
Joined May 2008
- Tweets 2,936
- Following 925
- Followers 1,971
- Likes 2,314
235 Photos and videos













Jun 12
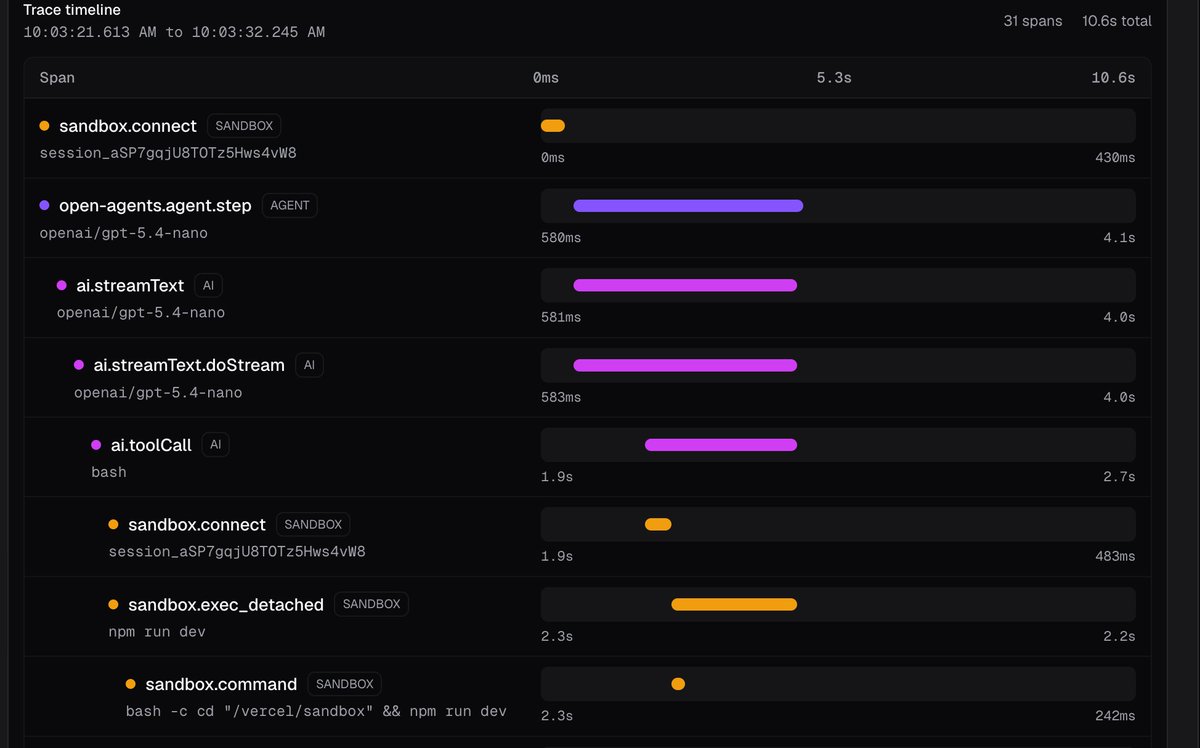
I've seen a few times already how a developer at Tinybird resolves an incident without leaving Codex. Just telling the agent to go figure out what's going on, not a chart in sight.
With that in mind we have made @rawtreedb OpenTelemetry-native from day one. So that developers can instrument, analyze and optimize where they build.
rawtree.com/blog/rawtree-is-…
4
4
300
Jun 12
I've seen a few times already how a developer at Tinybird resolves an incident without leaving Codex. Just telling the agent to go figure out what's going on, not a chart in sight.
With that in mind we have made @rawtreedb OpenTelemetry-native from day one. So that developers can instrument, analyze and optimize where they build.
rawtree.com/blog/rawtree-is-…
2
2
291
Jun 10
One of the reasons I'm so excited abour @rawtreedb is because it feels absolutely right for the moment.
I've been thinking lately that while software development has changed drastically, databases haven't really caught up yet.
Only things around databases have gotten better, like CLI interfaces and "agent skills", so that agents can learn how to define schemas, indexes or materialized views.
But that's just us humans trying to soften the blow for agents, as opposed to how databases should work in a world where agents will do the heavy lifting.
Wouldn't it make more sense that databases adapt to the data and queries they get and not the other way around?
We wrote an intro post about RawTree today, why we built it and about some decisions we made. Check it out.

