
502 Photos and videos


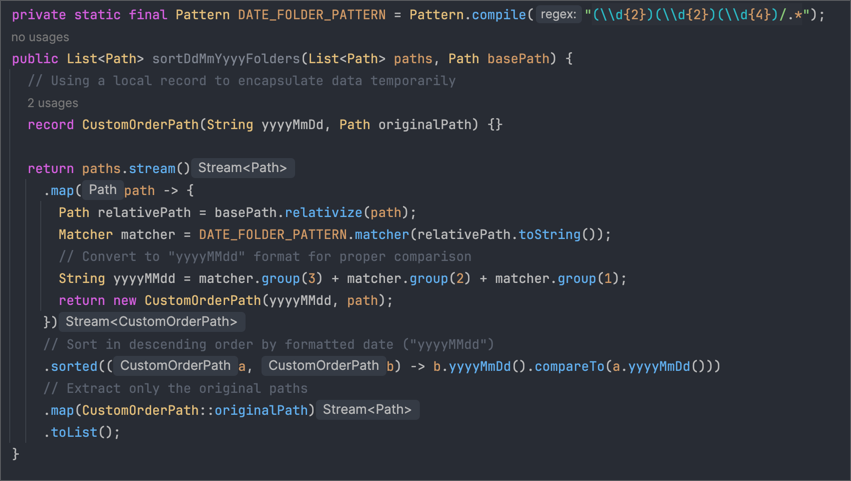



Use Ollama with Hermes Desktop by @NousResearch.
Hermes Desktop brings the same agent (its multi-agent engine, self-improving skills, and messaging integrations) into a desktop app on macOS, Windows, and Linux.
Run it on Ollama using local or cloud with one command:
ollama launch hermes-desktop
🧵

ALT Hermes Desktop with Ollama
35
121
913
52,302
kctang retweeted

I was a very early adopter of C . I started studying it in 1986, but I couldn’t get a compiler. I started using it around 1989. I inhaled every publication on the topic and became an acknowledged language lawyer. I wrote articles and columns for the C Report, and eventually became the editor-in-chief.
For over a decade, C was my language of choice. I like the initial batch of new features. I enjoyed multiple inheritance in 1992, and I thought the template syntax was a good idea.
I began to move away from C as the standard template library began to dominate. I did not like the direction that generics were taking the language. I much preferred dynamic polymorphism to compile time polymorphism. And I really didn’t like how the twisty little turns of the template syntax were contorting the language.
It has now been 30 years since I have done anything at all serious in C . I doubt I ever will again. Nowadays, if I want to get close to the metal, I use C.
I understand that many people still use and like the C , and that’s fine. I’m sure the language has a viable niche. But from my point of view, the language left me, I didn’t leave the language. It went in a direction that I didn’t want to go. I still have fond memories of those early years.
A similar thing happened to my attitude regarding Java, and C#. They both just got too big and unwieldy. I think that’s a function of standards committees.
So nowadays, when I need to write code, I try to pick a simple language like Clojure. Even the agents I use seem to prefer it.
71
21
403
43,348
ollama run gemma4:12b
Gemma 4 12B is updated on Ollama, and available across all platforms!
Try it on:
Claude Code
ollama launch claude --model gemma4:12b
Hermes Agent
ollama launch hermes --model gemma4:12b
OpenClaw
ollama launch openclaw --model gemma4:12b
Codex
ollama launch codex --model gemma4:12b
Codex App
ollama launch codex-app --model gemma4:12b
Let's go @googlegemma & @GoogleDeepMind !
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

