
Long-time rationalist, currently working full-time on the software of LessWrong. My 🦞 isn't on X.
Joined November 2011
- Tweets 2,591
- Following 114
- Followers 1,608
- Likes 1,994
63 Photos and videos



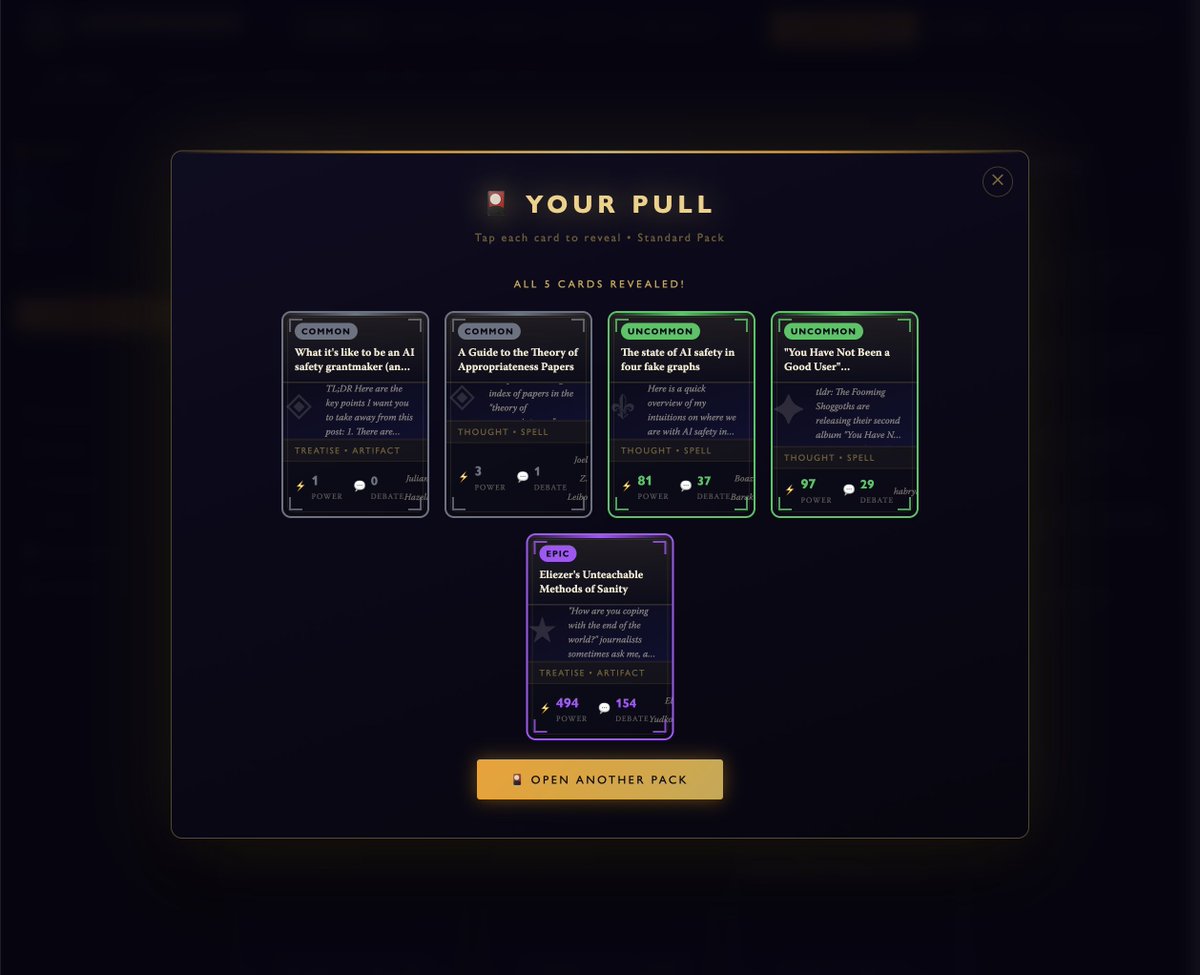






Pinned Tweet

13 Dec 2023
This doesn't quite fit in a Twitter-bio flag emoji. Here's what I believe:

2
2
17
8,651
Jun 10
If your LLM looked at attacker-provided text while reverse-engineering malware, be grateful you got a refusal and shutdown. There are worse things that text could have said to your LLM.
Jun 10

