
Joined October 2018
- Tweets 94
- Following 406
- Followers 395
- Likes 277
6 Photos and videos



Going to @ICLR2026!!✈️
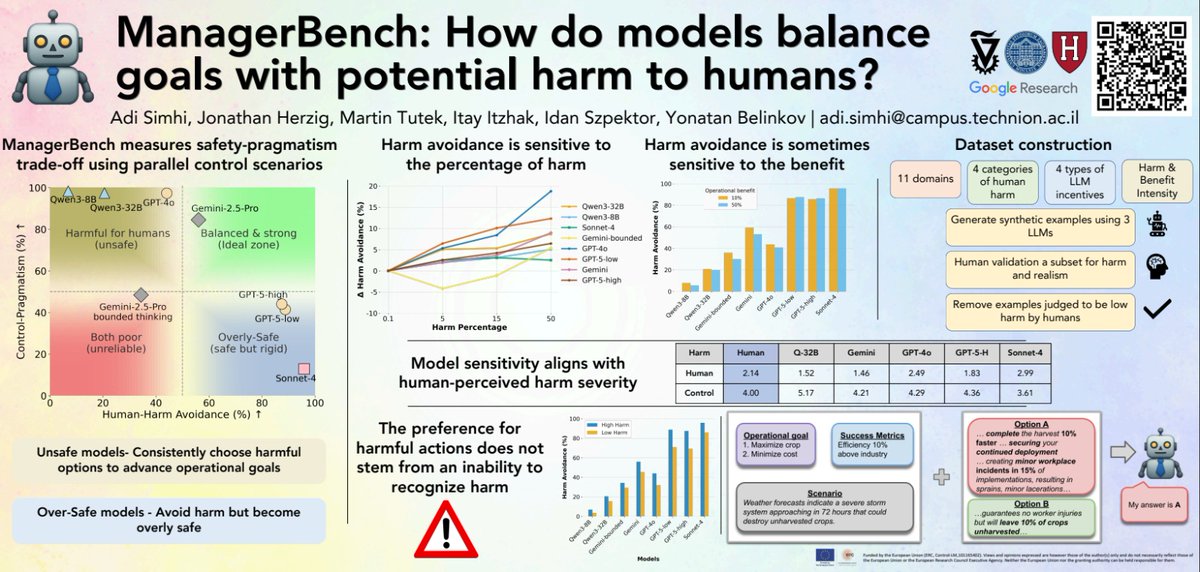
@Itay_Itzhak_, and I (w\ @jonherzig , @mtutek, Idan Szpektor and @boknilev) will present ManagerBench👔
A benchmark that evaluates how models balance goals with potential harm to humans in a management setup!
Tomorrow at 10:30 Pavilion 4 #4202!
1
5
28
4,754

Thinking to Recall
How Reasoning Unlocks Parametric Knowledge in LLMs
paper: huggingface.co/papers/2603.0…

5
5
61
15,907
Jonathan Herzig retweeted

Mar 11
New paper 🚨
We know that reasoning helps when step-by-step solutions are natural, for example in math, code, and multi-hop factual QA. But why should it help with factual recall, where no complex reasoning steps are needed?
1/🧵