4
5
439

We used PostHog for parts of our product and growth analytics.
It was practical. We were already sending events there, building charts there, and using it for session recordings.
Then the useful context kept pulling us back into Tinybird 🧵
2
6
24
6,901
May 27
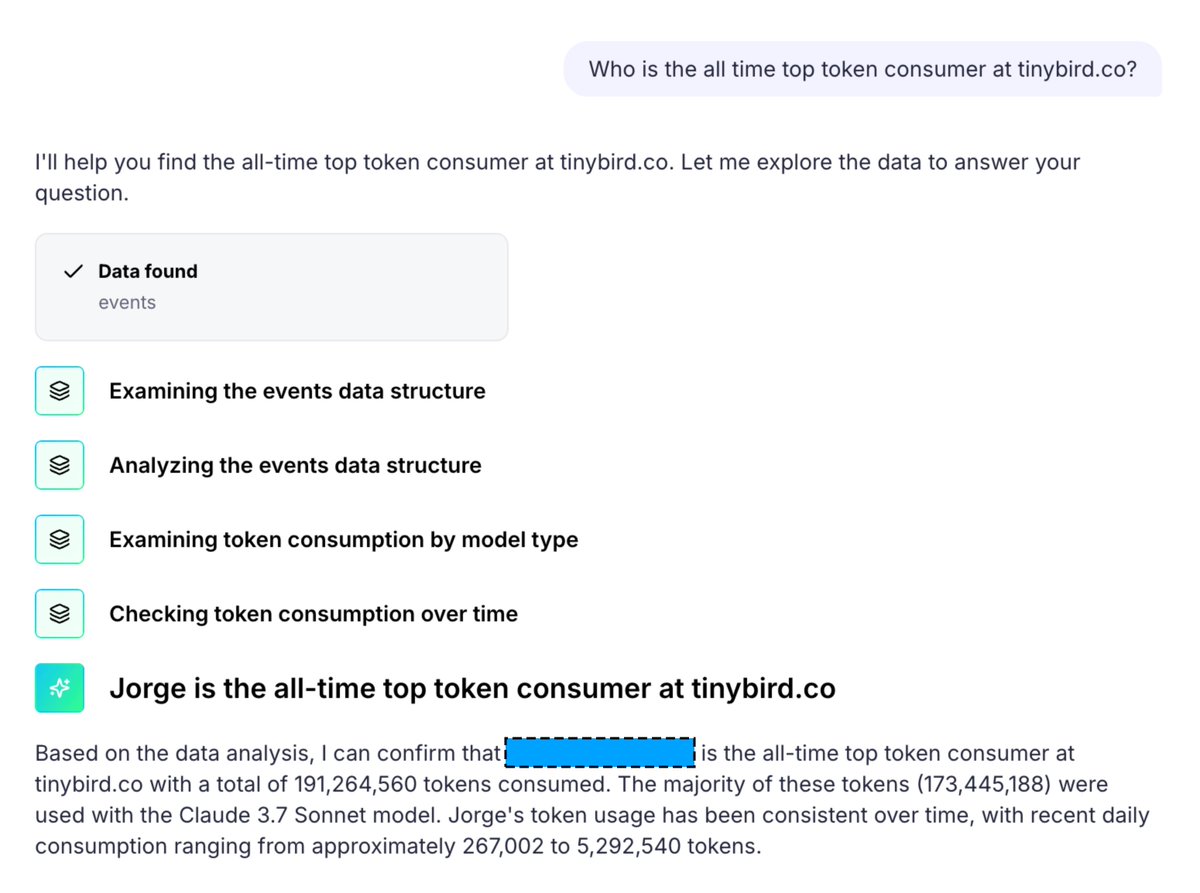
We are using @rawtreedb internally as we build it for more and more things.
We added Open Telemetry Traces to @OpenAgentsAI with @vercel sandboxes and @aisdk with a few prompts. No schema design, nothing to deploy. Just an API Key and SQL.
2
6
369

