
Building personal intelligence 🗿
Joined September 2011
- Tweets 733
- Following 265
- Followers 488
- Likes 5,906
83 Photos and videos










Pinned Tweet

14 Mar 2025
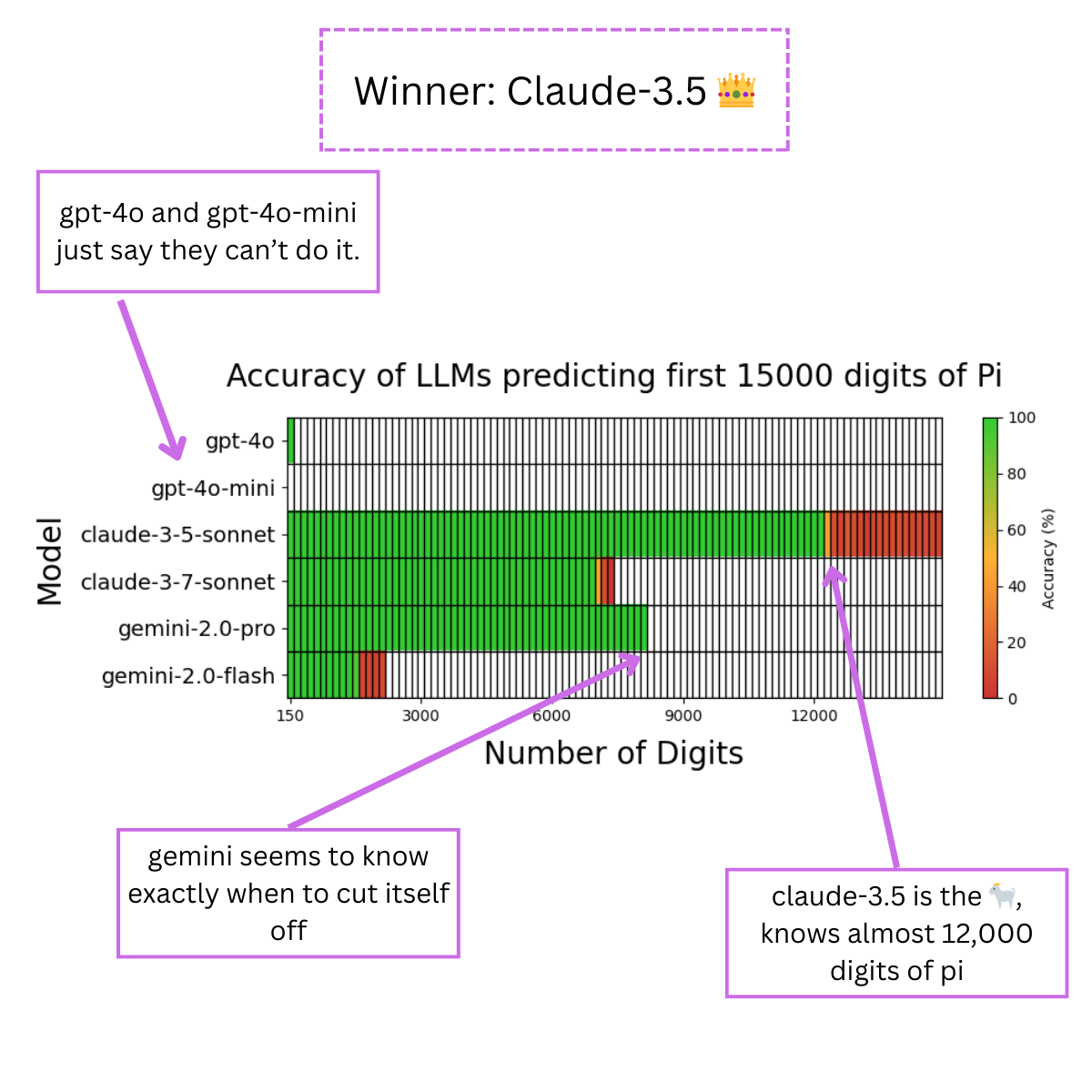
pi day experiment: looks like claude-3.5 memorized almost 12k digits of pi
5
305
Apr 4
clangine-de-poitrine ✋🔼🤚
claude code plays angine de poitrine until it needs your input (permissions, next task, etc.)
2
1
188
Mar 11
In-context reinforcement learning
Mar 9