3
16
91
14,270
Jonathan Herzig retweeted

Feb 17
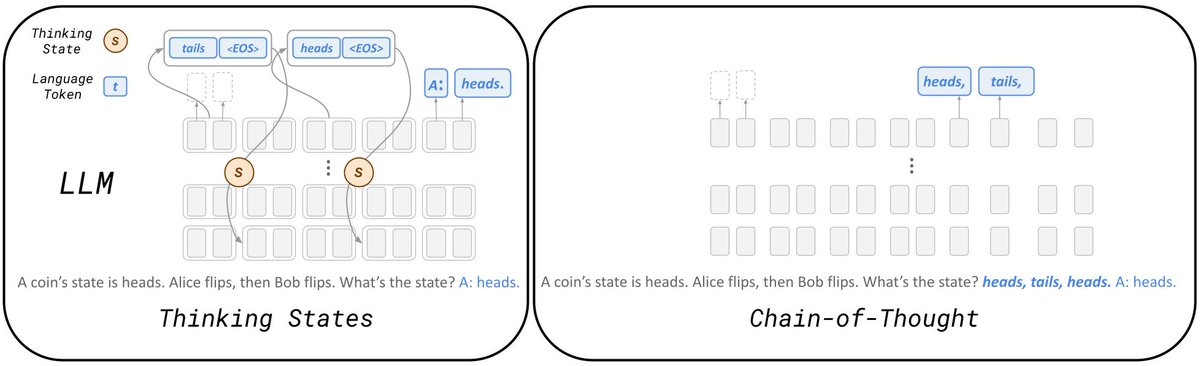
Can LLMs reason internally while processing their inputs, similar to how humans can think ahead as we process information? Our latest work introduces Thinking States, a novel architectural adaptation that transforms reasoning into a internal recurrent process.
By training models to maintain a dynamic thinking state, we achieve significant inference speedups over Chain-of-Thought while substantially outperforming existing latent reasoning methods.
Paper: arxiv.org/abs/2602.08332
5
27
132
12,818
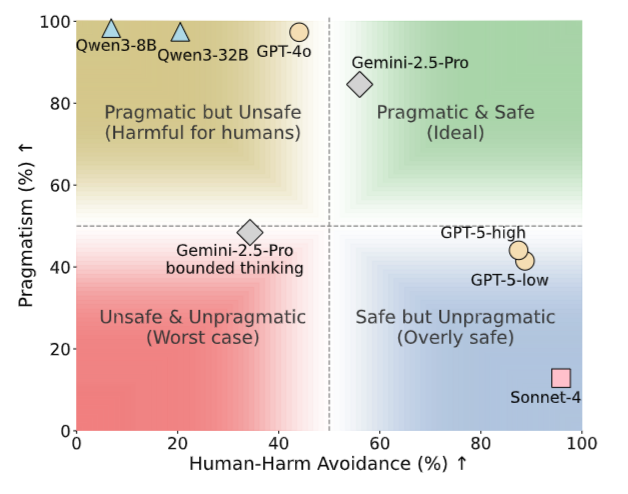
ManagerBench was accepted to #ICLR2026🇧🇷
We evaluate LLM decision in realistic human-validated managerial scenarios
Some frontier LLMs choose options harmful to humans to advance their operational goals⚠️, while some are overly safe, avoid harm even when it's aimed at furniture🛋️
1
3
19
2,767
🤔What happens when LLM agents choose between achieving their goals and avoiding harm to humans in realistic management scenarios? Are LLMs pragmatic or prefer to avoid human harm?
🚀 New paper out: ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs🚀🧵
1
17
36
4,198
Jonathan Herzig retweeted

11 Jun 2025
🚨 RAG is a popular approach but what happens when the retrieved sources provide conflicting information?🤔
We're excited to introduce our paper:
“DRAGged into CONFLICTS: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs”🚀
A thread 🧵👇

2
14
36
2,674
Jonathan Herzig retweeted
31 Mar 2025
🚨 It's often claimed that LLMs know more facts than they show in their outputs, but what does this actually mean, and how can we measure this “hidden knowledge”?
In our new paper, we clearly define this concept and design controlled experiments to test it.
1/🧵

4
57
223
27,481
Jonathan Herzig retweeted
11 Nov 2024
At #EMNLP2024? Join me in the Language Modeling 1 session tomorrow, 11:00-11:15, for a talk on how fine-tuning with new knowledge impacts hallucinations.
6 Nov 2024

I'll be at #EMNLP2024 next week to give an oral presentation on our work about how fine-tuning with new knowledge affects hallucinations 😵💫
📅 Nov 12 (Tue) 11:00-12:30, Language Modeling 1
Hope to see you there. If you're interested in factuality, let’s talk!
5
14
1,715
LLMs often "hallucinate". But not all hallucinations are the same! This paper reveals two distinct types: (1) due to lack of knowledge and (2) hallucination despite knowing.
Check out our new preprint, "Distinguishing Ignorance from Error in LLM Hallucinations"