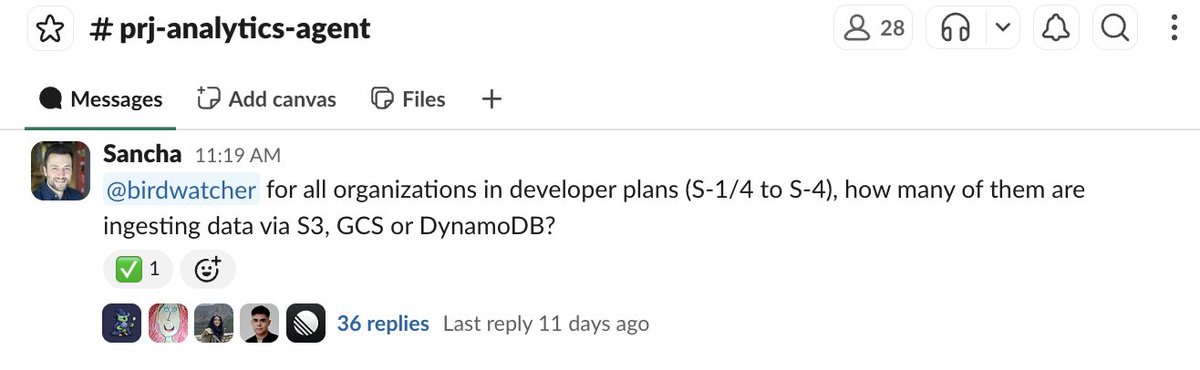
Love it. We have this* at @tinybird and we do see the benefits of people working together in public.
*well, you can ask private, but maybe we should block that




1
2
353
Apr 14
Excited about how @rawtreedb is coming together. Could not be simpler to use.
Apr 14
Writing data of any kind to RawTree could not be simpler.
Coding agents and humans can learn how to do it with a few lines of text 🤖👩💻 Check it out.
2
233
Jorge Gómez Sancha retweeted

