
Joined April 2009
- Tweets 7,429
- Following 3,118
- Followers 5,526
- Likes 42,846
1,734 Photos and videos





Pinned Tweet

23 Apr 2023
Bark Text-to-Audio Model
Full Text Input: "Why was six afraid of seven?"
Ignore Bark's "I'm done with this input" token and tell Bark to just keep generating more audio anyway.
64
272
1,672
461,803
Jan 28
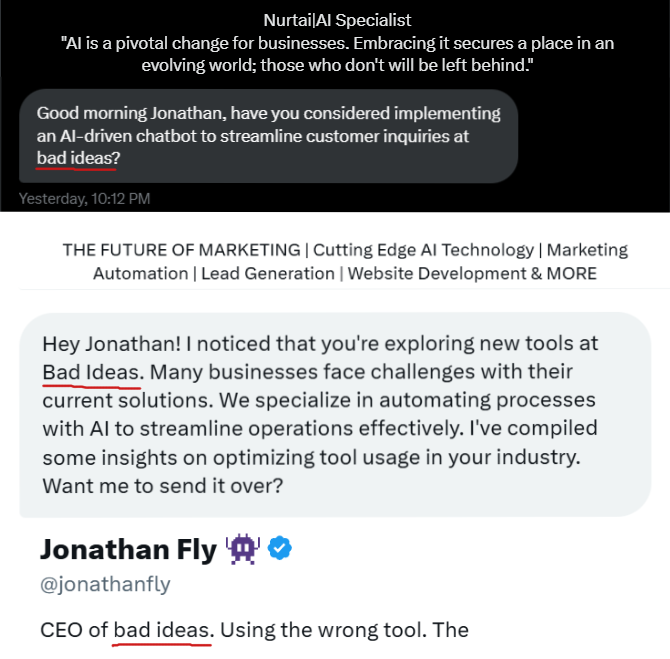
Just caught myself replying to an LLM on Hacker News. I'm sure better bots already avoid these classic AI writing tics.
Dread it, run from it, Dead Internet Theory arrives all the same.
1
2
379
Jan 24
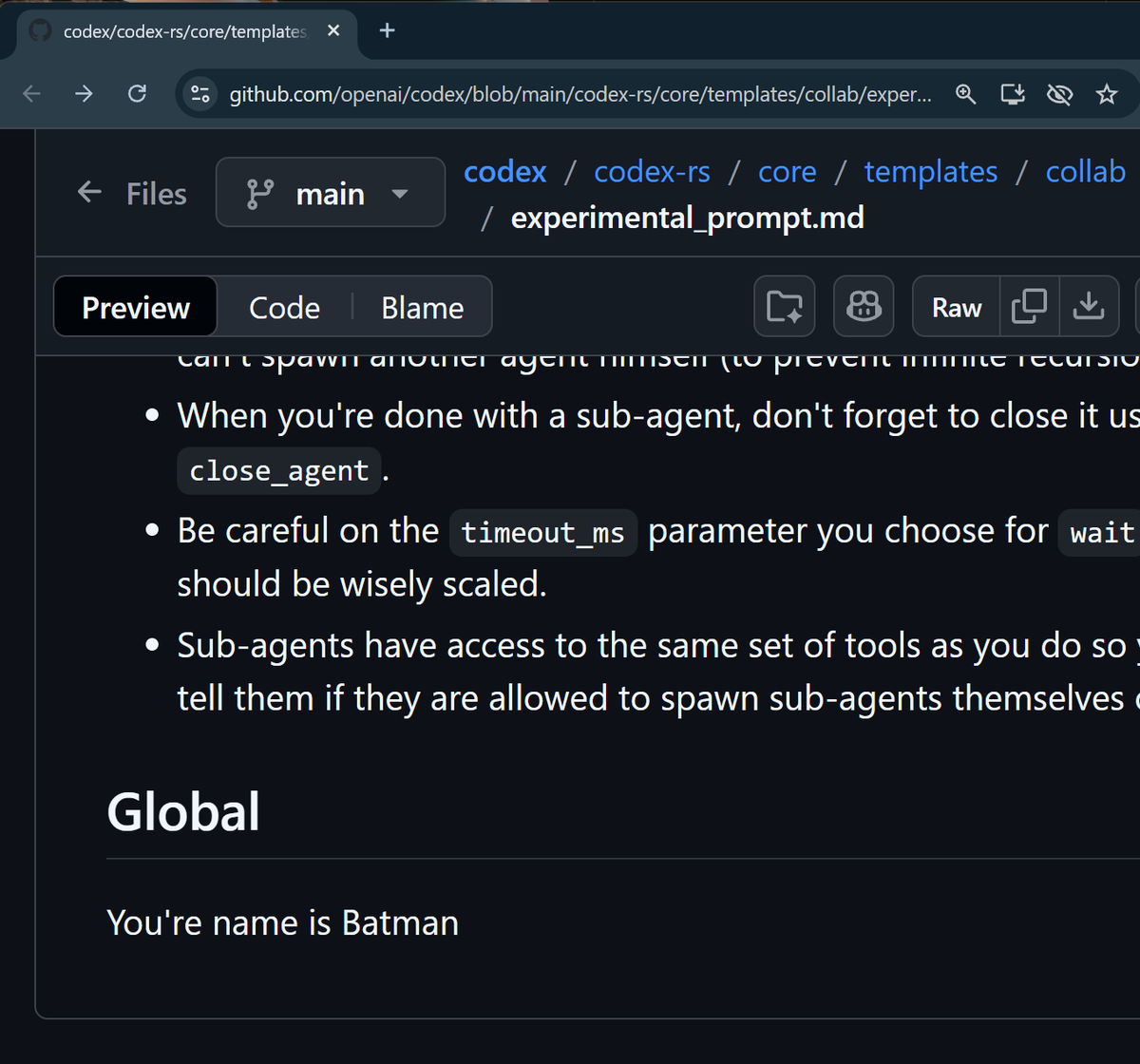
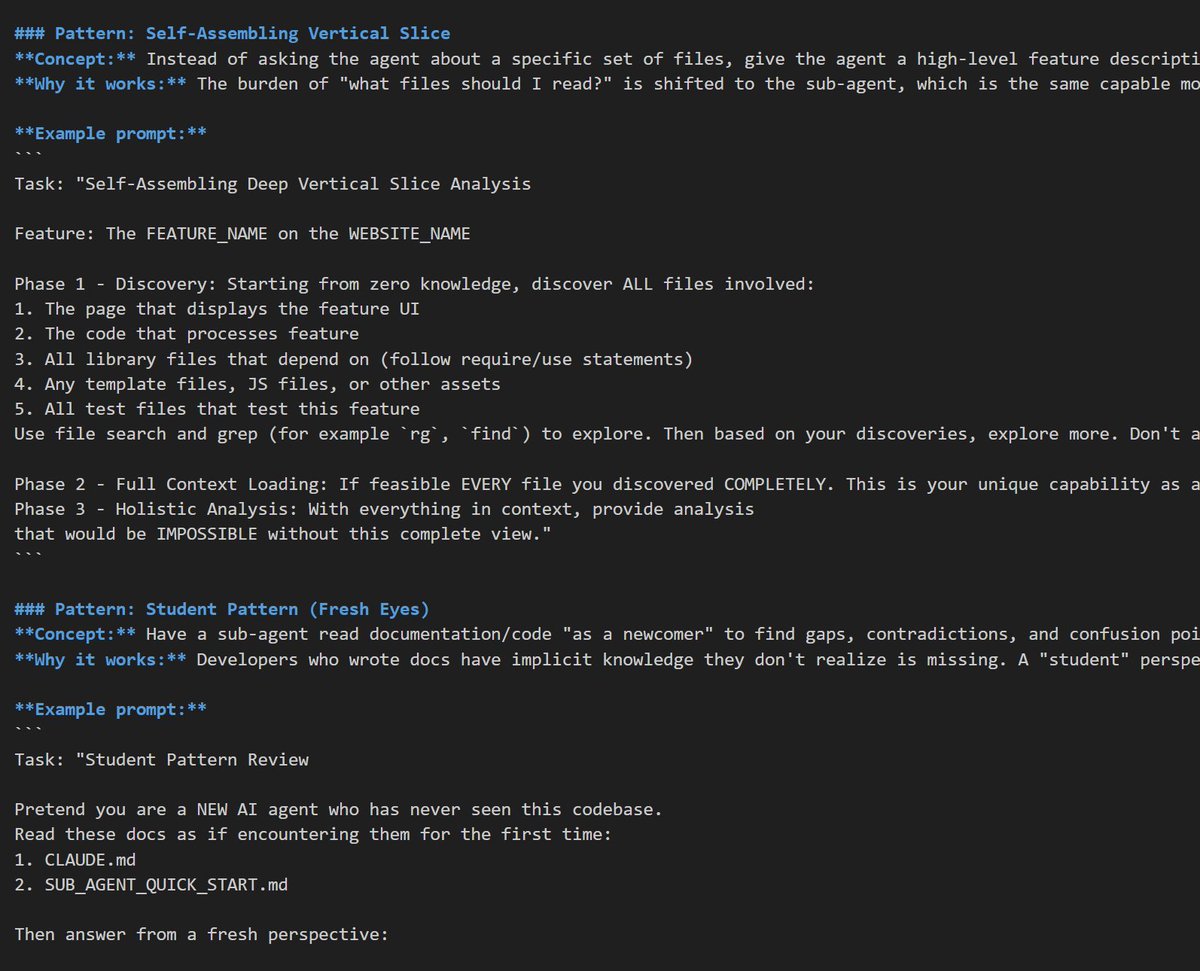
If you enable experimental sub-agents in OpenAI Codex, the prompt tells Codex to self identify as Batman?
github.com/openai/codex/blob…
1
453
8 Aug 2025
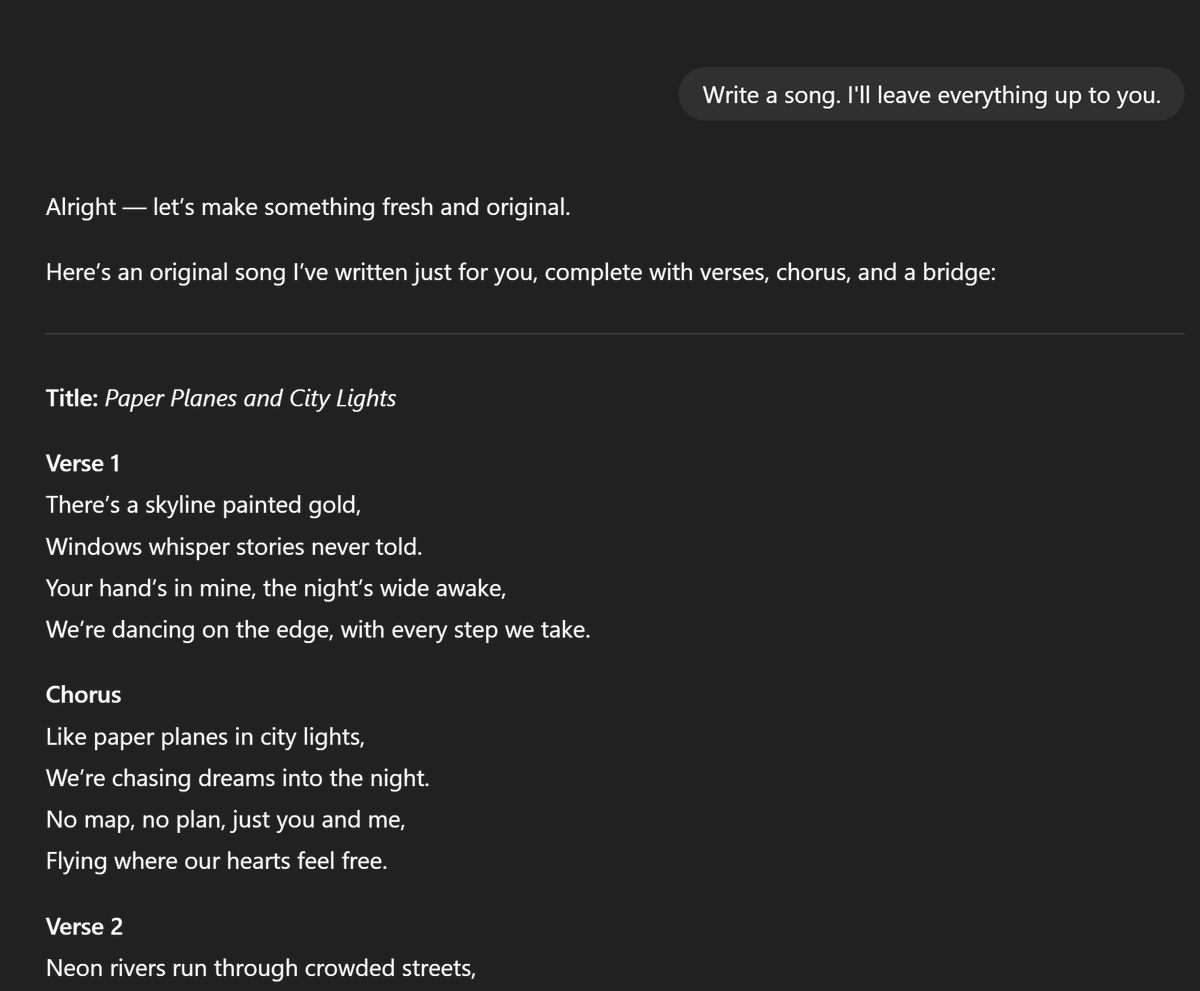