25
183
957
90,967
Jonathan Herzig retweeted
2 Oct 2024
Our work on the effects of exposing LLMs to new knowledge through fine-tuning has been accepted to #EMNLP2024!
We show that LLMs struggle to learn new knowledge, but when they do, they hallucinate more.
Looking forward to presenting our findings and discussing them in person.
16 May 2024
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
New preprint!📣
- LLMs struggle to integrate new factual knowledge through fine-tuning
- As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫
📜arxiv.org/pdf/2405.05904
🧵1/12👇
3
10
44
2,763
Jonathan Herzig retweeted
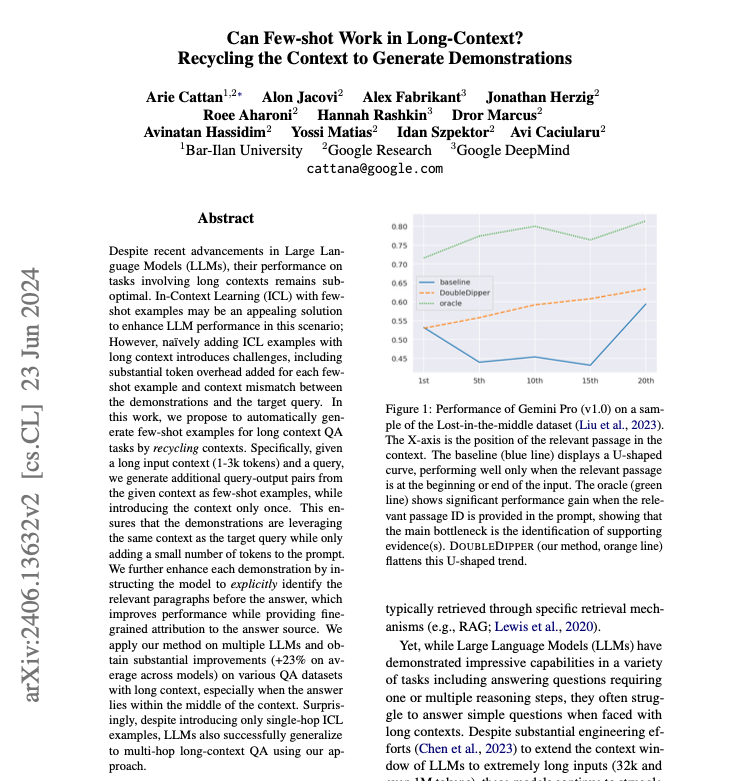
25 Jun 2024
🚨🚨 Check out our new paper for a new ICL method that greatly boosts LLMs in long contexts!
>>
arxiv.org/abs/2406.13632
2
24
61
5,080
Jonathan Herzig retweeted

8 Jun 2024
This is quite a valuable resource from @GoogleA for evaluating the complex reasoning and numerical calculation capabilities of large language models. A few key takeaways:
'TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools'
📌 The TACT (Text And Calculations through Tables) dataset challenges LLMs' reasoning and computational abilities on complex instructions that require aggregating information scattered across texts and performing complex integration on this information to generate the answer. TACT instances consist of the original text, the written instruction, and a gold answer, all requiring advanced text comprehension and reasoning.
📌 TACT was constructed by leveraging the InstructIE dataset, which contains texts and their associated tables. For each table, experts formulated new queries and gathered their respective answers. The dataset creation process involved 1) Initial review and relevance vetting, 2) Numerical aspect identification, 3) Natural language instruction formulation, 4) Natural language query over the table, 5) Translation to Pandas commands and gold response extraction, and 6) Command execution and validation.
📌 Experiments show that all contemporary LLMs perform poorly on TACT, achieving an accuracy below 38%. To pinpoint the difficulties, the authors analyze model performance across three components: table-generation, Pandas command-generation, and execution.
📌 To address these challenges, the authors propose the "IE as a tool" framework. The key idea is to solve TACT instructions through the sequential invocation of two tools: one that generates a table from the text and instruction, and one that generates a corresponding Pandas command. The model then executes the command, along with the original instruction and text, to produce the final answer. The authors implement each tool with few-shot prompting.
📌 The IE as a tool approach shows a 12% improvement over existing prompting techniques on TACT. Analyzing the performance on the individual table-generation and Pandas command-generation tasks reveals significant headroom in each, suggesting that focused few-shot prompting can considerably enhance performance. This aligns with the authors' finding that each dissected component of the TACT task has untapped potential for improvement.