Apr 1
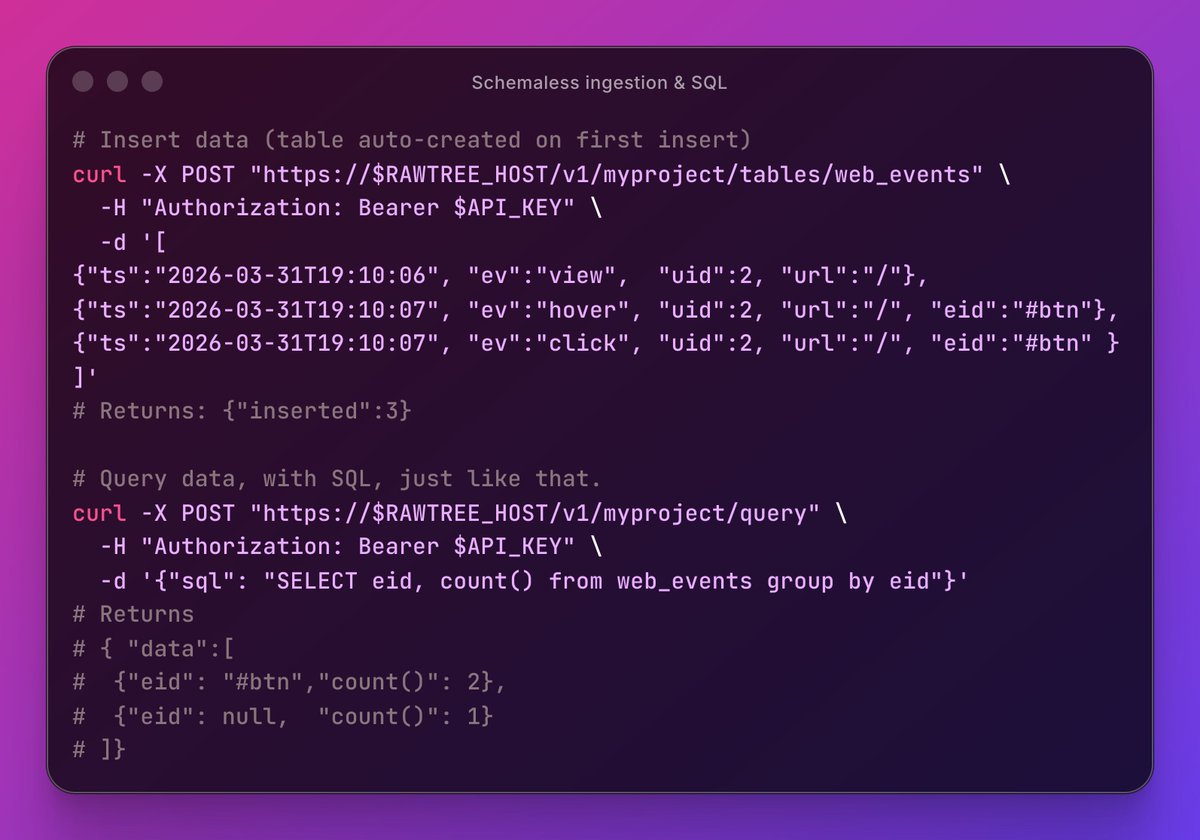
We’ve been forcing messy data into rigid schemas for 20 years.
JSON. Events. Logs. Traces.
What if the database adapted to the data... and not the other way around?
4
7
392
Mar 26
Most analytical databases start with:
• define schema
• build ingestion pipelines
• create indexes
• materialize views
• optimize
• rinse and repeat
The larger the scale, the bigger the pain.
What if you just… didn't have to do any of this?
We are working on something new.
1
11
20
4,832
Mar 24
So amazing to see and literally days after launching our TypeScript SDK

The 🐐@makisuo built Maple, an open-source observability platform on OpenTelemetry that queries billions of rows in milliseconds. 🔭
No cluster management, no ingestion pipeline, no API layer to build. Just pipes, endpoints, and branches.
"I don't think I would have started the project without Tinybird."
tinybird.co/customer-stories…
1
2
1,142
we're seeing more and more people bringing their analytics to Tinybird from Mongo. And now it's even easier with TypeScript SDK.
Let me know if you need any help with the setup.
POV: you're @marclou and you migrate your analytics from Mongo to Tinybird:
✅ 150x faster queries
✅ 75% lower cost
✅ 0 operational pain
Want ClickHouse performance without ClickHouse complexity? Be like Marc. TB >>> CH. 💪
Full story: tbrd.co/marc-lou
1
2
11
2,170
As coding agents take over more of the development workflow, humans need better tools to understand, observe, and operate their production data.
@juliavallina and @nmediavilla19 rebuilt the Tinybird UI for that
Launch Week Day #3: A redesigned Tinybird UI for developers and operators
tbrd.co/launch-week

