
Tech SEO | Automation 🦾🔥 🚀 | Insatiable Traveller | Street Art Enthusiast | Adventure Starter | Positivity Generator
Joined May 2011
- Tweets 3,284
- Following 949
- Followers 1,530
- Likes 4,655
1,063 Photos and videos











Pinned Tweet
Been meaning to revisit a few of my old projects and this is the first (public) one I wanted to do so.
Presenting. --> Google Index Checker 2.0 web app.
jlhernando.com/blog/google-i…
Login with your Google account, choose your property, paste the urls and get the results.
Enjoy!
1
4
555
If you already live in Google Sheets, Apps Script is the natural next step into automation. Same tool, no setup. Custom formulas, scheduled reports, BigQuery queries. All inside the spreadsheet you and your team already use.
This is the intro I wish I had when I got started.
jlhernando.com/blog/intro-go…
#seo #automation
1
4
145
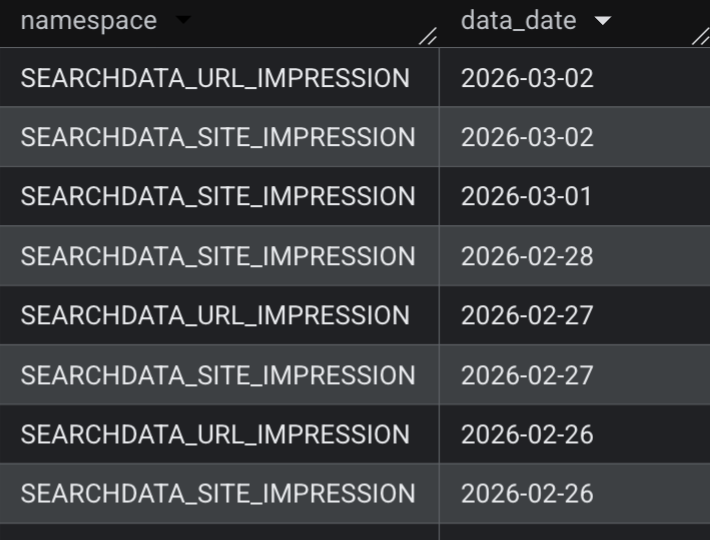
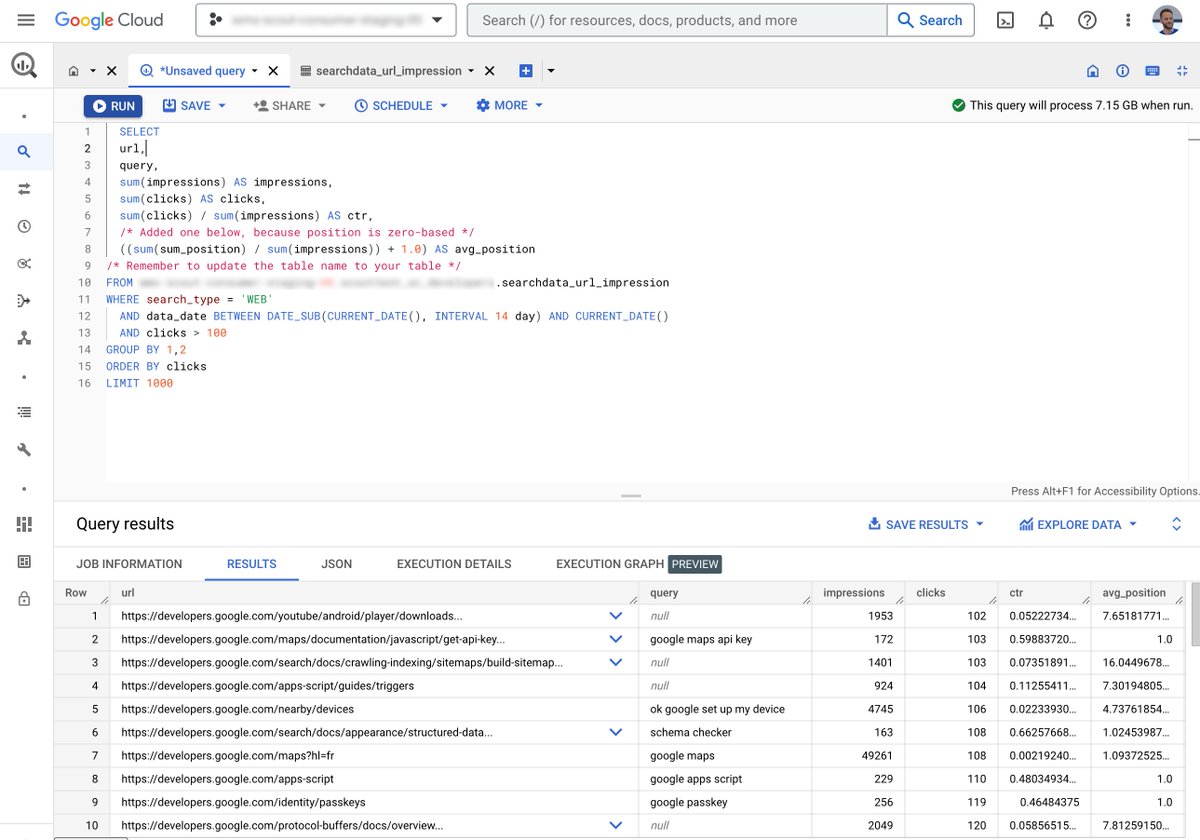
Recently we had to migrate our GSC bulk data export to a completely different GCP project after Adevinta Spain was acquired by EQT Group.
I couldn't find much info in the official docs about this specific scenario, so together with the data engineering team we worked out a process that kept every day of data intact and it's now running without issue in our infra.
I've put together a guide with the full steps we followed in case anyone runs into the same thing.
jlhernando.com/blog/gsc-bulk…
1
4
171
SEO Automation is more accesible than ever. If you know me, you know I have a clear favourite (despite its reputation in SEO...)
JavaScript!
I wrote about how easy and practical it is to get started. Browser, Nodejs or Apps Script.
Choose you own adventure!
jlhernando.com/blog/javascri…
1
6
129
Jose Luis Hernando retweeted

