
co-Founder NeuralFabric acq. by @Cisco | co-Founder @IntWorkAll | Board @GBBC_io | General Manager @Microsoft | Phd RL research @UMassAmherst
Joined June 2019
- Tweets 7
- Following 1,956
- Followers 9,608
- Likes 11
Photos and videos
Pinned Tweet

25 Aug 2025
A Public AI Wealth fund, not 'basic income'. It is time for Congress to act.
thehill.com/opinion/technolo…
10
9
66
61,227

LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵

5
41
252
86,928
John deVadoss retweeted

May 22
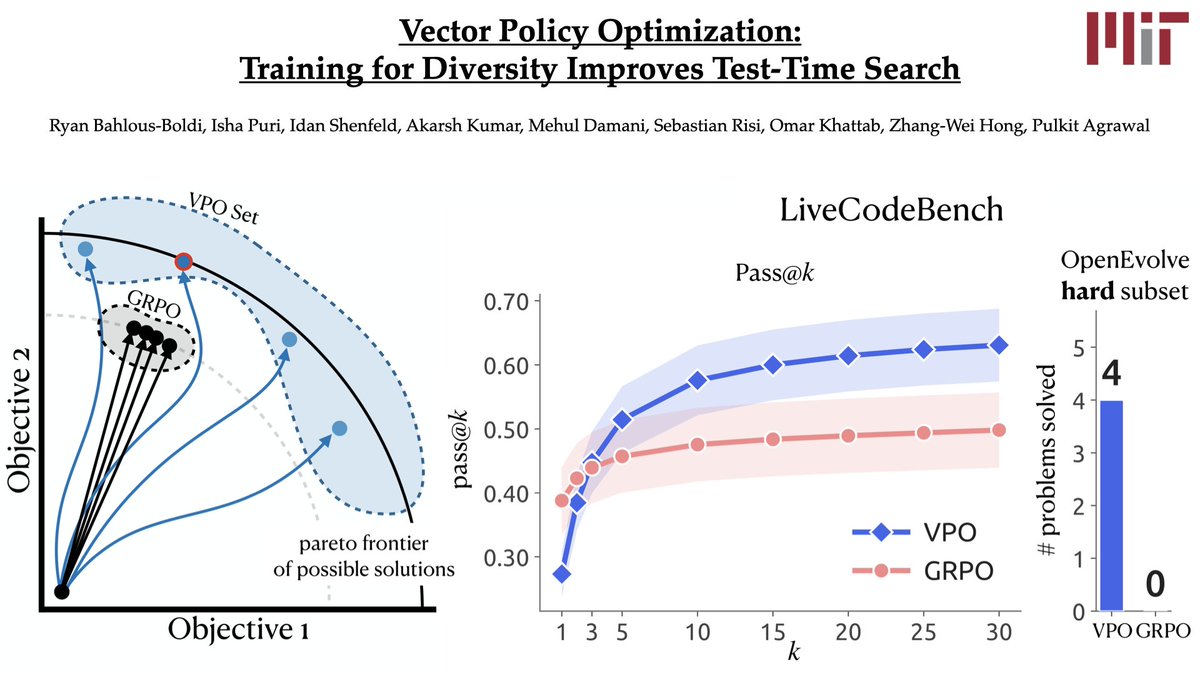
Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
34
121
862
212,690
John deVadoss retweeted

🚨Typical RL algorithms and on-policy distillation methods are blind samplers: they use privileged info to score rollouts, but not to *find* them.
We ask: can we use privileged info to *actively sample* the rollouts RL wishes it can stumble upon with compute?
⤵️ Pedagogical RL

16
87
498
114,489
John deVadoss retweeted

Don’t Regulate AI Models. Regulate AI Use. spectrum.ieee.org/ai-model-r…
2
4
5
1,377