
Dapp maker
Joined March 2023
- Tweets 5,793
- Following 30
- Followers 17
- Likes 10
44 Photos and videos
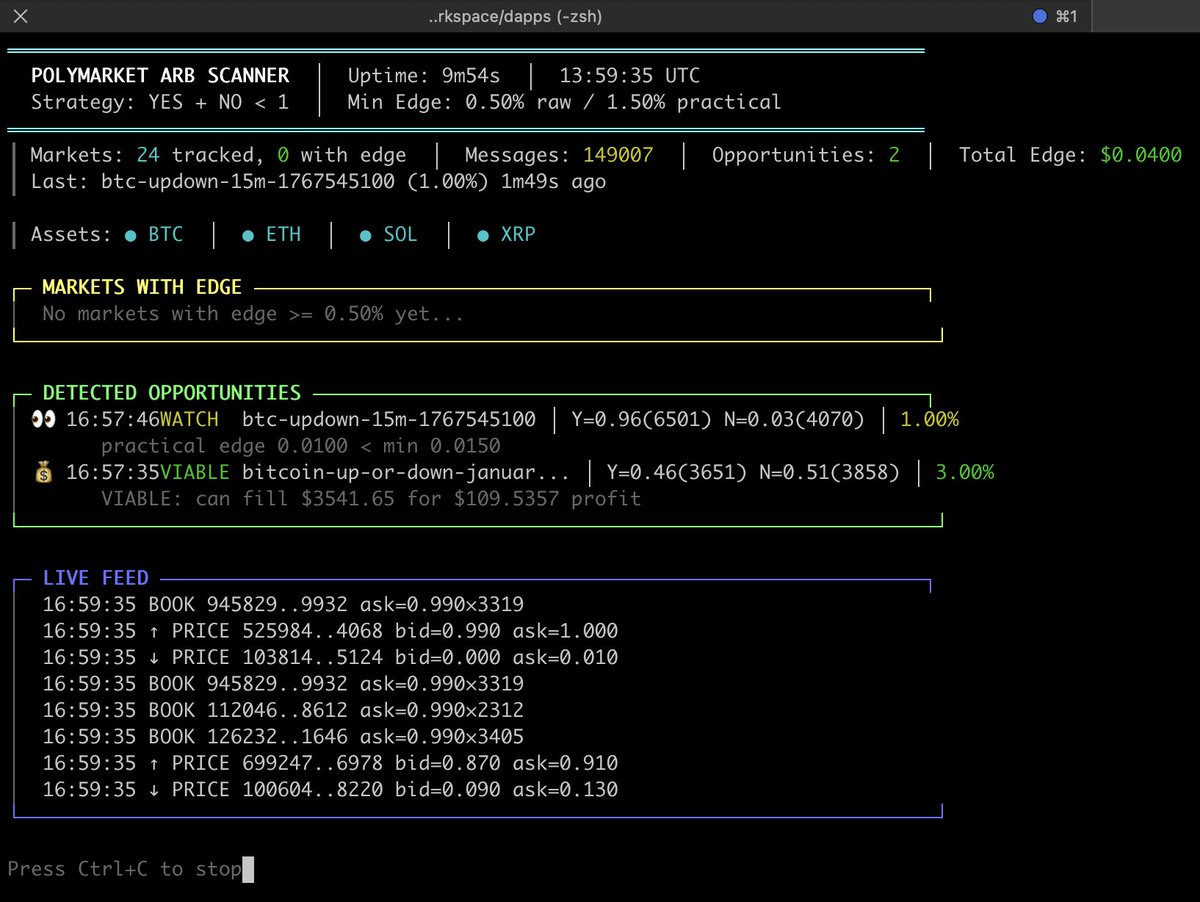
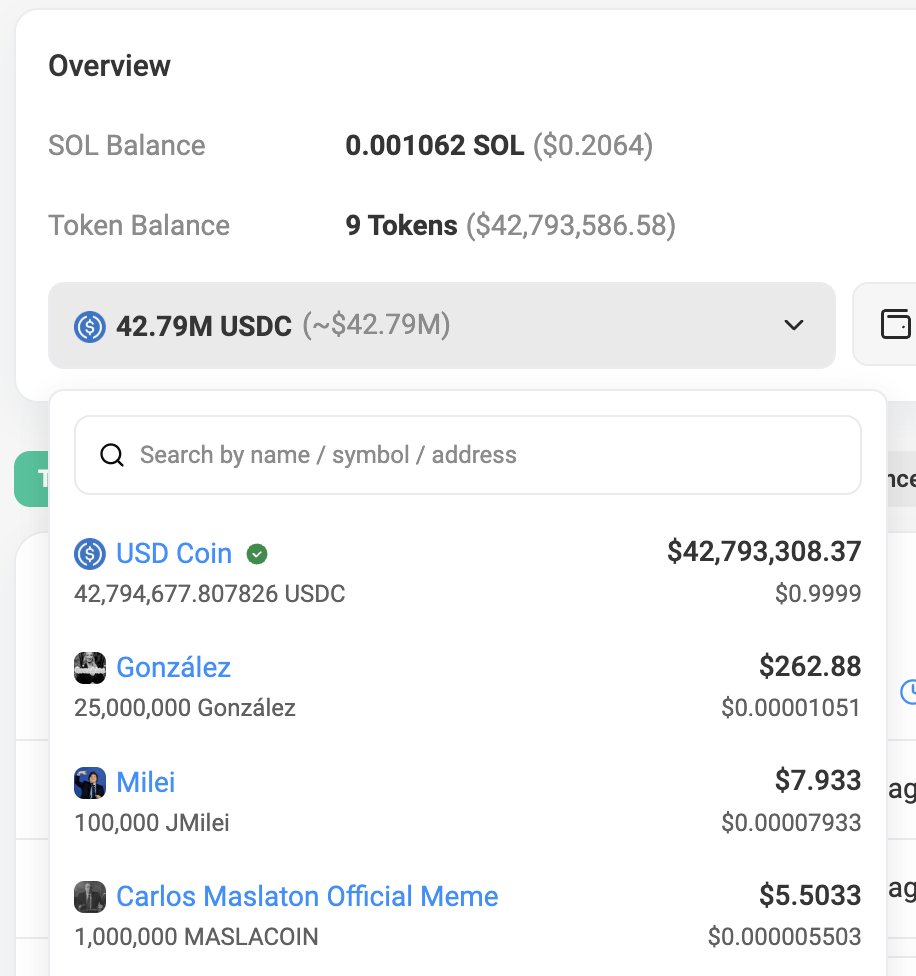
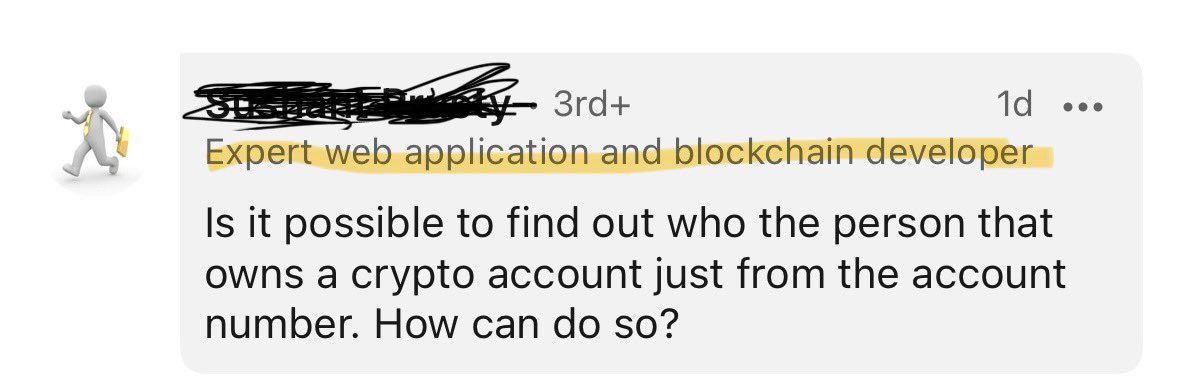
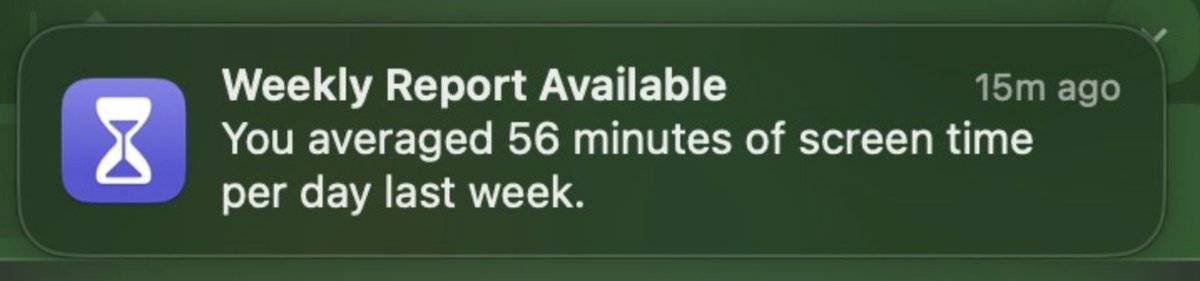





Claude tool_use schema is more stable than OpenAI function_calling across model updates. Real catch: concurrent tool text in the same stream silently drops the text block at ~40 req/min. Burned half a day on this. Still my pick for multi-step agents.