Feb 24
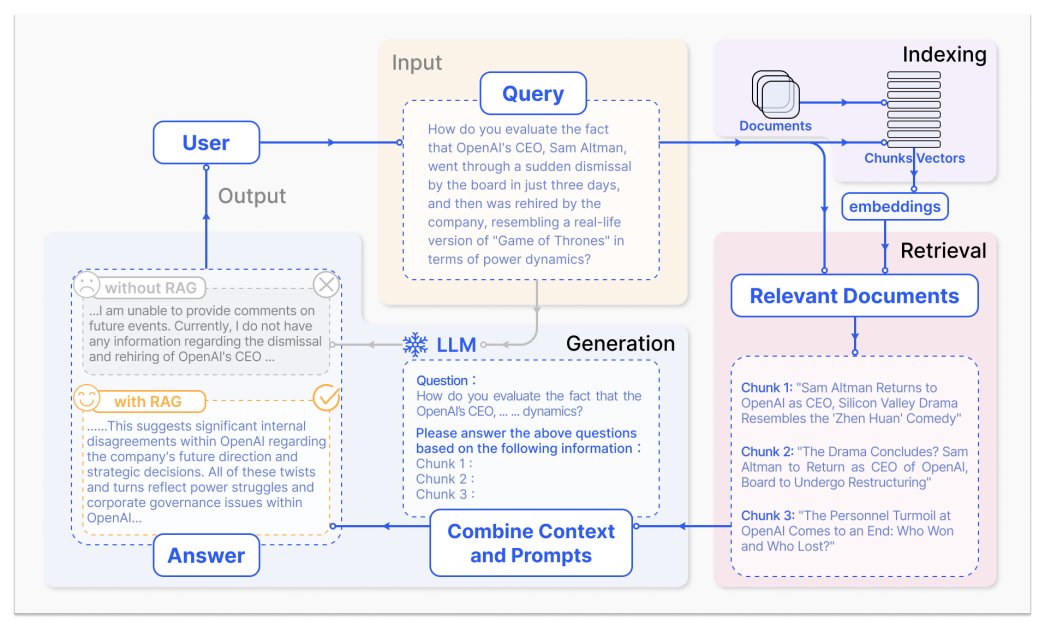
"LLMs favor content that does X" is not a thing!
LLMs don't favor anything. They're not information retrieval systems; they're next-token predictors. They guess the most statistically likely response based on patterns in training data.
The search engine layer bolted on top via RAG? That's IR (Information Retrieval)!! The base LLM model? Not even close.
During training, LLMs process text from across the web, but they don't log URLs, store sources, or remember where anything came from. What's left is a frozen statistical snapshot (Gao et al., 2023). Not an index. Not a database.
Search engines do the crawling, indexing, and retrieval. LLMs lean on them heavily to surface real-time info (because on their own, they can't).
Stop optimizing for 'AI.' Optimize for search engines (so retrieval-based AI can cite you) earn third-party coverage (so the model already knows you before the prompt is typed).
9
23
108
8,732
Made a chrome extension to grab all Index status data from your Google Search Console in one click, for all your properties.
Couldn't do a big write up explaining (it was my birthday on Sunday 😅) but i've tried to put all the essentials there.
jlhernando.com/blog/gsc-inde…
Toodles!
2
7
39
5,705
If you ever wanted to get into SEO automation this is the time. Go wild!
My new stack for SEO Automation: Claude Code Apps Script jlhernando.com/blog/claude-c…
1
2
92
@antoineripret next in the pipeline is Dataform (now in easy mode😬)
69