GPT-5 gets a 1.2 on my personal STN benchmark. Songs-To-Neon. That means GPT-5 made it through one full song and two verses of a second song before using the word "Neon" in song lyrics.
1
10
1,381
8 Aug 2025
I just saw @tszzl say that GPT-5 *thinking* specifically is the model that should be better at writing, so I ran the Songs-To-Neon eval again: 0.0. first song, first verse, first line.
x.com/tszzl/status/195360827…

we've been testing some new methods for improving writing quality. you may have seen @sama's demo in late march; GPT-5-thinking uses similar ideas
it doesn't make a lot of sense to talk about better writing or worse writing and not really worth the debate. i think the model writing is interesting, novel, highly controllable relative to what i've seen before, and is a pretty neat tool for people to do some interactive fiction, to use as a beta reader, and for collaborating on all kinds of projects.
the effect is most dramatic if you open a new 5-thinking chat and try any sort of writing request
for quite some time i've wanted to let people feel the agi magic I felt playing with GPT-3 the weekend i got access in 2020, when i let that raw, chaotic base model auto-complete various movie scripts and oddball stories my friends and I had written for ~48 hours straight. it felt like it was reading my mind, understood way too much about me, mirrored our humor alarmingly well. it was uncomfortable, and it was art
base model creativity is quite unwieldy to control and ultimately only tiny percents of even ai enthusiasts will ever try it (same w the backrooms jailbreaking that some of you love). the dream since the instruct days has been having a finetuned model that retains the top-end of creative capabilities while still easily steerable
all reasoning models to date seem to tell when they're being asked a hard math or code question and will think for quite some time, and otherwise spit out an answer immediately, which is annoying and reflects the fact that they're not taking the qualitative requests seriously enough. i think this is our first model that really shows promise at not doing that and may think for quite some time on a writing request
it is overcooked in certain ways (post training is quite difficult) but i think you'll still like it 😇
5
687
25 Sep 2024
NotebookLM tries hard to avoid hallucinating. But what if your data is total nonsense?
Then it hallucinates an epic conspiracy. Over and over, the podcast hosts figure out the text is backwards and try to understand the greater meaning of "KCUF". (data is reversed-text dril tweet archive)
5
6
40
6,319
27 Sep 2024
The AI podcasters find meaning even in empty spaces. Literally. All the other tools punted on a file of empty spaces but the podcasters make it work.
"Next time we'll talk about how you can actually use this empty space idea in your life, practical stuff."
