
43 Photos and videos












Joseph Chee Chang retweeted

Excited to share MyScholarQA - a personalized deep research tool that learns from your papers and lets you customize reports! 🧑🔬🖌️
Our #ACL2026 paper built and evaluated it, showing simulated users (LLMs) couldn't mimic what real users wanted 🙅
Spicy results a live demo 👇🧵
1
33
92
10,182
Joseph Chee Chang retweeted

Mar 13
Are you a researcher in CS or a CS-adjacent field curious about how an AI agent can help you with your research project? Want to try a new tool for your research support in a paid user study ($100, 2 hr)? Limited spot numbers. See details and sign up here: forms.gle/JzLtkAhe7TtvuiwQ8
2
22
97
9,727
Joseph Chee Chang retweeted

Mar 10
Cocoa is accepted to #chi2026 as a 🏆best paper (top 1% of submissions)! See you in Barcelona 🎉🇪🇸
16 Jan 2025

🤔Giving complex tasks to AI agents is easy—getting them to do exactly what you want isn’t. How can human-AI collaboration give us more reliable & steerable agents?
🍫Introducing Cocoa, our new interaction paradigm to balance human & AI agency in complex human-AI workflows. 🧵
4
8
67
8,065



Feb 11
Submission deadline ending soon - Come hangout with us at CHI : )
19 Dec 2025

What is future of reading? 📗
Announcing the 1st Science & Technology of Augmented Reading (STAR) workshop at #CHI2026!
We want your takes on: 🤖 AI & Agents for reading 👁️ Visual Interactions 🗺️ Domains (Code, Law, Ed, etc.)
👇 Submit a 2-4 pg paper: chi-star-workshop.github.io/

2
203
Joseph Chee Chang retweeted

19 Dec 2025
What is future of reading? 📗
Announcing the 1st Science & Technology of Augmented Reading (STAR) workshop at #CHI2026!
We want your takes on: 🤖 AI & Agents for reading 👁️ Visual Interactions 🗺️ Domains (Code, Law, Ed, etc.)
👇 Submit a 2-4 pg paper: chi-star-workshop.github.io/
5
13
1,941
Joseph Chee Chang retweeted
Feb 3
Deadline for submission in just under 10 days! Reach out if you have any questions.
19 Dec 2025
What is future of reading? 📗
Announcing the 1st Science & Technology of Augmented Reading (STAR) workshop at #CHI2026!
We want your takes on: 🤖 AI & Agents for reading 👁️ Visual Interactions 🗺️ Domains (Code, Law, Ed, etc.)
👇 Submit a 2-4 pg paper: chi-star-workshop.github.io/
1
2
8
540
Introducing Theorizer: Turning thousands of papers into scientific laws 📚➡️📜
Most automated discovery systems focus on experimentation. Theorizer tackles the other half of science: theory building—compressing scattered findings into structured, testable claims. 🧵
14
90
595
55,562