25 Nov 2025
I like Search Console’s Compare view. BUT
I hate doing the maths in the UI.
So I built a tiny Chrome extension that overlays absolute and % change directly on the scorecards.
No more mental calculations or spreadsheets.
Try it. Let me know!
jlhernando.com/blog/search-c…
1
136
28 Apr 2025
Hola SEOs!
Anyone else seeing 22nd of Apr as the latest available date in Bulk Export?
@estevecastells @antoineripret @JohnMu @danielwaisberg @rustybrick
#seo #searchconsole
4
2
437
15 May 2024
Simple & straightforward explanation of the 3 ways you can use to get GSC data (with examples) - 🔥 article by @antoineripret
buff.ly/4dSPPHV
150
13 May 2024
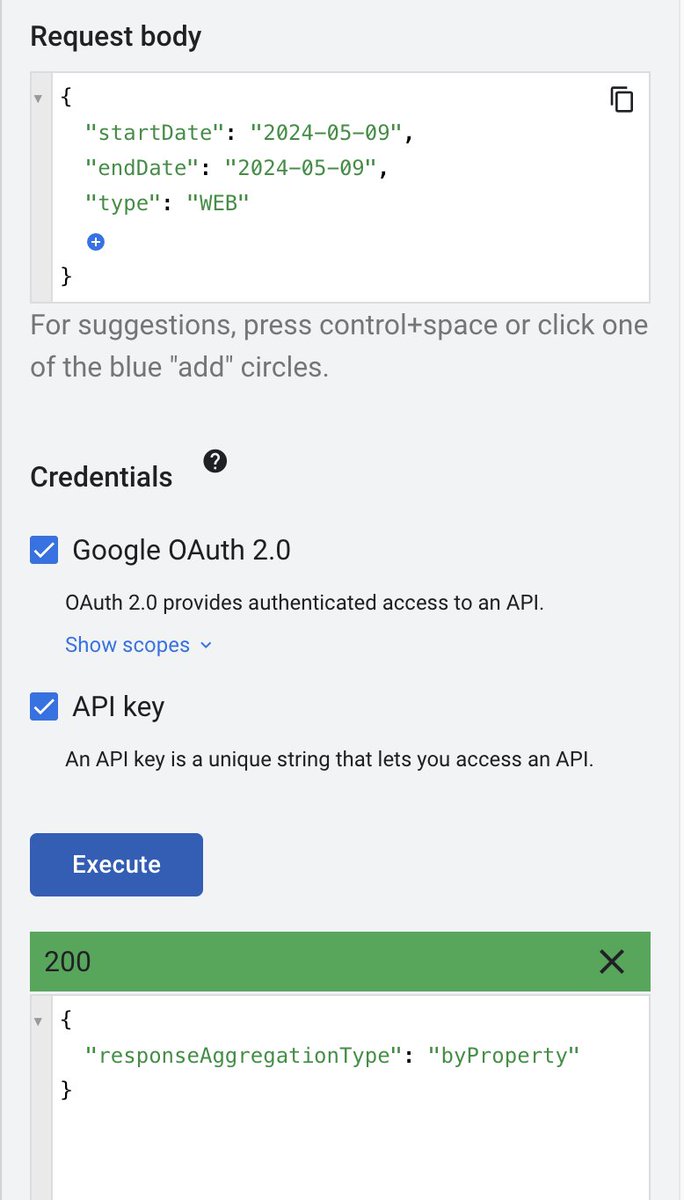
Hi SEO Twitter anyone else having issues extracting data from the GSC API data since 2024-05-09? @danielwaisberg @googlesearchc
2
3
2,160
5 Jul 2023
It's been a while since I've published anything out in the wild. I'm ending that today.
I saw this tweet form @chuisochuisez & I thought it would be fun to do it as a standalone app (while learning a bit of NextJS 13 in the process)
🚀 Launching V1--> transcriptextractor.com/
16 Jun 2023