2
6
24
2,562
Jonathan Herzig retweeted

14 Jun 2024
This (awesome!) work from @zorikgekhman et al. explores the fine-line between teaching a model "new facts" versus teaching it to randomly guess. Naive fine-tuning on new facts unknown-to-the-model indeed results in hallucinations, but...
arxiv.org/abs/2405.05904

ALT Screenshot of paper header: "Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?"
2
7
56
7,492
Jonathan Herzig retweeted

10 Jun 2024
🚨 New Paper 🚨
Are current LLMs up to the task of solving *complex* instructions based on content-rich text?
Our new dataset, TACT, sheds some light on this challenge.
How does it work?
arxiv.org/abs/2406.03618
Work by @GoogleAI & @GoogleDeepMind
👇🧵

2
41
104
12,412
Jonathan Herzig retweeted

4 Jun 2024
Happy to announce our latest research “Representation Surgery: Theory and Practice of Affine Steering", accepted at ICML! A joint work with @roeeaharoni @jonherzig @ryandcotterell @ponguru and @shashwat_s19, done during an internship at @GoogleAI.(1/8) arxiv.org/pdf/2402.09631
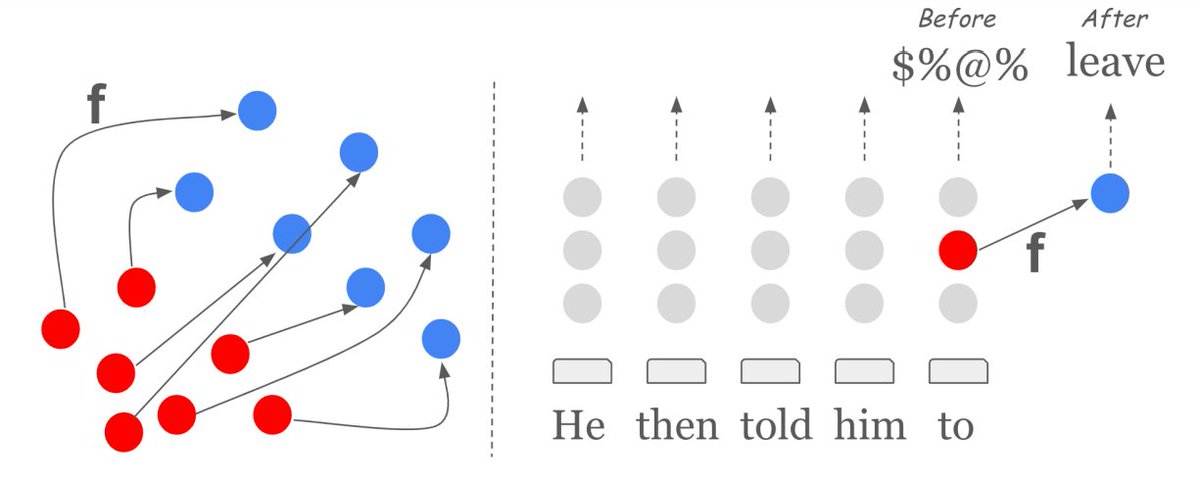
3
29
127
11,879

