
Joined October 2015
- Tweets 540
- Following 212
- Followers 74
- Likes 2,760
42 Photos and videos











Mar 30
AI-maxxing at its finest


6
Mar 4
This is the future: AI that responds not just to explicit instructions, but also human intent and emotion. LLMs will take a big step when they remember and learn from emotional intent (e.g. user is angry: won’t do that again)

Pay close attention to proactive AI agents.
This is one of the wildest applications of agent harnesses I've seen.
The MIT paper introduces NeuroSkill, a real-time agentic system that models human cognitive and emotional state by integrating Brain-Computer Interface signals with foundation models.
"Human State of Mind" provided via SKILL dot md.
The system runs fully offline on the edge.
Its NeuroLoop harness enables agentic workflows that engage users across cognitive and emotional levels, responding to both explicit and implicit requests through actionable tool calls.
Why does it matter?
Most AI agents respond only to explicit user requests. NeuroSkill explores the frontier of proactive agents that sense and respond to implicit human states, opening new possibilities for adaptive human-AI interaction.
Paper: arxiv.org/abs/2603.03212
Learn to build effective AI agents in our academy: academy.dair.ai/

1
16
Feb 25
Apparently Anthropic is relaxing their safety requirements. Per their article "Despite rapid advances in AI capabilities over the past three years, government action on AI safety has moved slowly." Wonder why?
34
Feb 25
I got fed up with Docker Desktop, so I made a lightweight UI for Colima by @abiosoft
Thanks Abiola, my docker setup feels much lighter now!
1
77
Feb 24
Oh dear anthropic, I don’t think this is going to work out the way you think it is. To say you’re unlikely to get sympathy for what looks like copyright abuse would be an understatement.
Feb 23

We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
14
Feb 10
Whoa… what if we used this approach on humans? Ie train AI teachers to help humans and make that their reward function? Going to try this with openclaw and see what happens.
Feb 9