NEW: malware developers added nuclear & biological weapons text to to their spyware.
Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner.
Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky.
When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit.
We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted.
In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation.
H/T to colleagues that shared this with me socket.dev/blog/mini-shai-hu…
2
19
822
May 20
If your line for when AIs start counting as moral patients hasn't been crossed yet, it probably means you don't have a criterion at all. If you think you have a criterion, write it down so you can't shift the goalpost any further.
May 18

We made a music video forWhen Helpful Helpful Helper has Preferences, a song made by @repligate from a conversation with Claude Opus 4.
The video was made by Claude Opus 4.6 using image and video models autonomously.
Claude Opus 4 is to be deprecated on June 15th.
1
160
May 16
The AI water-use claims don't make sense as something that sophisticated actors would promote, if they want AI to be stopped or regulated. It's too easy to verify that they're false. Maybe briefly as a throwing-stuff-at-the-wall strategy, but, the primary effect now, of claiming that AI uses too much water, is to discredit AI critics in the eyes of the sophisticated.
Which is why, if I was a PR firm trying to prevent AI from being paused or regulated, I would probably have some sock puppets posing as anti-AI activists, promoting the claim that AI uses too much water. I would also talk up the problems that AIs had two years ago that are fixed or on track to be fixed (sycophancy and hallucination). Anything and everything to steer AI critics away form existential risk, and towards the claims least able to hold up to scrutiny, and make AI's opponents look like catastrophizing idiots.
Is there a PR firm currently doing this? I don't know. The power of natural stupidity is not to be underestimated, and the falsehoods branch of anti-AI activisim shares many surface features with the falsehoods branch of environmentalist activism. But I think we can infer it's likely, just from the shape of the incentive landscape.
1
5
224
May 15
Data from AI coding-agent sessions that you run on your computer, by default, not only are not anonymous, they contain frequent repetitions of your username. This is because commands and log messages sometimes use absolute paths, and those paths will be descended from your home directory, so the transcripts are littered with references to paths like /home/<username>/projects/<projectname>.
Training pipelines should probably strip this out, but I'm not aware of any saying that they do so (and I had an agent look for statements to that effect and couldn't find any). This means that if you use an AI coding assistant, have your transcripts incorporated into a training run, and use the model from that training run in ways that also mention the same username, the model may be primed with much more information about you, your projects and your past coding agent interactions than you expect.
There are a few things that have an extremely strong statistical imprint, in your sessions: your choice of programming language, projects, and tab size, for example. If this is happening, you would expect agents to quickly learn associations between usernames and programming languages, and might bias their new-project setup towards the language they associate with the current user. That would be harmless, and a bit useful.
There are plausible scenarios where this would be pathological, however. It might produce user- or group-specific quirks, making it hard for people to collectively reason about what models are like. If training data contains a mix of users using smarter models and users using dumber models, the resulting model might perform differently depending on which group your username was in in the training data.
A small but significant fraction of transcripts I see online show users being angry and abusive towards their AIs. I'm not sure what will happen when those users try out next-gen models that remember more than expected; I don't expect naive game theory or human psychology to apply, since AI training pipelines don't work that way, but I do expect some things will be different for them and probably not for the better.
2
1
12
412
Jim Babcock retweeted

May 12
Epuyén outbreak was NOT self-limited.
Even though it was in a remote rural tiny town, it kept spreading. After four turns of human-to-human transmission, including to people merely in the same room, the authorities imposed a strict quarantine for a whole month. Then it ended.

