
Real-time web access for your AI
Joined September 2018
- Tweets 167
- Following 3
- Followers 1,467
- Likes 153
56 Photos and videos













May 27
Most teams build their plumbing when they should buy it.
That was Prague Crawl 2026. 100 engineers and founders. One question: build or buy.
The answer: depends on whether it's your product or your infrastructure.
Most teams get that backwards.
Already planning 2027.

2
143
May 26
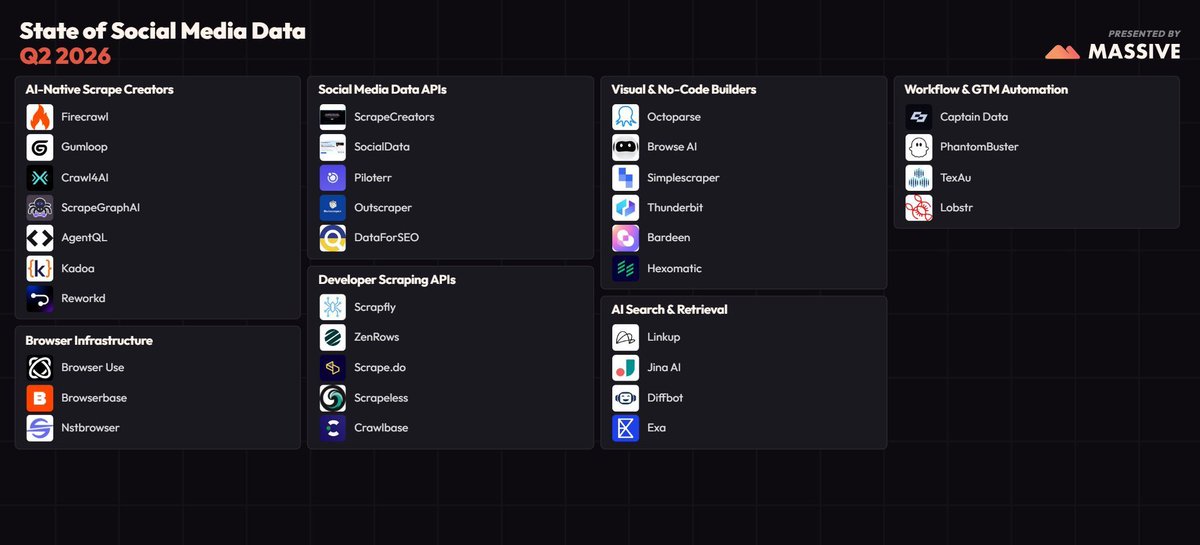
State of social data collection, Q2 2026: 34 companies across 7 layers.
Scraping used to mean code that broke every time a page changed. Now you describe the data and a model does the rest.
AI killed the CSS selector.
1
2
545
May 25
2 ms. That is how far our infrastructure sits from the major cloud providers.
A lot of AI workloads run inside AWS, GCP, or Azure. The layer feeding them doesn't, and every request pays for the distance.
@DataPacketcom, our infra partner, published the numbers behind it.
1
3
1,071
May 22
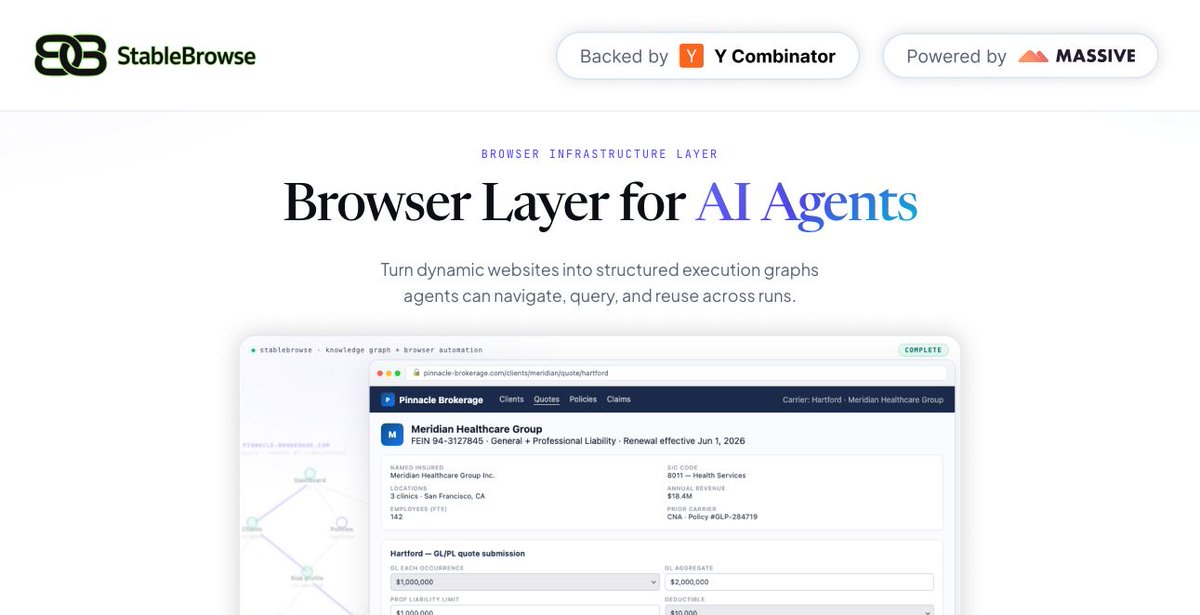
A demo agent and a production agent are not the same product.