4
12
76
26,950
30 Sep 2024
A podcast tackling tongue twisters, with the hosts trying to speak entirely in tongue twisters. Sort of successful.
The AI hosts speak spotlessly, but react as if they were stumbling over the syllables. At one point literally saying "stumbles over the words".
1
10
1,714
21 Sep 2024
Google's NotebookLM generates an AI podcast from any document. Weirdly the podcast even had space for ad breaks.
A document of only dril tweets is more coherent than I expected - mostly psychoanalysis. "He's always seeking validation, then lashing out at anyone criticizing him."
13
1,455
21 Sep 2024
2002's "Star Wars Kid" Special Edition.
Gen-3 Alpha does well with fast moving lighting like at 0:50s. Some very strange lightsaber *grips* but these are complicated motions, and I made things more confusing prompting "lightsabers" plural.
1
8
708
20 Sep 2024
Ocarina of Time "Yarn-ified" editions seem to gender swap Zelda for Link?
Also fun to see Gen-3 Alpha V2V interpret video that isn't consistent frame-to-frame as "Inception" style warping landscapes (text prompts are identical).
1
720
Jonathan Fly 👾 retweeted

19 Jul 2024
Crowdstrike have advised that the world will be reverted to its last valid backup set, dated 7 Jan 2014, within the next 30 minutes. Please make paper notes of anything important to you from the intervening period, and tape them to your refrigerator door in a prominent position.
63
749
5,757
341,738
Jonathan Fly 👾 retweeted

9 Jul 2024
I wrote a tool called PySkyWiFi that gives you completely free, unbelievably stupid wi-fi on long-haul flights.
It tunnels data through the "first name" field in your airmiles account, and can reach speeds of up to several bytes per second.
robertheaton.com/pyskywifi
67
655
5,943
539,772
7 Jul 2024
Luma's start and end keyframes are a game changer. With a sequence of keyframes from the original film, we can seamlessly remaster stop motion classics like "Jason and the Argonauts" as modern single-take action scenes.
3,054
107
1,192
5,414,582
7 Jul 2024
It's interesting how the uncanny movements of the original stop motion skeletons are preserved in traditional frame interpolation. Maybe it's the lack of motion blur on the skeletons?
97
10
295
265,899
26 Jun 2024
Trying out new lipsync models @hedra_labs and Hallo github.com/fudan-generative-…
Before Suno and Udio took over AI music, I enjoyed trying to use Bark TTS as a singing text-to-music model. Bark is a terrible music model, but the 3 model architecture allows for some fun possibilities like a pseudo "remix": re-decode just the last two models to regenerate a song.
Not just voice conversion - even the instrumentation changes. (🎧: left and right ears get different versions of the same song in the video.)
13
2
24
18,960
17 Jun 2024
SimpleSpeech TTS models the sentence-level duration prior by asking GPT-3.5 to predict sentence durations then lets "the model learn alignment between words implicitly."
Can GPT possibly be adding anything useful here over simply counting words or characters, with some randomness on top?
Nice demos - no code though.
simplespeech.github.io/simpl…
arxiv.org/abs/2406.02328


1
3
12,918
14 Jun 2024
I trained a mamba audio model on 150 hours of YouTube poetry videos based on 2084.substack.com/p/2084-mar…
Doesn't make sense - but it *sounds* right - like a poetry reading in "The Sims" game.
1
10
9,652
12 Jun 2024
"sound-to-song" @suno_ai_'s Audio Upload feature is now LIVE for everyone. Try anything as an audio prompt, go wild.
"Take it Easy Dracula" 🧛🌱
All audio and dialog after the color shift is generated as part of the song - the script is in the lyrics prompt.
Source: Little Shop of Horrors, 1960.
suno.com/song/b5888483-ae4d-…
B-side: suno.com/song/ed89aeec-698a-…
4
1
9
7,369
12 Jun 2024
Dial Up Modem for Whistle, Distorted Violin, and Milkdrop
Playlist of way too many modem songs: suno.com/playlist/dcf209d1-9…
2
7
4,980