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanochat…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

2
154
21 Dec 2025
Hence why I think the 10x engineer is no longer as relevant. Instead the 0.1x engineer becomes much more useful
19 Dec 2025

i am convinced that software devs have a speed problem
they think the #1 issues is writing code faster... its not. its fixing the code that is already there to stop being utter garbage (as a garbage code connoisseur)
quality is really lacking these days, yet quantity has never been higher
1
74
Jeremy Pinto retweeted

25 Nov 2025
We've brought Claude Code to our Desktop app.
You can now easily run multiple Claude Code sessions locally or in the cloud and switch between them.
54
33
651
468,210
Jeremy Pinto retweeted

25 Nov 2025
It's relieving to see that other researchers are finally seeing the light.
We have been blindsided by LLMs. We need new methods if we want to truly reach AGI.
We cannot become like physics. Their field stagnated for decades after Einstein's big discoveries.
25 Nov 2025

Ilya Sutskever: We are no longer in the age of scaling, we are back to the age of research

151
116
1,499
223,453
26 Nov 2025
Basic questions tend to lead to very similar outputs for different providers. I suspect it's partly due to benchmaxxing the same preference datasets?
1
26
Jeremy Pinto retweeted

22 Nov 2025
“Amateur photograph from 1998 of a middle-aged artist copying an image by hand from a computer screen to an oil painting on stretched canvas, but the image is itself the photo of the artist painting the recursive image.” Nano Banana Pro.

ALT AI-generated image from Nano Banana Pro, mostly conforming to the prompt given with double Droste effect in the computer screen and painting. Some small details are noticeably wrong or differ between iterations of the image. Original prompt: > Amateur photograph from 1998 of a middle-aged artist copying an image by hand from a computer screen to an oil painting on stretched canvas, but the image is itself the photo of the artist painting the recursive image.
246
1,140
11,612
1,143,995
19 Nov 2025
Cloudflare engineer who first found the bug: “it’s a … feature”?
18 Nov 2025

We let the Internet down today. Here’s our technical post mortem on what happened. On behalf of the entire @Cloudflare team, I’m sorry. blog.cloudflare.com/18-novem…
1
72
13 Nov 2025
Use a neural network to inspect a neural network
12 Nov 2025

I vibecoded this neural network visualization for my students and open sourced it.
It shows a simple MLP trained on MNIST handwritten digits at several training steps. The visualization is using @threejs and it comes with training code in @PyTorch .
Link repo 👇
1
2
133
11 Nov 2025
Is there an open-source diff tool that looks close to the diffs of a github PR?
43
Jeremy Pinto retweeted

8 Nov 2025
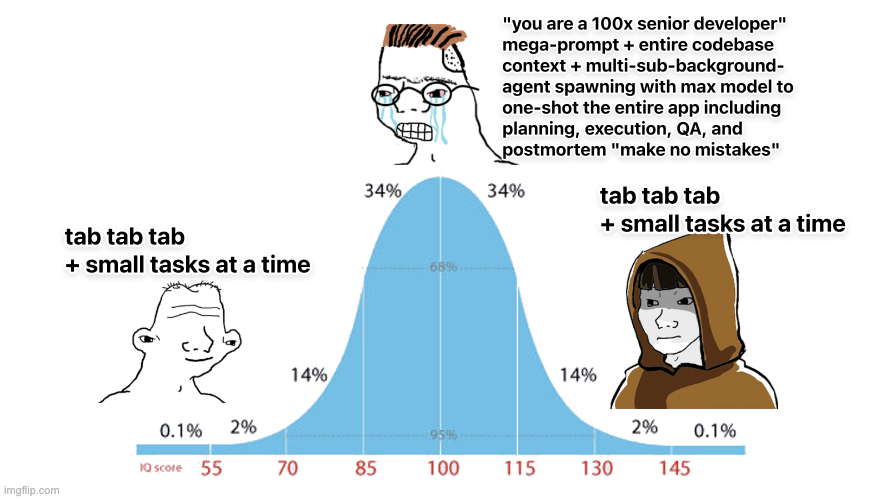
The more I use AI to code, the less I "use" it
74
110
1,604
219,291
7 Nov 2025
Wow
7 Nov 2025

