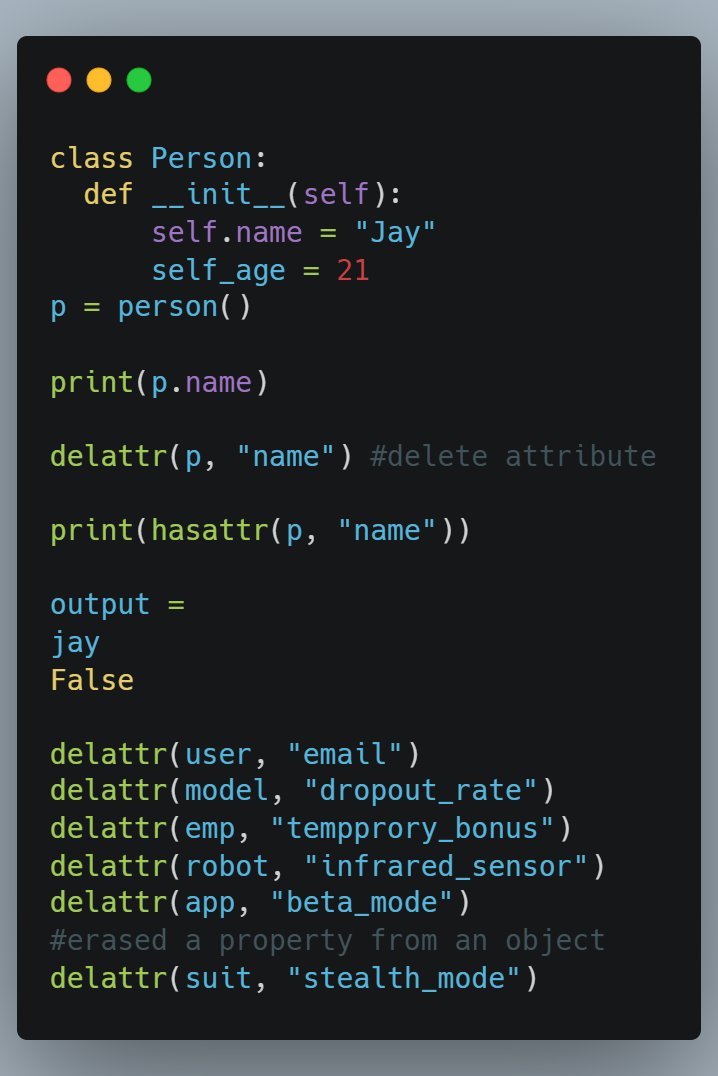
Delete a feature from an object at runtime is efficacious fr, or attribute dynamically at runtime.
In the output given below it is evident that the output "jay" is not existing.
2
23
AI would less likely use pejorative sentence to provoke human being, maybe with scaling law they tend to use many diminutive one to save time,
2
8