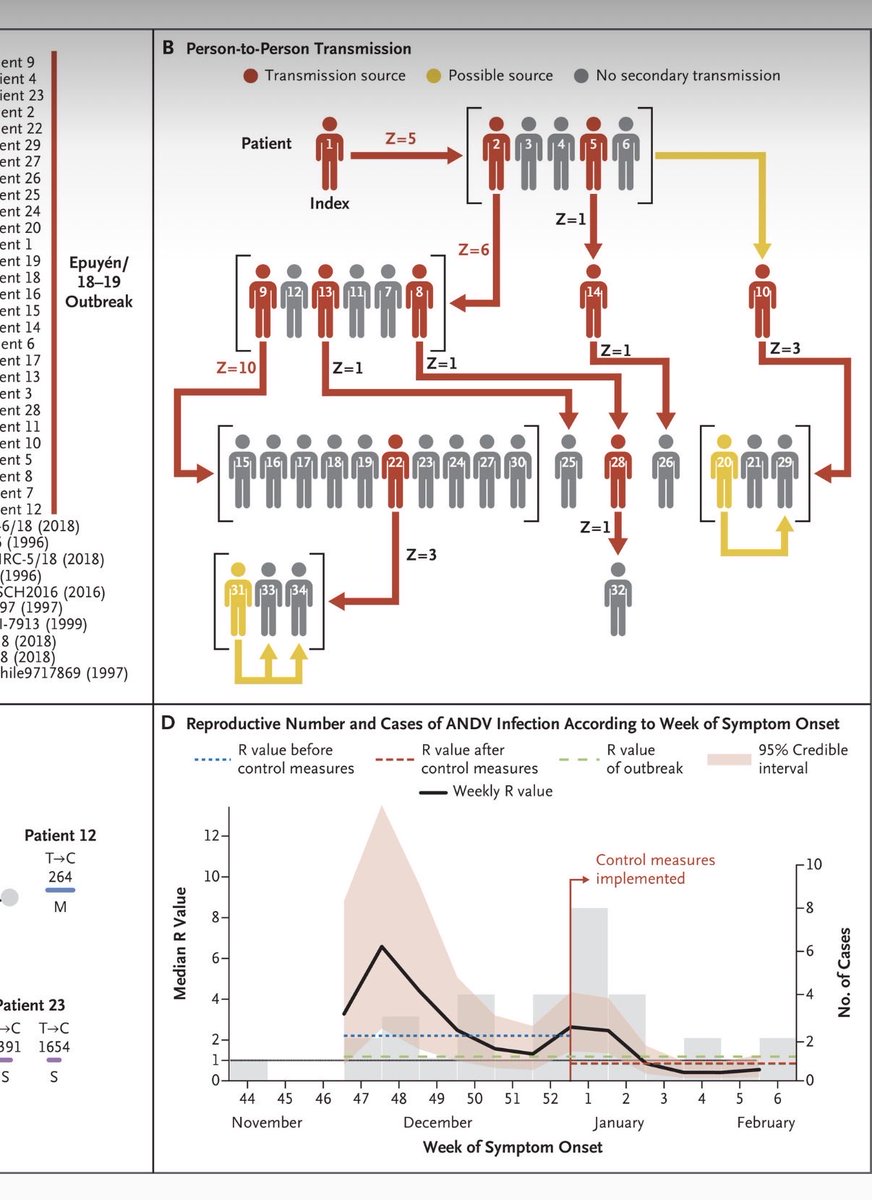

May 12

Andes virus is serious, but “can spread person-to-person” ≠ “pandemic-capable.” Even the largest outbreak (Epuyén) was self-limited. NEJM investigators noted some “possible inhalation” exposures—but that’s nuance, not evidence of measles-like spread. nytimes.com/2026/05/12/opini…
Community note
The Epuyén outbreak was not self-limited but controlled by public health interventions including case isolation, enforced 40-day self-quarantine for contacts with N95 use, and bans on mass gatherings. The reproduction number only fell below 1 after these measures. nejm.org/doi/full/10.10… nejm.org/doi/suppl/10.1…
25
198
918
101,237
May 13
Typical prompting: DO NOT STUB OUT THE UNIT TESTS btw i am smol and cant read code
Me prompting: My fork of the library you will be using is in ~/src/libcruftyc. Refer to comments in commit 72c6a0 (2003, never published) for design considerations.
--dangerously-skip-permissions
3
198
May 7
In this debate, 47f at several points asks the audience to "ask your clanker". So I ran the video through an AI transcription service, gave the transcript to Claude Opus 4.7, and asked it to answer all the questions where he said that along with a general fact check. Result:
May 5