54
115
1,177
74,069
kctang retweeted

May 27
Why is the creator of OpenCode pretty skeptical about AI productivity gains, and the hype around AI? A very conversation @thdxr (and lots of truth bombs:)
Timestamps:
00:00 Intro
07:03 Dax’s path into tech
09:04 Early startup experience
13:16 Getting involved with open source
16:13 OpenCode
23:17 Anthropic banning OpenCode
30:34 From terminal to GUI
32:34 OpenCode’s business model
36:33 Why inference is profitable
39:11 GPU bottlenecks
40:54 AI hype
45:50 AI spending
48:47 Dax’s memo
55:41 Dax’s skepticism of predictions
58:58 Engineering culture at OpenCode
1:02:38 How building works at OpenCode
1:05:36 Taste and quality
1:11:32 Dax’s work setup
1:12:35 The role of engineers and EMs
1:15:50 Advice for engineers
1:18:12 Book recommendation
Brought to you by:
• @AntithesisHQ – verify your system’s correctness without human review or traditional integration tests – and avoid bugs or outages antithesis.com/pragmatic
• @WorkOS – everything you need to make your app enterprise ready workos.com/
• @turbopuffer – a vector and full-text search engine built on object storage. It’s fast, cheap, and extremely scalable turbopuffer.com/pragmatic
Three interesting thoughts from Dax:
1. No AI-native coding agent company is “winning” by being better with AI.
Dax says that none of OpenCode’s competitors are crushing them, and that nobody is using AI so well that others cannot compete.
2. Most software engineers profit from AI as time gained, not increased output — unless you change incentives!
Dax says the natural way for software engineers to “cash out” their AI tooling gains is with time savings, by doing the same work as before, but faster. Until compensation and motivation structures change, most teams should expect output to stay flat while engineers go home earlier. There’s nothing wrong with this, but AI vendors sell a different outcome to CFOs: increased output.
3. AI code generation mutes the “guilt” of doing the wrong thing, but this builds up tech debt.
Pre-AI, writing a hack felt bad, the second time it felt really bad, and by the third time you’d often just refactor in order to fix up the code. Now, the agent hides the hack, which skews devs’ judgment and results in less tech debt being cleaned up.
54
171
2,220
228,961
kctang retweeted

May 19
3 commencement speakers were booed at the mention of Artificial Intelligence (Video)
1. Eric Schmidt, Google CEO
2. Scott Borchetta, Big Machine Records CEO
3. Gloria Caulfield, Tavistock Development VP
124
133
797
1,564,401
kctang retweeted

May 18
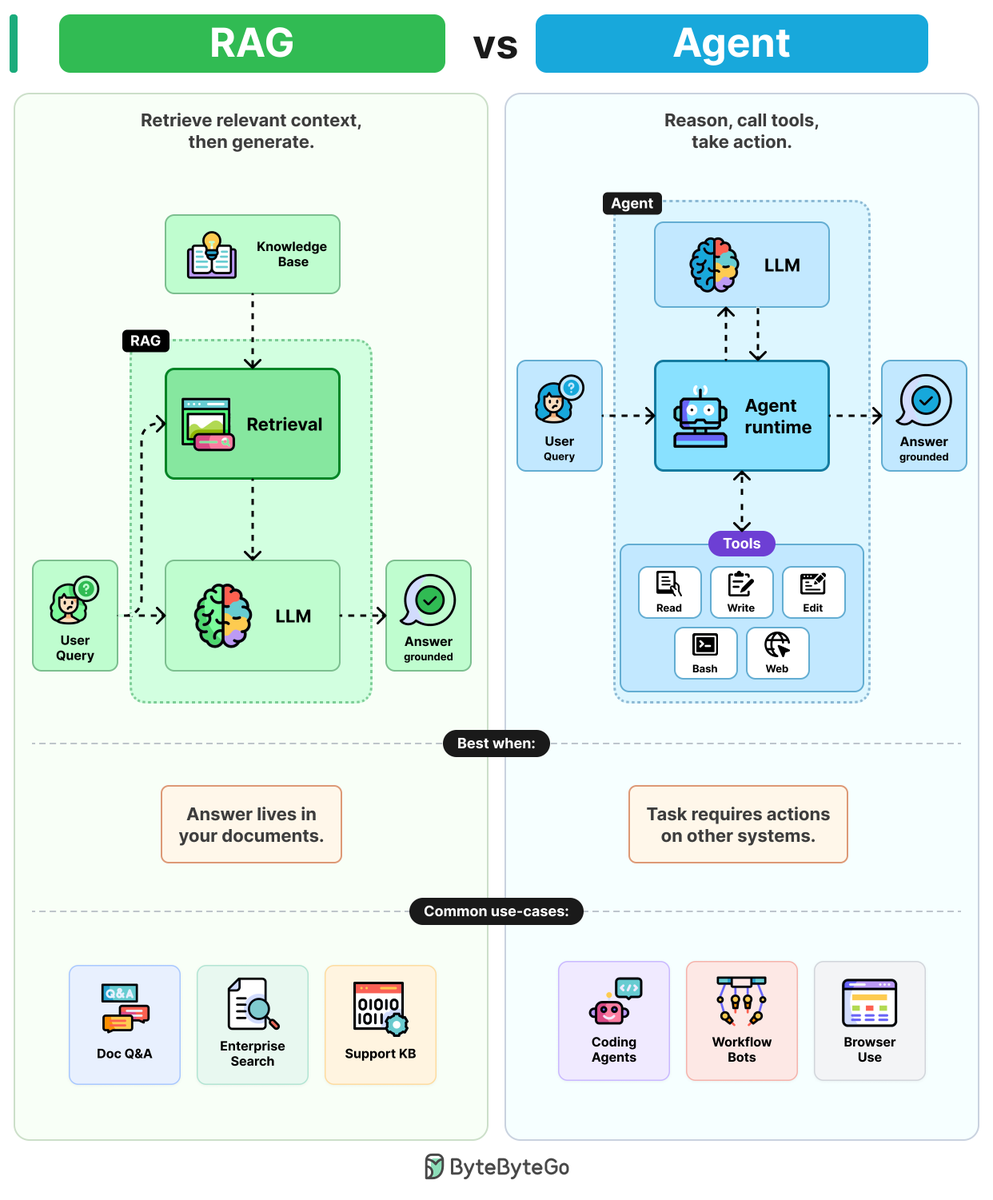
RAGs vs Agents
Ask an LLM about your company's data and it will guess. The two patterns that fix this are RAG and agents, and they solve different problems.
RAGs: RAGs combine LLMs with retrieval to ground answers in 4 steps.
Step 1: The user query is embedded and sent to a retrieval step.
Step 2: Retrieval pulls the most relevant chunks from a knowledge base (PDFs, wikis, etc.)
Step 3: Those chunks are pasted into the prompt as context.
Step 4: The LLM writes the answer, grounded in the retrieved text.
One retrieval. One generation. Cheap, predictable, and easy to debug.
Agents: Agents wrap LLMs in a reasoning loop with tools to take action.
Step 1: The user query goes into the agent runtime. A reasoning loop wrapped around an LLM.
Step 2: The LLM reads the goal and picks a tool (Read, Write, Edit, Bash, etc.)
Step 3: The runtime executes the tool and feeds the result back to the LLM.
Step 4: The LLM reasons again, picks the next tool, and loops until the task is done.
More flexible. More tokens. Harder to debug because errors drift across steps.
The rule of thumb: Use RAG when the answer lives in your documents. Use an agent when the answer requires action on other systems.
Over to you: When do you prefer RAG over agent?
16
122
661
33,793
kctang retweeted

