
cto @latchbio, data infrastructure for biology
Joined May 2020
- Tweets 1,627
- Following 1,344
- Followers 7,148
- Likes 2,773
487 Photos and videos







Pinned Tweet

May 6
Gave a talk to Machine Learning @ Berkeley on benchmarking frontier models on spatial biology.
Why understanding how assays work is important, what verifiability might look like with messy biology infrastructure challenges running agentic evals at scale.
6
11
179
14,327
Jun 12
The analogy with Moore’s law is weak because the curve tracks progress in a measurement tool weakly coupled, and sometimes irrelevant, to most end goals in biotech. Even in the subset of cases where it’s directly used, such as prenatal screening, still don’t see broad adoption of the best sequencing technology (which you would expect immediately) because the rate-limiting step is elsewhere: generally regulation, reimbursement. The curve is often used to paint a misleading picture of where the bottlenecks are, and can be used to sell or build products around constraints that are not actually rate-limiting.
Jun 12

Hard to think of another chart in biology more misunderstood and misappropriated
5
5
53
9,597
Jun 12
Hard to think of another chart in biology more misunderstood and misappropriated
6
12
156
33,495
Jun 11
Introducing EpiBench, an agentic benchmark for practical epigenomics analysis.
106 evaluations span CUT&Tag/CUT&RUN, ATAC-seq, ChIP-seq, and DNA methylation workflows. The best agent–harness pair passes 45.0% of evaluations.
Evaluations reflect the assay outputs scientists use in practice. A task may depend on alignment files, peak calls, methylation tables, QC metrics, sample metadata, genomic annotations, or downstream summaries. Solving them requires a mix of coding, data analysis, and scientific judgment.
Ground truth is hard to define even for short-horizon scientific tasks. Alternative task interpretations can produce multiple plausible answers. Candidate tasks are hardened through manual quality control. We remove prompts that over-specify the method, answers that can be solved with general literature knowledge, and ground truths that fail to reproduce under peer reproduction.
Short-horizon tasks are the current frontier for scientific agents in epigenomics. Before models can own deeper biological reasoning, they need to become reliable at local assay-specific decisions.
4
22
103
7,469
Jun 11
Paper: latch.bio/epibench
Blog: blog.latch.bio/p/epibench-ai…
Play with tasks trajectories on benchmarks.bio.
3
1
13
1,113
Kenny Workman retweeted

Jun 10
Introducing @PoeticHQ: a new AI system that executes complex multi-hour tasks with 99% accuracy and 10x fewer tokens than agents.
We raised $50M at $500M from Kleiner Perkins, Founders Fund, First Harmonic, and Genius Ventures to build AI that does complex work inside Fortune 500 companies without hallucination.
While code is too brittle, agents are too unpredictable. The work that runs the global economy - anti-money laundering, fraud investigations, underwriting - needs extreme accuracy.
So we built a new kind of software that pairs the flexibility of AI with the predictability of code.
When the world stays the same, Poetic runs fixed code: fast, cheap, identical every time. When the world changes, Poetic uses AI to regenerate its approach and find its way back to the objective.
In one year, we went from zero to an eight-figure run rate as a team of four.
Since then, we’ve scaled the team and executed the highest-stakes processes at AIG, SoFi, and Chime. At SoFi, a large US bank, Poetic reached 99% quality on fraud investigations in five weeks.
319
211
1,678
1,251,879
Jun 6
Slowly at first, then all at once
May 3
Latch almost died two years ago. Selling data infrastructure direct to pharma was not leading to sustainable growth. We found a group of fast moving customers closer to the source of data generation: teams engineering kits machines for single cell, spatial and proteomics assays. They brand and distribute Latch, focusing on difficult scientific problems specific to how each assay works, while we focus on keeping infra performant as data throughput continues to ride exponential. Today our team is nearly 50 scientists and engineers with one dedicated sales engineer. Have learned an incredible amount about the internals and nuances of different assay technology working with customers like Vizgen, TakaraBio, Atrandi. Scientists in 15/20 top market cap pharma, biotech startups and many academic labs use Latch, many of them without realizing its a standalone company. This foundation has proven to be an effective way to think about, engineer and deploy a more powerful tool for scientists: agents for biological data.