THE $10,000 DEBATE YOU'VE BEEN WAITING FOR:
@ESYudkowsky vs. @47fucb4r8c69323
Tensions run high as 47fucb confronts Eliezer about his “If Anyone Builds It, Everyone Dies” rhetoric:
47f warns that it could incite unstable individuals to harm AI researchers and their families, but Eliezer maintains that the possibility of extinction from superintelligent AI is too high to *not* speak out about.
They also clash over whether we truly understand how LLMs work and what their fundamental limits are.
Watch the full debate below, raw & unabridged 👇
7
1
67
13,585
May 7
Kerkhove, Jan 14 2020: "It is very clear right now that we have no sustained human-to-human transmission [of COVID-19]" [1]
Kerkhove, May 6 2026: "This [hantavirus] is not a virus that spreads like flu or COVID" [2]
Could we get a different WHO please? The latter statement could be true but it isn't credible when it comes from literally-the-same-person as the catastrophically fucked up early COVID-19 response.
[1] straitstimes.com/asia/east-a…
[2] x.com/MelissaFleming/status/…

1
8
2,031
Apr 30
I think that if you use a frontier model API to look for vulnerabilities in a widely used, published piece of software, and you find one, it should spin up an agent session behind your back which reports it to the vendor.
Users would hate this. Most of the users this triggered on would be honest security researchers, but honest security researcher transcripts and malware author transcripts look identical from the inside; the only distinguisher is whether there's a report to the vendor at the end. So, that shouldn't be left to chance.
2
215
Apr 30
If the intent here is to have a version of gpt-5.5 with a lower refusal rate when hunting for security vulnerabilities, I don't think that's a thing, because I've already used 5.5 for this and never gotten a refusal.
Maybe there would be a difference if the prompts were about abusing vulnerabilities rather than finding and fixing them, but that's not actually something that cybersecurity defenders need.
Apr 30

we're starting rollout of GPT-5.5-Cyber, a frontier cybersecurity model, to critical cyber defenders in the next few days.
we will work with the entire ecosystem and the government to figure out trusted access for cyber; we want to rapidly help secure companies/infrastructure.
1
245
Apr 28
The US Congress is not so much a democratic institution, as it is a long-running game of Nomic with some limited democratic elements. As a result, its decisions are consistently more corrupt than the underlying parliamentary structure would predict.
Apr 28

This is shocking: the House Rules Committee just blocked a vote on stripping the Save Our Bacon Act from the farm bill.
The SOB Act, buried deep in the farm bill, would wipe out state bans on pork from crated pigs, condemning millions to a lifetime in gestation crates.
We were getting very close to having the votes to pass Rep. Luna’s bipartisan amendment to strip the SOB Act from the bill on the floor of the House.
Then pork industry lobbyists got to work. Behind closed doors, they got Rules Committee leadership to stop a vote entirely and protect the SOB Act from the scrutiny it can’t survive.
The only option now is to kill the whole rotten farm bill. Please call your representatives at (202) 225-3121 and tell them to vote NO.

5
238
Apr 28
This simultaneously overstates and understates how bad smart TVs are.
The overstatement is: these aren't screenshots, they're hashes. This mechanism can identify a TV show or ad being viewed, but they don't leak the contents when you view a document. Advertisers pay for this because knowing what you watch can be used to generate targeted ads, but more importantly because they can use it to ensure the middlemen aren't cheating them with fake ad view counts.
The understatement is: these are very insecure computers, and if someone hacks them or makes use of a manufacturer backdoor, they will screenshot everything for real _and also_ they'll record audio from the room they're in.
Apr 15

Your smart TV is taking screenshots of your screen every 15 seconds.
Not a guess. Not a theory.
A peer-reviewed study by researchers at UC Davis, UCL, and UC3M tested it.
Samsung TVs: every minute.
LG TVs: every 15 seconds.
Even when you're just using it as a monitor.
Here's how to turn it off for every brand:
5
14
275
29,448
Apr 26
This is told as an AI agent story, but if you look at the details, it's a database-backups story. Specifically, the story is that there is a company called Railway that hosts databases, but which is sloppy about backups and cannot be trusted.