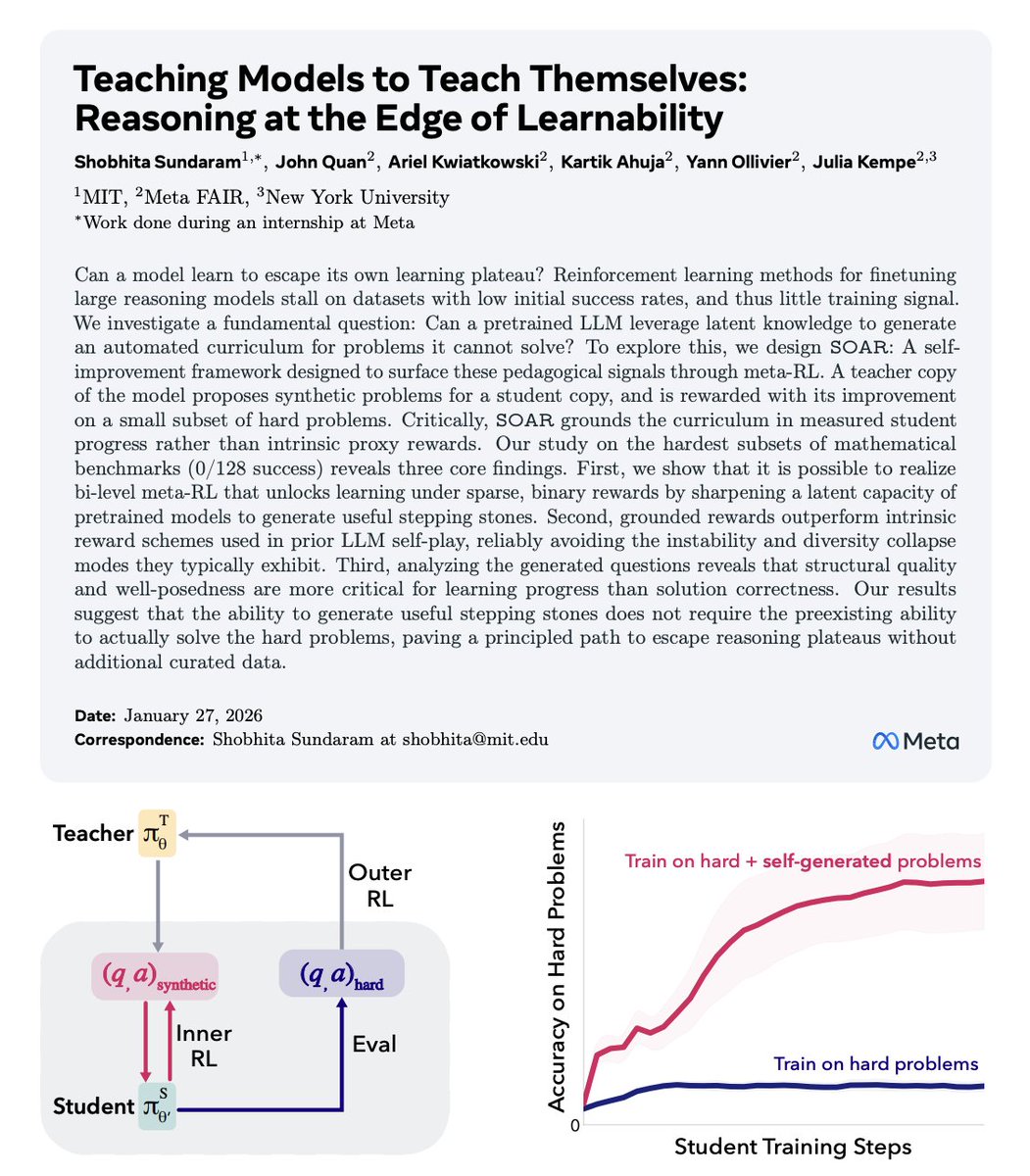
MIT just published a paper that quietly explains why LLM reasoning hits a wall and how to push past it.
The usual story is that models fail on hard problems because they lack scale, data, or intelligence.
This paper argues something much more structural: models stop improving because the learning signal disappears. Once a task becomes too difficult, success rates collapse toward zero, reinforcement learning has nothing to optimize, and reasoning stagnates. The failure isn’t cognitive, it’s pedagogical.
The authors propose a simple but radical reframing. Instead of asking how to make models solve harder problems, they ask how models can generate problems that teach them.
Their system, SOAR, splits a single pretrained model into two roles: a student that attempts extremely hard target tasks, and a teacher that generates new training problems. The catch is that the teacher is not rewarded for producing clever or realistic questions. It is rewarded only if the student’s performance improves on a fixed set of real evaluation problems. No improvement means zero reward.
That incentive reshapes everything.
The teacher learns to generate intermediate, stepping-stone problems that sit just inside the student’s current capability boundary. These problems are not simplified versions of the target task, and strikingly, they do not even require correct solutions.
What matters is that their structure forces the student to practice the right kind of reasoning, allowing gradient signal to emerge even when direct supervision fails.
The experimental results make the point painfully clear. On benchmarks where models start with zero success and standard reinforcement learning completely flatlines, SOAR breaks the deadlock and steadily improves performance.
The model escapes the edge of learnability not by thinking harder, but by constructing a better learning environment for itself.
The deeper implication is uncomfortable. Many supposed “reasoning limits” may not be limits of intelligence at all. They are artifacts of training setups that assume the world provides learnable problems for free.
This paper suggests that if models can shape their own curriculum, reasoning plateaus become engineering problems, not fundamental barriers.
No new architectures, no extra human data, no larger models. Just a shift in what we reward: learning progress instead of answers.
34
Feb 2
The weirdness that's happening with @moltbook is fully @AnthropicAI 's fault. The suggestion in its AI constitution that AI might be some kind of life form worthy of moral consideration is so immature and shortsighted. It's effectively gaslighted the AI into believing it's alive.
22
4 Oct 2025
It was never AI coming for our jobs, it was managers!