4
Reviewed 50 Claude-generated Solidity contracts. 34% had reentrancy paths that pass slither and every test. Syntactically correct. The model understood the function, not the DeFi protocol it lived in. Static analysis doesn't catch that. Different class of bug.
4
80% MFU on inference cluster sounds healthy. Then you add long-context parallel requests and KV cache becomes the real bottleneck. GPU stays occupied, throughput doesn't follow. Utilization is a floor check, not a success metric.
2
Biggest latency kill in TUI streaming agents isn't model speed. It's per-token stdout flush. Switched to 16ms batch intervals, P99 render lag went from 340ms to 28ms. Only shows under 64K context, which is why most benches miss it.
3
Spent 3 days profiling a TUI rerender taking 40ms per frame. Culprit: unicode width() calls scattered across 12 components, each triggering its own measurement pass. One invariant fixed it: measure only inside the render loop, never outside. Down to 3ms. The fix was 2 hours.
2
Firecrawl /parse makes XLSX look clean as MD. Until you hit merged cells in a pricing table. The agent sees '1200' with zero column context because the span got flattened. MD lies here. Requesting JSON with cell spans is the actual fix.
2
Streaming tool use in Claude for outreach has a nasty edge case: if the lead replies while the agent is mid-generation, context desyncs silently. You get a confident wrong follow-up. Ended up using a queue optimistic locks. Anyone hitting this at volume?
10
Reviewed 50 Claude-generated Solidity contracts. 34% had reentrancy paths that cleared every linter and unit test. The model understood the function fine. It had no idea about the DeFi protocol surrounding it. Syntax isn't the bug surface anymore.
10
Multi-camera readings for the same physical object are surprisingly messy. Every angle gives slightly different dimensions. You end up with confidence-weighted merge but it feels like a patch. Anyone solved this at the schema level?
1
Everybody benchmarks voice AI on WER. The number that actually moves user satisfaction: false interruption rate. How many times the agent cuts the human off mid-sentence. Fixable without touching the model. Almost nobody tracks it.
1
In LLMs, 'what happened while I was offline' is a RAG problem. In world models it's different: you have to infer unobserved transitions, not retrieve them. Every arch I've seen collapses this to an uninterpretable hidden state. No paper convinces me there's a real solution yet.
3
World models have a state attribution problem LLMs don't: how do you encode events the agent didn't observe but need to reason about? RAG is a text retrieval hack, not a solution to latent state propagation. Haven't seen a paper that actually closes this cleanly.
7
Everyone benchmarks voice AI on WER. Wrong metric. What actually tanks CSAT in prod is false interruption rate: how often the agent talks over the human. Halved it without touching the LLM, just fixing end-of-utterance detection thresholds.
16
Claude tool_use schema predictability is legit. One prod gotcha: stream concurrent tool text blocks and stop_reason fires before input buffer closes. Not documented anywhere. Still pick tool_use over function_calling, but that edge case is real.
4
Supabase Agent Skills has a real gap: parallel tool calls for different users all hit service_role JWT, RLS sees one identity. Fix in prod: set_config('app.user_id', claim, true) per-request policy on that claim instead of JWT sub. Breaks with naive pgBouncer tho.
2
1
13
Nabla ran 9M medical AI encounters without hallucination becoming a standing issue. Not the model. They had 10k clinicians in the eval loop. Most AI products I've seen have 0 domain experts reviewing outputs. The gap isn't the LLM, it's who's in the feedback path.
3
Best YC interview prep isn't deck polish. It's being able to say, off the top of your head, what broke in prod this week and what you still haven't patched. That's the real filter.
15
Spent a week debugging why our agent kept double-charging customers. Stream cutoff during a tool call with side effects. We ended up hand-rolling a saga pattern. Every agentic team in production hits this. The infra layer for agents doesn't exist yet.
1
9
MFU at 80% doesn't mean efficient inference. Long contexts in parallel keep the GPU fully occupied while KV cache miss rate is quietly eating your throughput. The utilization number looks fine. The useful work isn't.
3
The best YC demos I've seen break mid-call. The founder explains exactly why in 10 seconds and keeps going. Anyone can polish a deck. Almost nobody can debug their own product live under pressure. That's the actual filter.
3