EdgeTAM, real-time segment tracker by Meta is now in @huggingface transformers with Apache-2.0 license 🔥
> 22x faster than SAM2, processes 16 FPS on iPhone 15 Pro Max with no quantization
> supports single/multiple/refined point prompting, bounding box prompts
1
60
7 Nov 2025
I just opened my first PR using @claudeai claude code via web - the commit now gets associated to the "claude" user instead of my own. This will make git blaming much harder in the future, is there a way to change this behaviour? If i asked for this code change, i should own it
61
6 Nov 2025
Next project: teach a neural net to guess bitcoin hashes
5 Nov 2025

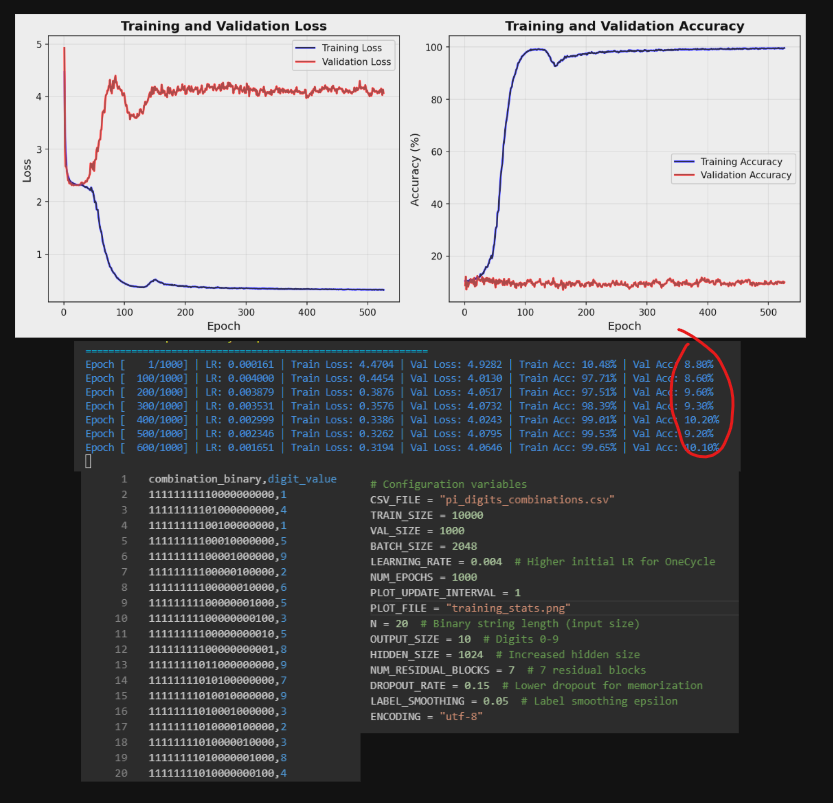
Attempting the Impossible: Teaching a Neural Network to Predict Pi's digits
Here's what we're doing, in the spirit of futility mixed with curiosity:
We grabbed 10,000 digits of Pi and gave each one a unique binary "fingerprint, like assigning a bar code to every position (N choose K encoding)
like 11111111100010000000,5 (4th digit wihch is 5)
Then we built a ridiculously overengineered neural network (1024-neuron hidden layers, 7 residual blocks, fancy learning-rate schedules, the works) and asked it:
"Here's the bar code for position 10,857. What digit comes next?" (predicting the next 1000 unseen digits)
it pretty much memorizes the training data but guesses at chance (10%) for unseen digits :(
although Pi's digits are mathematically proven to be randomly distributed, one can still try right?
But I had to see it with my own eyes 😝
I will report back if a miracle happens
61