In production, the agent reads pages by screenshot, guesses what's interactive, breaks on a layout change.
@StableBrowse owns the page. Massive owns the path to it.
1
4
399
May 21
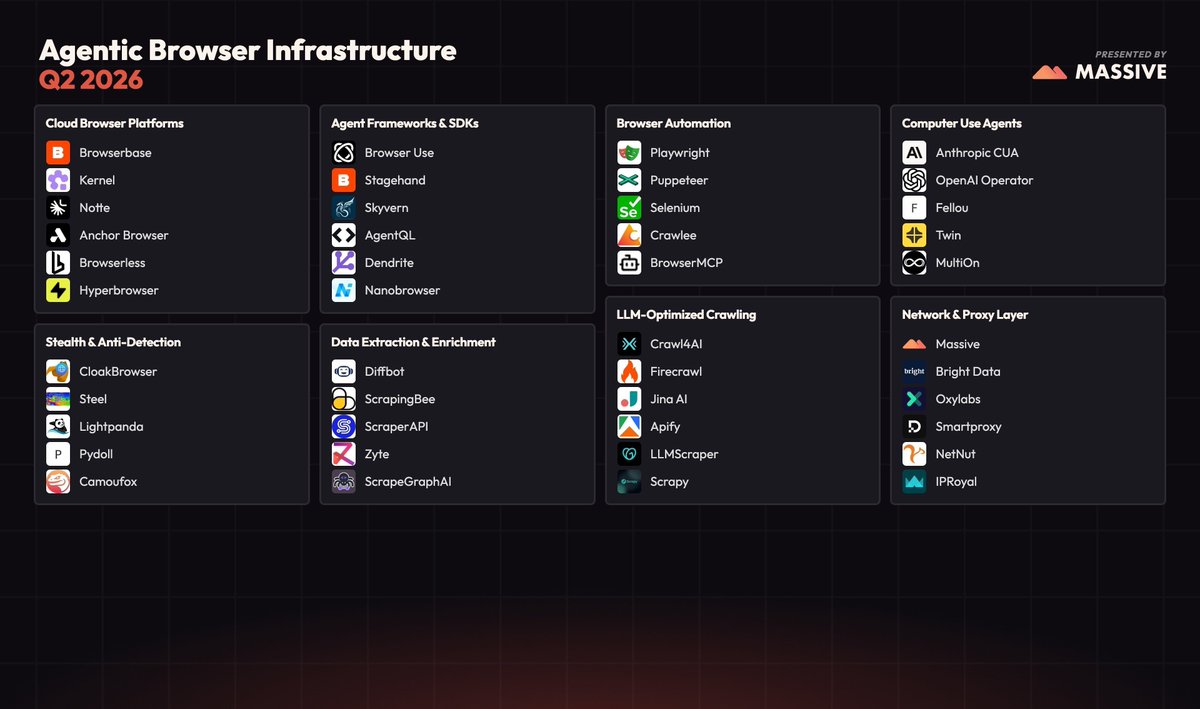
"Browser agent" isn't a product. It's a stack of eight layers.
Most teams building agents only think about one or two of them. We mapped all eight.
2
2
235
May 20
How to raise a $10M seed round.