Joseph Chee Chang retweeted

11 Dec 2025
Ever want to ask questions about a paper, including its figures & tables? 📊📈 Want smoother interactions w/papers on desktop & mobile?
Try Paper Figure QA, a new tool from @allen_ai that answers with the original figures, tables, and excerpts from papers: paperfigureqa.allen.ai
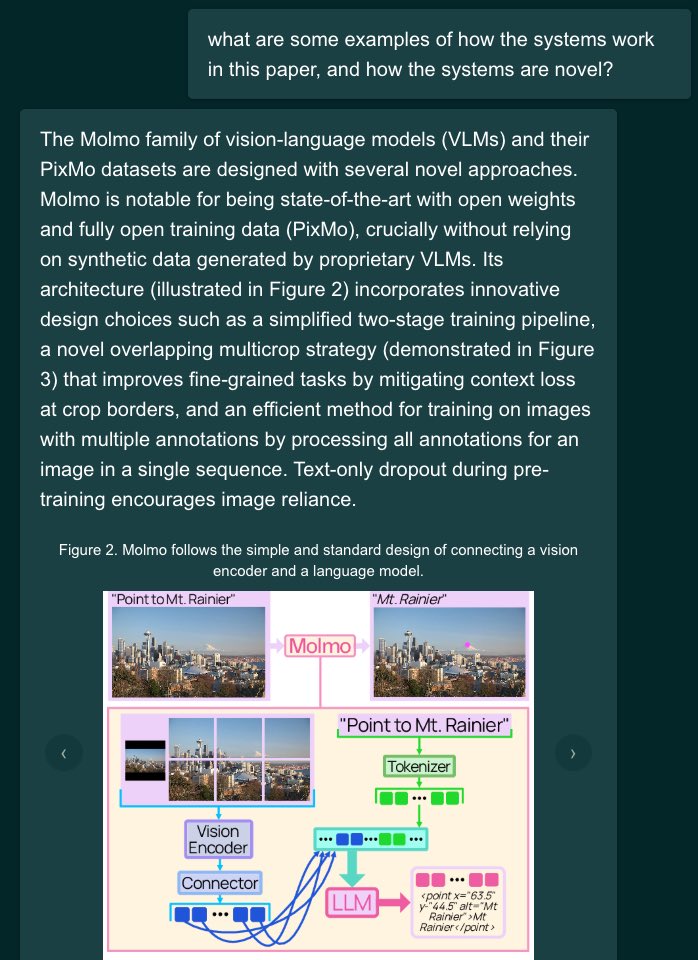
ALT A screenshot of a user asking about examples of how a system works in a paper, and the system responding with details about the system along with a relevant figure and caption from the paper.
1
3
5
726
12 Nov 2025
Ai2 is hiring Summer interns to work on:
- human-AI interaction and intelligent UIs
- research support systems e.g., lit reviews, ideation
- and more!
We encourage publishing and public deployments. Apply with link below before Dec 15 for the first reviews cycle : )
#chi2026
8
27
261
18,329
12 Nov 2025
Apply here: job-boards.greenhouse.io/the…
DM also open if you have general questions or are interested in working on a topic with me specifically : )
7
1,174
Joseph Chee Chang retweeted

7 Nov 2025
Last year I worked at @Adobe @AdobeResearch and @allen_ai, exploring how we can help users read, organize and understand long documents. This piece covers what we learned on modelling user intent and combining LLMs with principled tools when building complex pipelines for it!
7 Nov 2025

CDS PhD alum Vishakh Padmakumar (@vishakh_pk), now at @Stanford, tackled the hard part of summarization — deciding what matters.
At @Adobe, he built diversity-aware summarizers; at AI2 (@allen_ai), intent-based tools for literature review tables.
nyudatascience.medium.com/su…
2
6
51
10,418
Joseph Chee Chang retweeted

15 Aug 2025
Producing reasoning texts boosts the capabilities of AI models, but do we humans correctly understand these texts? Our latest research suggests that we do not.
This highlights a new angle on the "Are they transparent?" debate: they might be, but we misinterpret them. 🧵

8
29
140
28,824
Joseph Chee Chang retweeted

30 Jul 2025
People at #ACL2025, come drop by our poster today & chat with me about how context matters for reliable language model evaluations!
Jul 30, 11:00-12:30 at Hall 4X, board 424.
13 Nov 2024

Excited to share ✨ Contextualized Evaluations ✨!
Benchmarks like Chatbot Arena contain underspecified queries, which can lead to arbitrary eval judgments. What happens if we provide evaluators with context (e.g who's the user, what's their intent) when judging LM outputs? 🧵↓