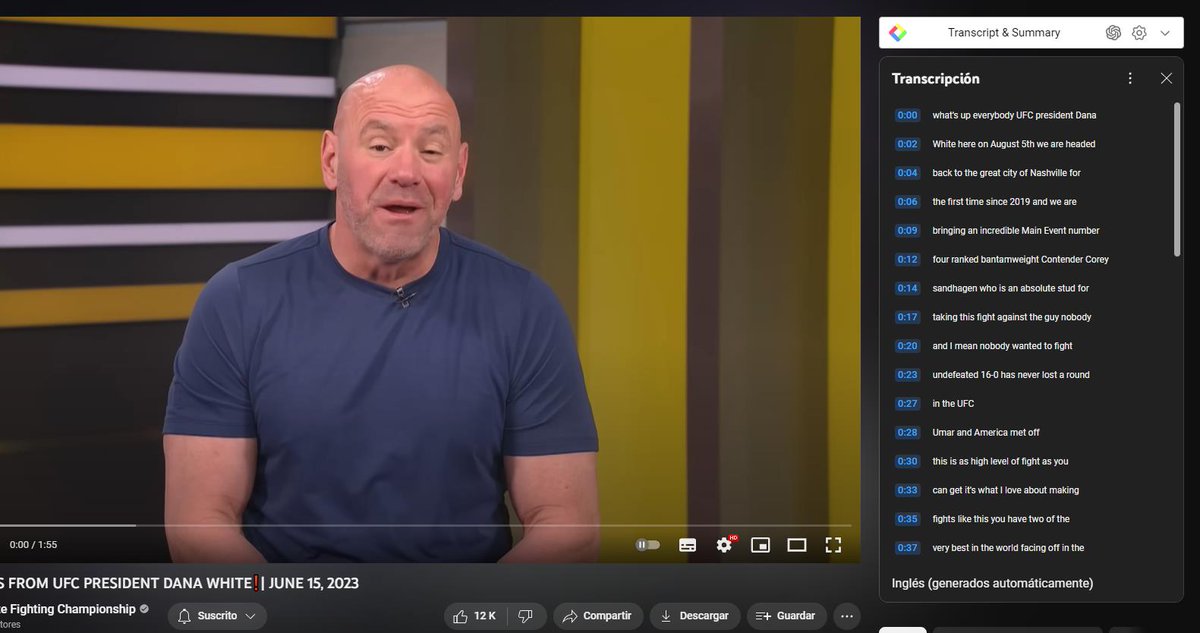
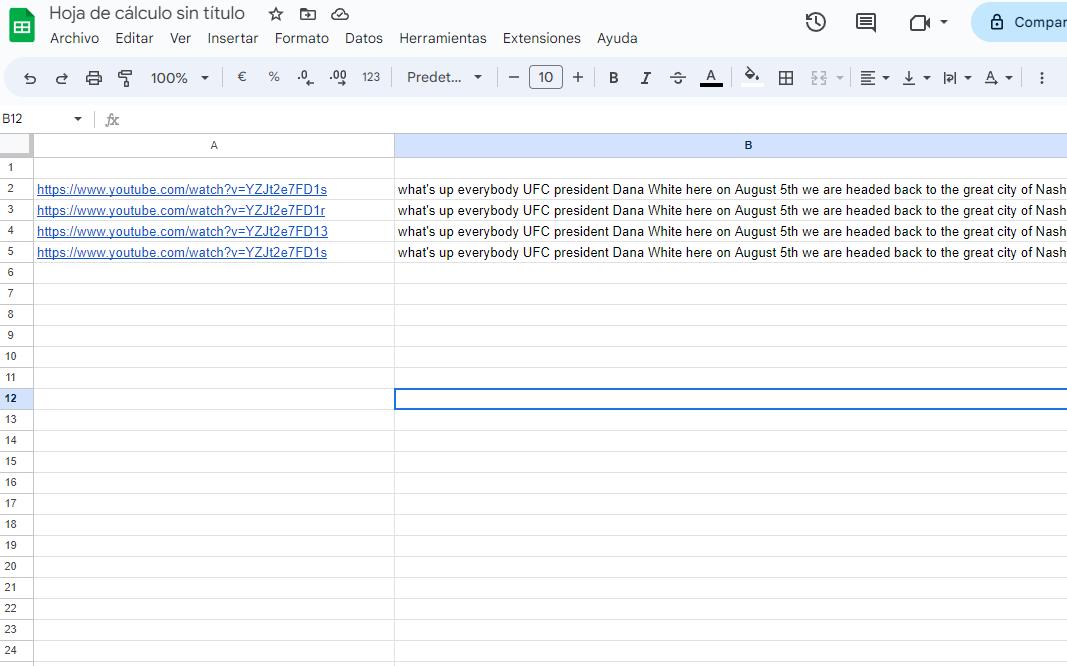
¿Veis factible un script que funcione en Google Sheets para extraer las transcripciones de listas de URLs de Youtube? Eliminando marcas de tiempo y unificando el contenido, que quede algo como la segunda imagen? Alguie se anima? Tengo ideas perversas xD
2
4
9
2,218
5 Jul 2023
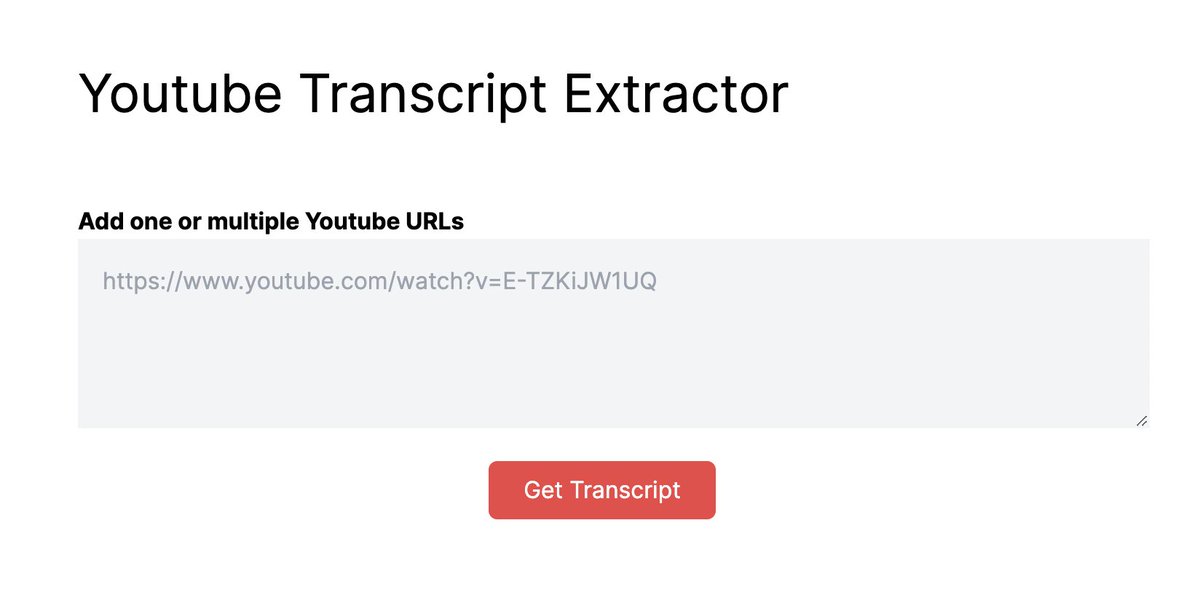
To download a transcript from Youtube simply:
- Get one or multiple URLs from Youtube
- Paste the in the text box
- Press "Get Transcripts"
- Wait for the app to extract the transcripts
- Once it's done, download the result in a CSV file
Easy peasy 😎
1
3
262
5 Jul 2023
I have a few upgrades in mind but feedback and new ideas are very welcome 😉
Have fun!
3
1
140
Jose Luis Hernando retweeted