@mrjasongrad just gave that talk on the Prague Crawl main stage, to a sold-out room.
The straight version most founders never get.

1
4
229
May 19
Tomorrow.
@browserbase @Dentons @scrapegraphai @Centric_PLM @Crawly @make_hq @DataPacketcom @HypeProxiesio
250 engineers, founders, data teams.
Last tickets close tonight. Walk-ups won't get in.
2
1
6
378
May 18
Most newsletters cover launches.
@pigivinciguerra covers what's actually breaking. Anti-bot evolution. Vendor moves. The messy stuff.
@webscrapingclub at Prague Crawl, May 20.
Talk: Still Waiting for LLMs to Replace My Scrapers.
1
1
87
May 14
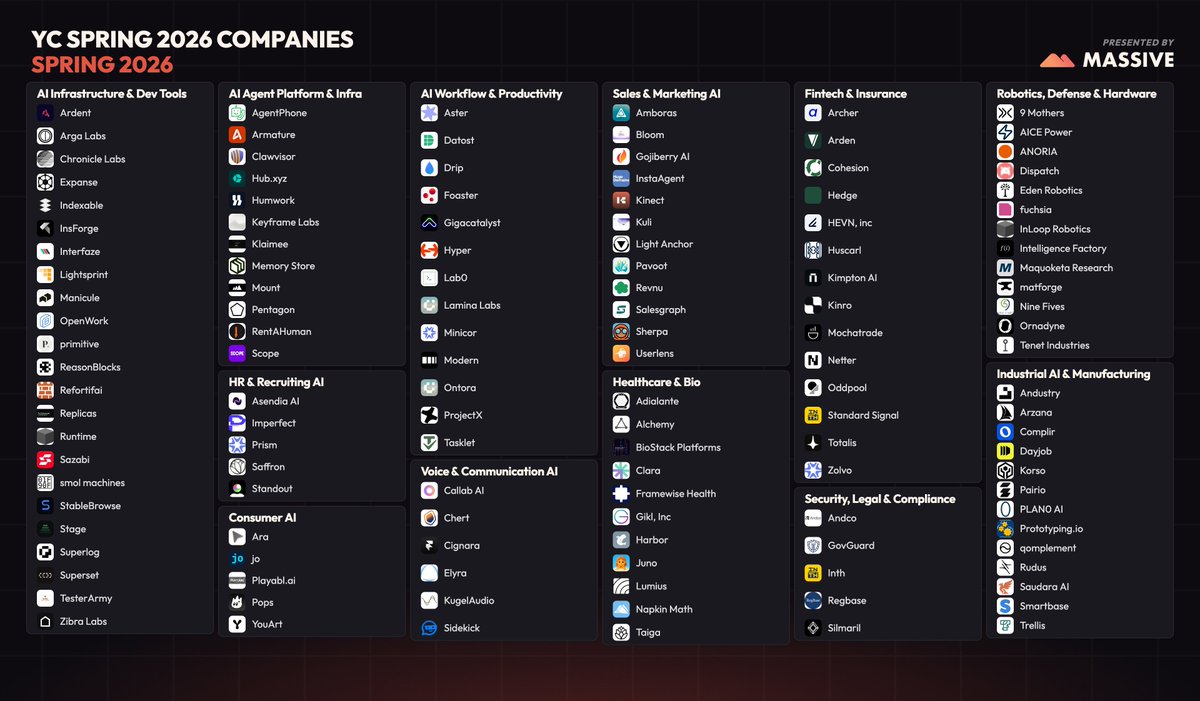
YC Spring 2026 in one line:
AI infrastructure is the biggest category. Consumer AI is one of the smallest.
These founders are selling tools to the people building the apps.
1
2
105
May 14
Old way: Write the selector. Site changes. Selector breaks. Rewrite. Repeat.
@scrapegraphai's way: Describe what you want. The LLM does the rest.
One of the most-starred open-source scraping projects on GitHub. The team is at Prague Crawl, May 20.
1
2
113
May 13
Most web scraping conversations skip the part that gets companies sued.
Štěpánka Havlíková won't.
@Dentons will be at Prague Crawl, May 20.
Talk: Scraping v. Law: 2025 EU cases.
1
3
85
May 12
Every agent that books a flight, fills a form, or scrapes a price - runs through a browser.
That's the new infrastructure layer and @browserbase is building it.
2
2
93