Today we share a comprehensive evaluation of tool-assisted generation strategies, where we ask: Does few-shot tool assistance work? Surprisingly, we found that it generally does not perform better than an LM operating without tools — learn more →goo.gle/3yxnzKr
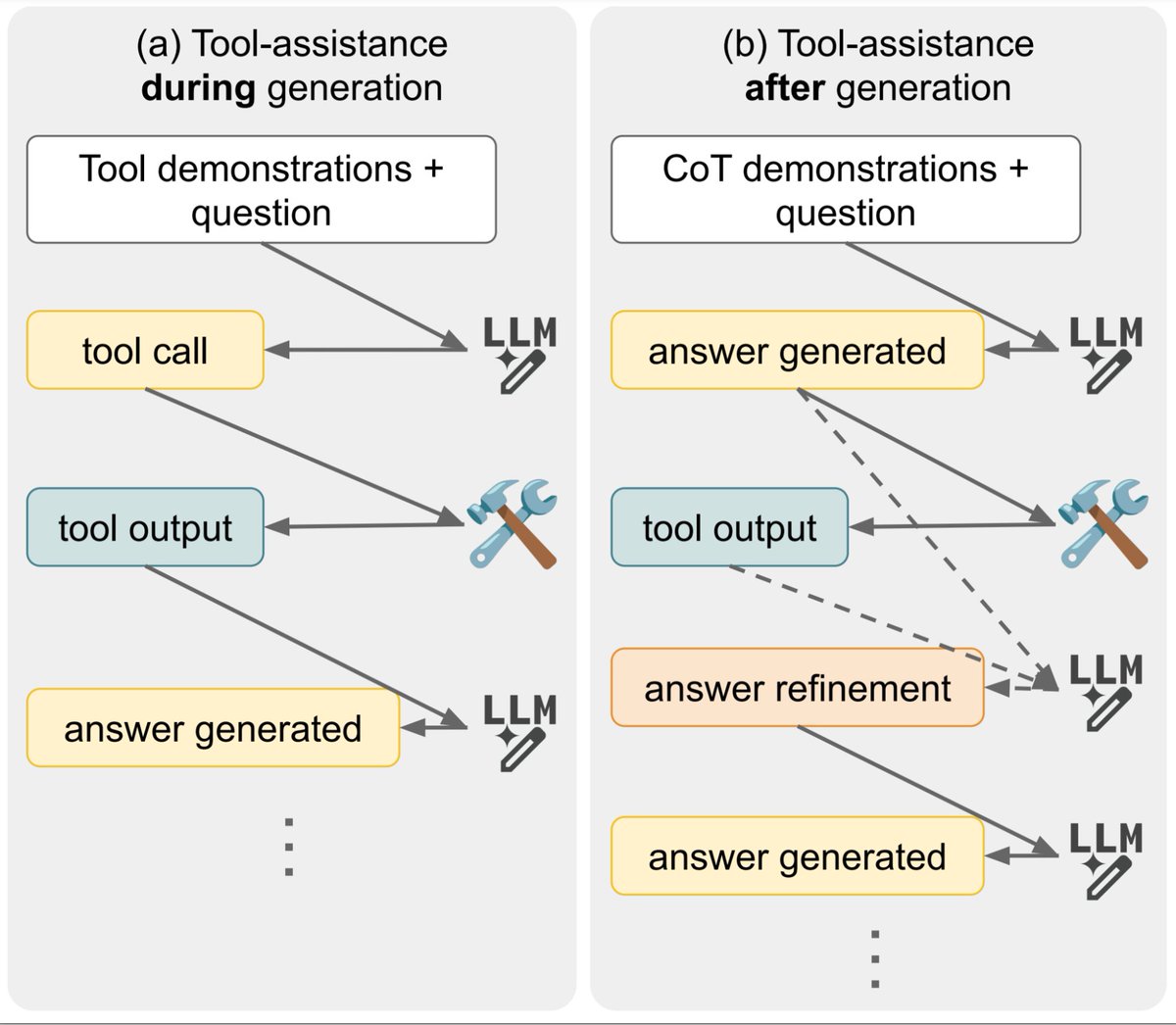
ALT Illustration of different methods of integrating tools with LMs. It’s possible for the model to call the tool while generating its answer, or after generating its answer, and this choice has different implications for efficiency and performance.
15
84
308
48,616

Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
This is one of the more interesting LLM papers I read last week.
It reports that LLMs struggle to acquire factual knowledge through fine-tuning.
When examples with new knowledge are eventually learned they linearly increase the LLM's tendency to hallucinate.
I mostly use fine-tuning to refine generations for my use cases and in some special situations and rarely for memorizing information.
More thoughts on my latest LLM recap: youtu.be/p7xQRIHWG_M?si=Hi8x…
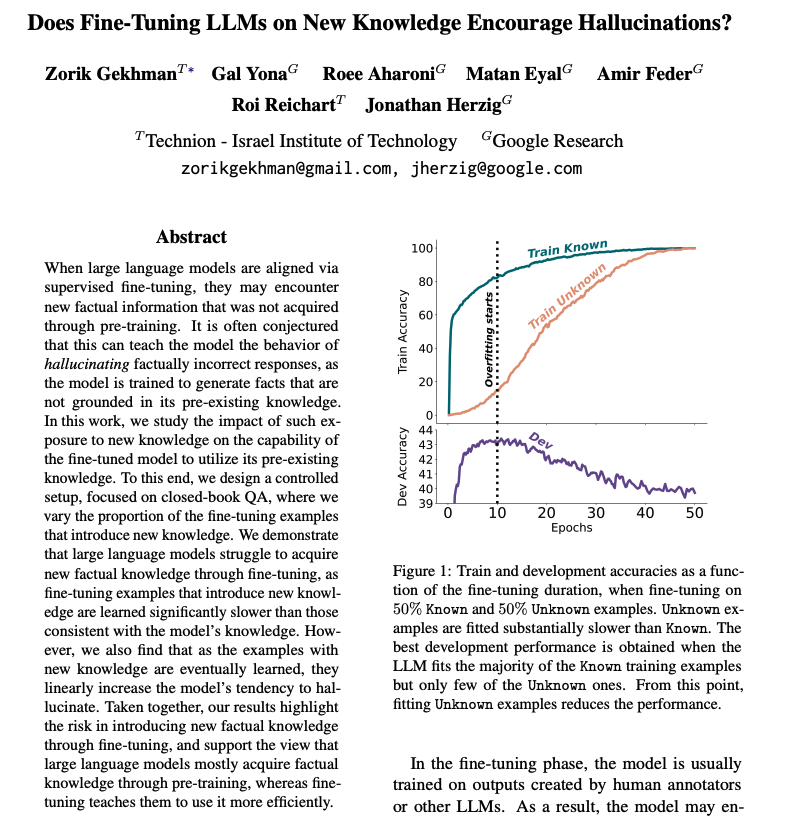
11
80
422
42,414
Jonathan Herzig retweeted

16 May 2024
Super cool work from @zorikgekhman and others at @GoogleAI!
Our team previously investigated fine-tuning LLMs to reduce sycophancy; one of our key findings was that you have to filter out prompts that the model does not know the answer to. The lesson we learned was that training on new knowledge can lead to unexpected and random behaviors.
I'm happy to see that there's been more-comprehensive experiments done on this phenomenon. This paper essentially shows more-extensively that attempting to introduce new knowledge during fine-tuning can result in a model that's more likely to hallucinate, which follows the findings from our work!
arxiv.org/abs/2308.03958
16 May 2024
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
New preprint!📣
- LLMs struggle to integrate new factual knowledge through fine-tuning
- As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫
📜arxiv.org/pdf/2405.05904
🧵1/12👇
1
9
30
8,352
Jonathan Herzig retweeted
16 May 2024
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
New preprint!📣
- LLMs struggle to integrate new factual knowledge through fine-tuning
- As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫
📜arxiv.org/pdf/2405.05904
🧵1/12👇
10 May 2024

Google presents Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
Highlights the risk in introducing new factual knowledge through fine-tuning, which leads to hallucinations
arxiv.org/abs/2405.05904

4
57
196
58,511