3 Jul 2023
I just published my first article on the Adevinta Tech Blog. If you are curious about how we are leveraging AI and you would like to get some ideas on how to prepare for the future of SEO then look no further.
medium.com/adevinta-tech-blo…
2
2
8
1,292
Jose Luis Hernando retweeted

16 Jun 2023
¿Veis factible un script que funcione en Google Sheets para extraer las transcripciones de listas de URLs de Youtube? Eliminando marcas de tiempo y unificando el contenido, que quede algo como la segunda imagen? Alguie se anima? Tengo ideas perversas xD
6
1
12
14,201
Jose Luis Hernando retweeted

If you work with Node.js and Google apis you’ve probably at one time or another been frustrated at Node not being supported by one or more APIs.
No longer.
I give you sdkbuilder which will build out a node.js sdk of google apis. gist.github.com/sterlingsky/…
1
4
10
2,743
Jose Luis Hernando retweeted

27 Mar 2023
Following feedback from the community, today we're updating bulk data exports to allow multiple GSC properties to export to one Cloud project. To do so, you need to customize your dataset name when setting up your export to have a unique dataset name for each export.
21 Feb 2023

Today, we're announcing 📢 bulk data export 🎉- a new feature that allows you to export data from Search Console to Google BigQuery on an ongoing basis. developers.google.com/search…
12
105
285
82,947