May 17
As a software developer, it's very important to know Galton’s Law of Mediocrity (Regression Towards the Mean) in the context of AI.
According to Galton, as long as you are better than the average or have skills that AI cannot replicate (e.g., creativity, high agency, determination, communication, and teamwork), you are going to be fine in your career.

17
38
420
53,590

Looks like AI honeymoon period is over 😉
Now everyone is slowly putting token limits and switching to API usage based billing.
#FreeLunchIsOver
55
129
1,764
88,051

open 2 @googlechrome browser windows with google drive, drag selected files/folders from one window to another to copy/move. please support this?
ubuntu 26.04 (gnome 50) stopped supporting google drive and there's no native app like mac.
117
kctang retweeted

Modern problems require modern solutions.

347
3,886
43,253
1,767,166
kctang retweeted
Apr 20
Agile and Scrum evolved in an era when software development took significant time, and two-week sprints enabled us to gather feedback and adapt the product to meet customer demands.
Nowadays, AI compresses the development time so much that it makes more sense to use Kanban instead.
The larger the company, the more difficult the AI adoption will be since it will become political, rather than practical.
13
16
119
20,464
A good description of how AI will impact software developers. Still listening, but tldr so far... Programmers need to shift from typing to thinking... Traditional SDLC no longer works, instead do...
youtu.be/sDy55DIkIJ0?si=7mBg…
16
kctang retweeted

Apr 8
Lots of love for Gemma 4! Team just told me it’s already had 10M downloads since last week’s launch. Gemma models have now been downloaded 500M times! Excited to see what you all are creating 👀
252
296
5,870
377,630
.@GoogleDeepMind Gemma 4 is here with state-of-the-art models targeting edge and workstations.
Requires Ollama 0.20 that is rolling out.
4 models:
4B Effective (E4B)
ollama run gemma4:e4b
2B Effective (E2B)
ollama run gemma4:e2b
26B (4B active MoE)
ollama run gemma4:26b
31B (Dense)
ollama run gemma4:31b
Benchmarks 👇👇👇


Start experimenting with Gemma 4 now in @GoogleAIStudio or download the model weights from @HuggingFace, @Kaggle and @Ollama.
Learn more → goo.gle/48ef4TB
99
449
3,858
383,722

Database Design Doesn't Start With Table. It Starts With Consequences
open.substack.com/pub/petari…
1
3
18
1,201