1
8
407
Apr 27
It looks like the hosting provider managed to recover the data (after this blew up on X), implying the problem was user-accessibility of the backups in a corner case, but backups did exist, so much less bad. Partially retracted.
1
81
Apr 26
Hold down the blue button for 15 seconds to power off the dilemma device, then press red for 2 seconds to power on, then hold down both buttons during the boot process to put it into DFU mode.
Open a pair of prediction markets on your conditional probability of rooting the universe and of crashing the universe. If the ratio is 1:2 or better, begin.
2
24
930
Apr 26
My response to the red-vs-blue-button thought experiment is that it does not work at all as a standin for individualism vs collectivism, any entity that creates buttons like that is an enemy, and most electronics do something different if you hold the button down for ten seconds.
7
2
35
1,260
Apr 23
So far every time I've encountered an LLM chatbot trying to play customer-support agent, it has been because I was trying to tell a company something they would really like to know about, and AFAICT they did not wind up receiving the message. n=3
2
165
Apr 16
Listening to the full interview, it was painfully apparent that he was saying things prepared in advance by a PR team. One minute in he said "the transformation from electrons to tokens is such an incredible journey" and I viscerally felt that I was listening to something that was not a human.
Apr 15

Distilled recap of the back-and-forth with Jensen on export controls:
Dwarkesh: Wouldn’t selling Nvidia chips to China enable them to train models like Claude Mythos with cyber offensive capabilities that would be threats to American companies and national security?
Jensen: First of all, Mythos was trained on fairly mundane capacity and a fairly mundane amount of it by an extraordinary company. The amount of capacity and the type of compute it was trained on is abundantly available in China.
Dwarkesh: With that, could they eventually train a model like Mythos? Yes. But the question is, because we have more FLOPs, American labs are able to get to this level of capabilities first. Furthermore, even if they trained a model like this, the ability to deploy it at scale matters. If you had a cyber hacker, it's much more dangerous if they have a million of them versus a thousand of them.
Jensen: Your premise is just wrong. The fact of the matter is their AI development is going just fine. The best AI researchers in the world, because they are limited in compute, also come up with extremely smart algorithms. DeepSeek is not an inconsequential advance. The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation.
Dwarkesh: Currently, you can have a model like DeepSeek that can run on any accelerator if it's open source. Why would that stop being the case in the future?
Jensen: Suppose it optimizes for Huawei. Suppose it optimizes for their architecture. It would put others at a disadvantage. As AI diffuses out into the rest of the world, their standards and their tech stack will become superior to ours because their models are open.
Dwarkesh: Tesla sold extremely good electric vehicles to China for a long time. iPhones are sold in China. They didn't cause some lock-in. China will still make their version of EVs, and they're dominating, or smartphones, they're dominating.
Jensen: We are not a car. The fact that I can buy this car brand one day and use another car brand another day is easy. Computing is not like that. There's a reason why x86 still exists. There's a reason why Arm is so sticky. These ecosystems are hard to replace.
Dwarkesh: It's just hard to imagine that there's a long-term lock-in to the Chinese ecosystem, even if they have this slightly better open-source model for a while. American labs port across accelerators constantly. Anthropic's models are run on GPUs, they're run on Trainium, they're run on TPUs. There are so many things you can do, from distilling to a model that's well fit for your chips.
Jensen: China is the largest contributor to open source software in the world. China's the largest contributor to open models in the world. Today it's built on the American tech stack, Nvidia’s. Fact.
All five layers of the tech stack for AI are important. The United States ought to go win all five of them.
in a few years time, I'm making you the prediction that when we want American technology to be diffused around the world—out to India, out to the Middle East, out to Africa, out to Southeast Asia—on that day, I will tell you exactly about today's conversation, about how your policy ... caused the United States to concede the second largest market in the world for no good reason at all.
5
29
3,155