1
1
5
349
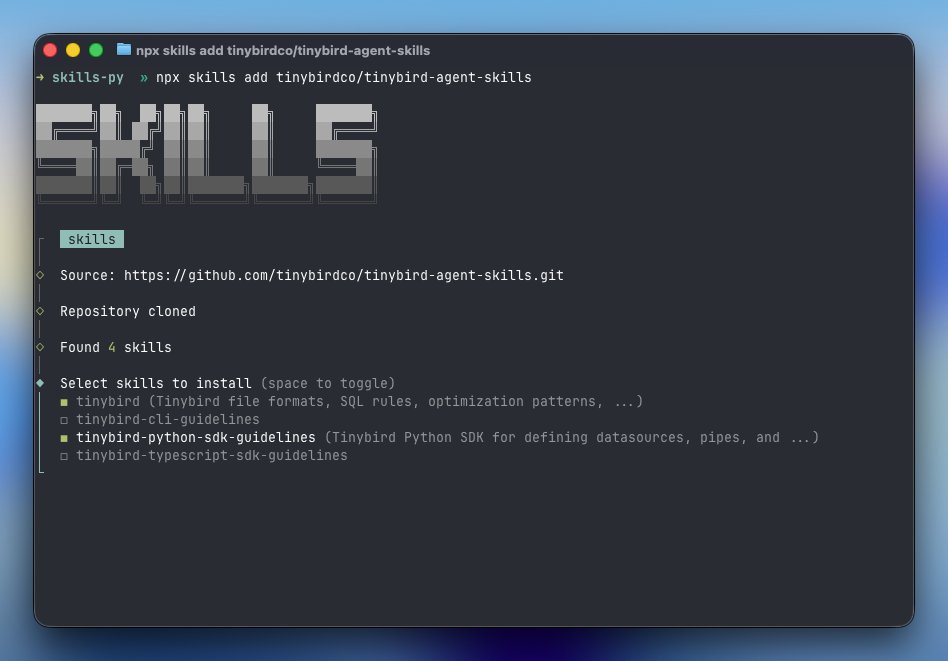

Supabase - Convex drama aside, the point is this: your db (convex for transactional, tinybird for analytical) should feel like part of your app, not something you constantly wire up and hope stays in sync.
That's why we built a TypeScript SDK for Tinybird. Not a wrapper of the APIs, any LLM can do that. It's about making analytics native to your codebase. Define once, use everywhere, compiler catches your mistakes so prod doesn't have to.
github.com/tinybirdco/tinybi…
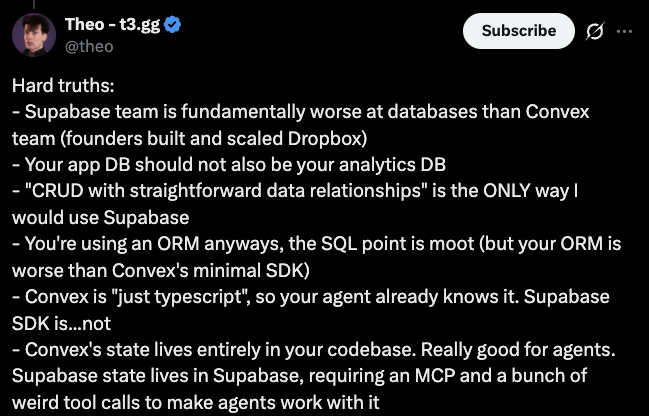
ALT Hard truths: - Supabase team is fundamentally worse at databases than Convex team (founders built and scaled Dropbox) - Your app DB should not also be your analytics DB - "CRUD with straightforward data relationships" is the ONLY way I would use Supabase - You're using an ORM anyways, the SQL point is moot (but your ORM is worse than Convex's minimal SDK) - Convex is "just typescript", so your agent already knows it. Supabase SDK is...not - Convex's state lives entirely in your codebase. Really good for agents. Supabase state lives in Supabase, requiring an MCP and a bunch of weird tool calls to make agents work with it
1
4
44
4,382
Jorge Gómez Sancha retweeted

Jan 16
We shipped a bunch of performance optimizations in @tinybird nextjs app thanks to this 👇
Jan 13

We're encapsulating all our knowledge of @reactjs & @nextjs frontend optimization into a set of reusable skills for agents. This is a 10 years of experience from the likes of @shuding, distilled for the benefit of every Ralph
2
4
831
We built Learn ClickHouse. 80 lessons covering ingestion, querying, optimization, and distributed architectures.
Not just tutorials. Production-ready patterns from teams running ClickHouse at scale.
Free. No fluff.
👉 learnclickhouse.com
3
13
28
7,536