
Joined January 2008
- Tweets 216
- Following 117
- Followers 315
- Likes 112
12 Photos and videos








Apr 20
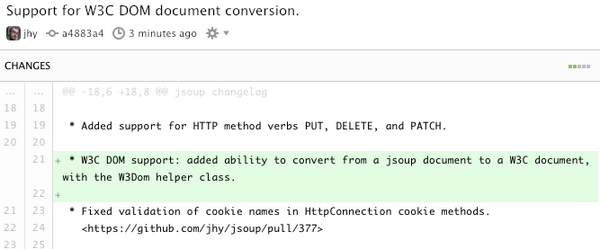
I've just released #jsoup 1.22.2.
This release makes editing the DOM during traversal more predictable, refreshes the default HTML tag definitions with newer elements and better text boundaries, and improves reliability in parsing and HTTP transport.
1
1
52
Apr 20
Also fixes a number of edge cases in cleaning, stream parsing, XML doctype handling, and Android packaging.
jsoup.org/news/release-1.22.…
32
Jan 1
I'm happy to announce the release of #jsoup 1.22.1!
This adds support for the re2j regular expression engine for regex-based CSS selectors, a configurable maximum parser depth, and brings a bunch of bug fixes and improvements.
1
1
2
226
Jan 1
Details at jsoup.org/news/release-1.22.…
This release marks 15 years of jsoup development.
1
129
25 Aug 2025
Happy to announce that #jsoup 1.21.2 is out!
Adds custom SSLContext support in HTTP/2 connections, brings DOM/fragment parsing perf gains, and fixes some edge cases in parsing, traversal, cloning, and concurrent reads.
jsoup.org/news/release-1.21.…
5
165
23 Jun 2025
Happy to announce that #jsoup v1.21.1 is out now! Lots of improvements, particularly the ability to directly select nodes (like text, data) with the CSS selectors.
1
1
6
586
23 Jun 2025
3
100
29 Apr 2025
Very happy to announce that I've just released jsoup 1.20.1!
Lots of improvements and bug fixes -- improved HTML parse rules to align with modern browsers, improved XML namespace handling, and a redesigned HTML pretty-printer for better consistency and customizability.
1
1
6
178
29 Apr 2025
This release also delivers performance optimizations, new API enhancements such as flexible tag definitions via TagSet, concise CSS selectors, and parser thread-safety improvements.
Big thanks to everyone who helped out.
jsoup.org/news/release-1.20.…
1
78
4 Mar 2025
Good news everybody! I just released #jsoup v1.19.1. It adds http/2 request support, and has a bunch of other improvements and bug fixes.
1
4
111
8 Jan 2025
The next version of #jsoup will (finally!) support making http/2 requests, if you're running on Java 11 . It still works down to Java 8 if you need that.
2
1
4
134
8 Jan 2025
It's a drop-in update with no changes required for existing Jsoup.connect() code, other than setting a system property (jsoup.useHttpClient) to enable.
1
62
8 Jan 2025
The implementation uses Java's multi-release JAR feature to make requests via the HttpClient impl if it's available, or will fallback to the current HttpURLConnection. This also gives a path to http/3 support when that PEP lands in Java.
github.com/jhy/jsoup/pull/22…
1
64
27 Nov 2024
Happy to announce the release of jsoup 1.18.2! Faster parsing with less GCs, and a bunch of bug fixes.
1
5
92
9 Aug 2024
I've been working on improving parse throughput and reducing memory allocations in jsoup (Java HTML parser) by recycling char[] and byte[] buffers between invocations—avoiding unnecessary heap allocations and garbage collection.
Details: github.com/jhy/jsoup/pull/21…
1
2
128
9 Aug 2024
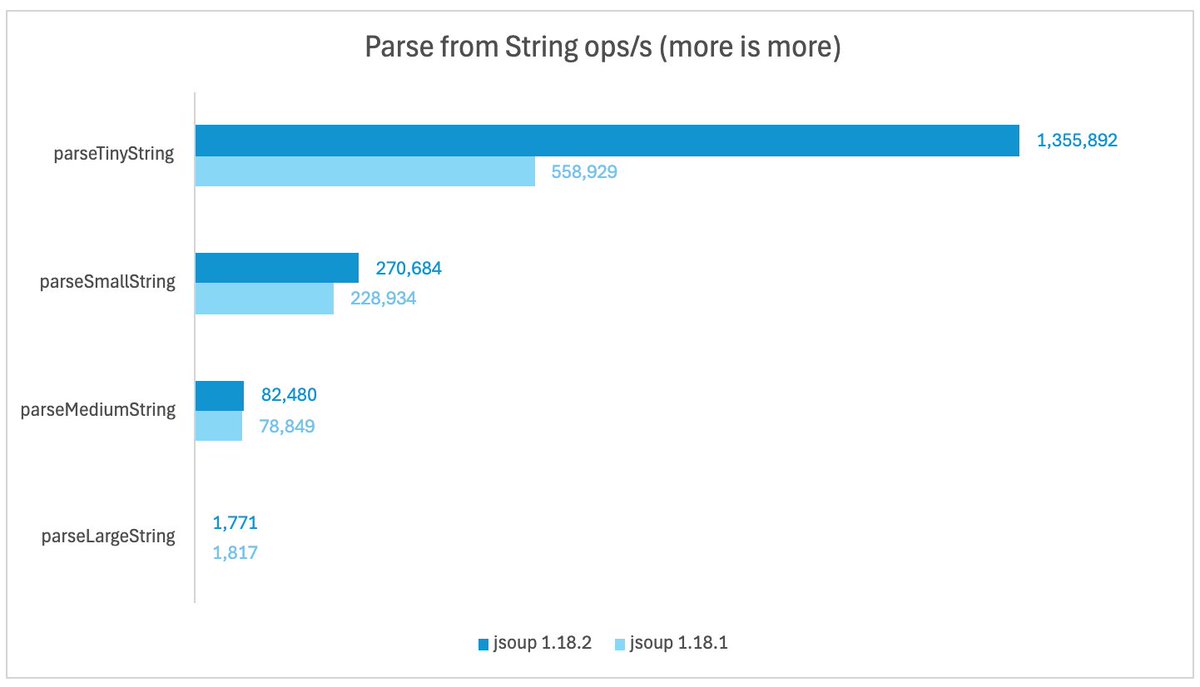
As a result, heap allocations (bytes/op) are down by -6% to -89%, and throughput has improved by -2% to 143% (with the biggest gains for smaller inputs).
These improvements will be in the next release of jsoup, 1.18.2 (coming soon!)
1
2
71
10 Jul 2024
I've just released jsoup 1.18.1! Lots of improvements - a StreamParser that acts like a hybrid DOM SAX parser; URL download progress callbacks, and lots of other improvements.
jsoup.org/news/release-1.18.…
2
6
180
5 Jan 2024
I've been working on a new feature for jsoup that I think is pretty cool: the new StreamParser lets you parse a document lazily with selectNext(query). Elements are parsed from the backing input stream on demand, and will include all their children.
github.com/jhy/jsoup/pull/20…
1
1
436
5 Jan 2024
If you're interested in this, please take a look at the implementation, and try it out by installing a snapshot. It would be great to incorporate any initial feedback / bug-fixes prior to releasing it in the next version of #jsoup.
115