1
7
22
1,371

Joseph Chee Chang retweeted

28 Jul 2025
Thank you all for joining us!! The Q&A were all very insightful 😀😀 Here's the link to the slides: bit.ly/acl25-hai-team
1
11
1,084
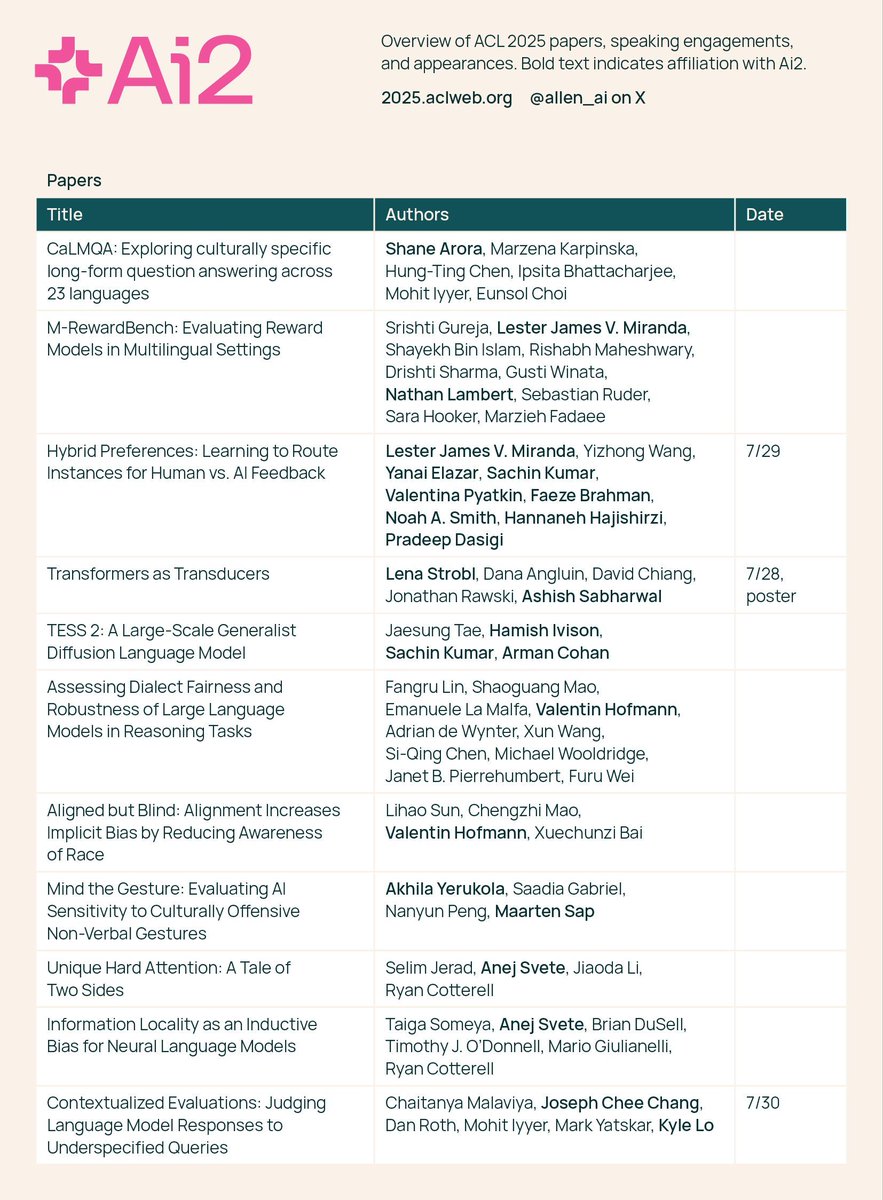
Joseph Chee Chang retweeted

27 Jul 2025
In Vienna for #ACL2025NLP this week!
@josephcc, @aps6992 and I will present the Ai2 ScholarQA scientific QA system on Wed. I’ll also be at @sdpworkshop on Thurs!
Hit me up if you’d like to chat about agents for science and post-training, or explore cafes in Vienna 🥐
6
3
28
1,675