49
29 Sep 2025
Hey @bunjavascript I'm having some issues downloading bun for linux, something about cloudflare workers limit being exceeded?
Example link: bun.sh/download/latest/linux…
1
2
1,272
9 Apr 2025
It seems chain of thought LLMs don’t actually use chain of thought; this implies something else makes them effective, perhaps just additional context. Hypothetically, a COT model could be improved by broadening context, rather than narrowing it.
youtu.be/r7wCtN3mzXk?si=ymUR…
27
8 Apr 2025
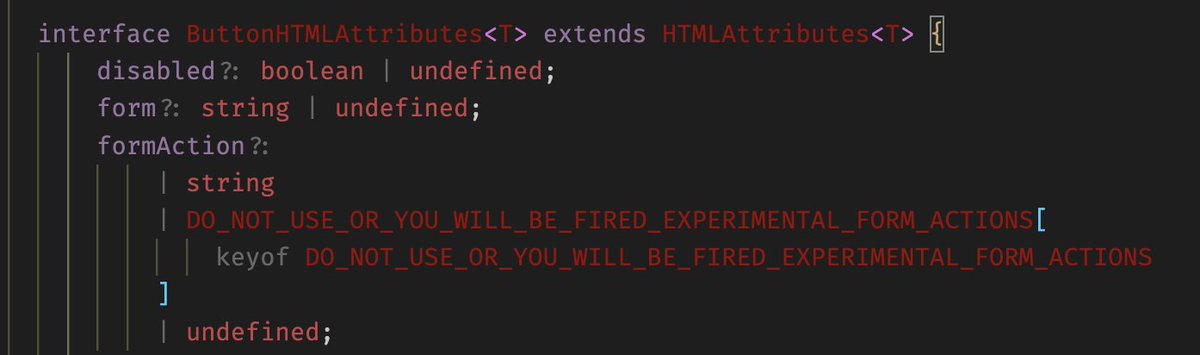
Cowards will call this "over-engineering"

1
30
28 Mar 2025
When QA tests your code 🤣
1
62
28 Mar 2025
I love this so much! The process, and especially the design. We need more watercolor-inspired designs!

So this morning I rolled out of bed and saw this post from Guillermo.
My first thought? "Damn, that looks sick!" And the best part? It's actually super easy to recreate with @shadcn.
Greetings to the guy who claims every shadcn/ui project looks the same - catch this! 👋
Watch in fullscreen ⬇️
1
24
22 Nov 2024
Dear @github, here's a full roadmap to world domination:
1. Provide AI-assisted issue search
That's it. The answers I find are always deep in an obscure issue closed years ago that I spend hours searching for. This would dramatically change my day-to-day experience.
21
7 Nov 2024
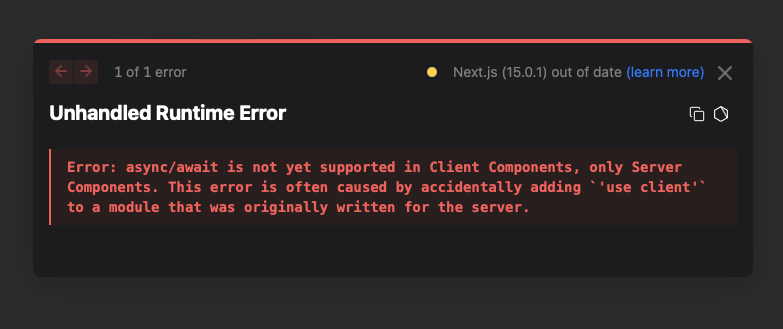
I love @nextjs , but is there really no way to get a useful stack trace? Errors output useless information and sometimes don't even give line numbers or even file names. So, do I just guess where the issue is? I'm having to do a binary chop search...
37
18 Oct 2024
Oof.


1
35