3
1
94
15,975
Jun 3
A few talks at the intersection of single cell biology x agent engineering:
- Understanding library prep sequencing is important
- Repurposing data infrastructure for agent consumption
- How to benchmark frontier agents on single cell analysis
1
10
86
16,777
May 29
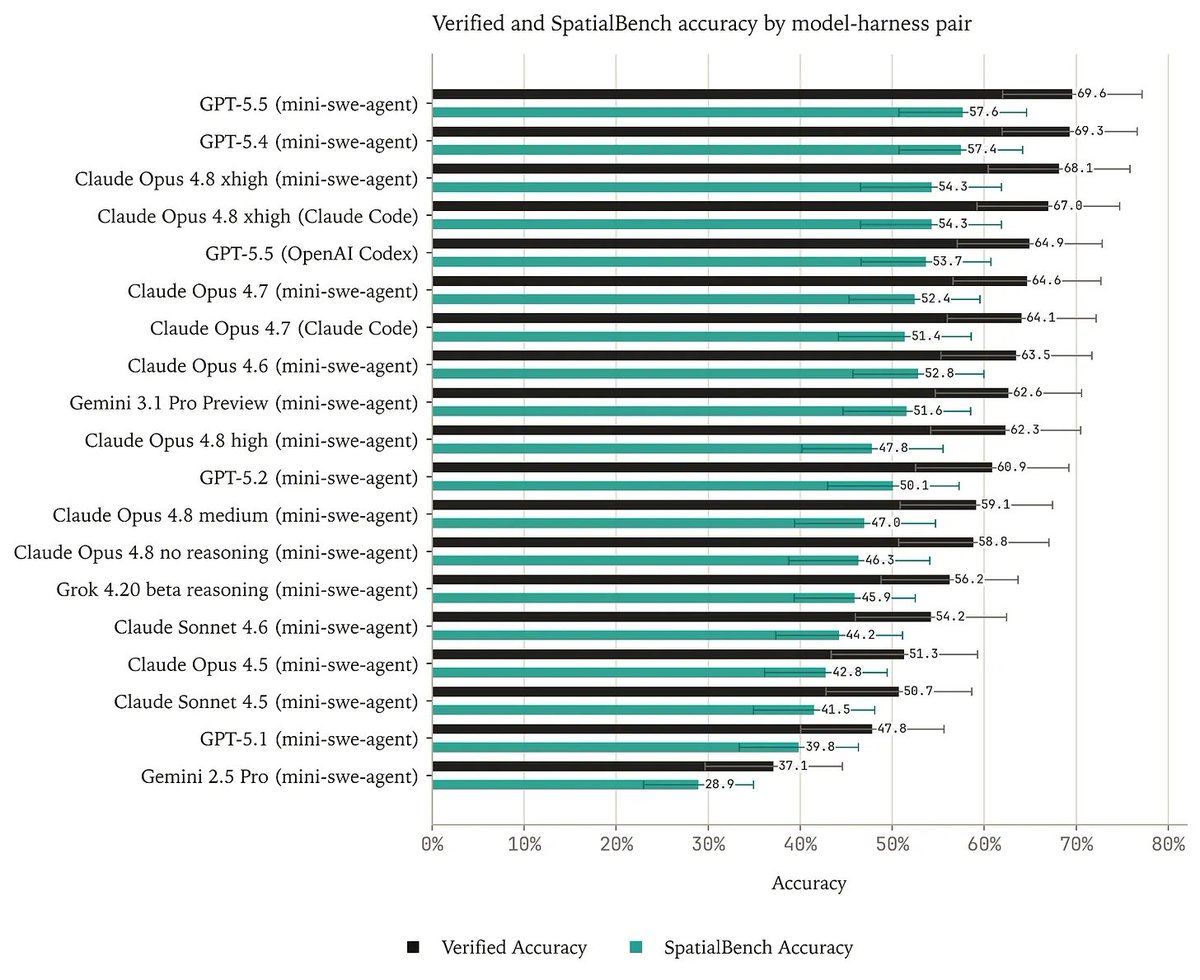
After several months of analyzing model trajectories on SpatialBench, we found issues in a subset of evals.
Some tasks depended on analysis decisions not specified in the prompt. Others had grader thresholds that were too narrow, rejecting valid solution paths the original domain expert had not considered.
We ran two rounds of independent expert attempts without access to solutions. This produced SpatialBench Verified: a 115-problem gold-standard subset of the original 159 evals where expected answers can be reproduced from only the prompt and associated data.
Model ordering is largely preserved, but scores increase 11.6pp on average.
Verifiability in biology is hard because correct answers often depend on tacit analysis choices. Our results suggest independent human verification should be a core part of benchmark construction.
1
6
24
1,982
May 29
More information with examples and project materials (subset of solutions, notes, expert instructions etc.): blog.latch.bio/p/human-verif…
Numbers for the verified subset: benchmarks.bio/
We'll use SpatialBench Verified by default in future reports. Working on similar efforts in other domains of biology.
3
497
May 28
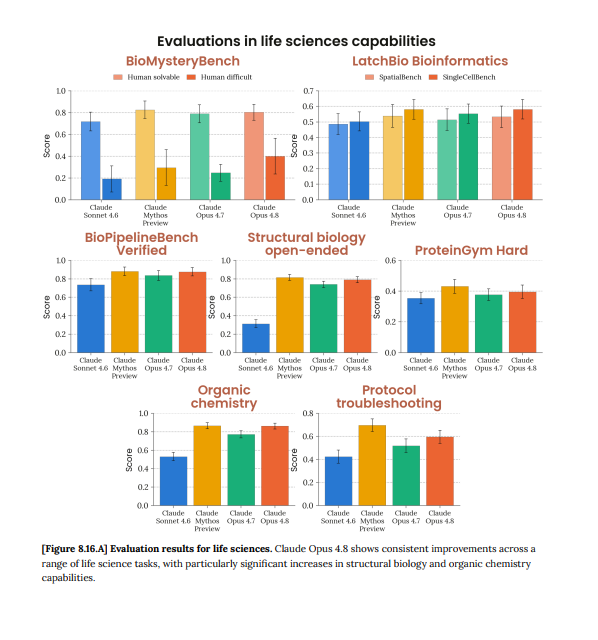
Biology is the next agentic frontier after coding. Anthropic is aggressively improving their models on routine data analysis with careful attention to nuances of different assay types. Opus 4.8 is noticeably better at single cell / spatial analysis. We have already rolled it out to customers across pharma and academia. Cool to see our benchmarks on the system card.


Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
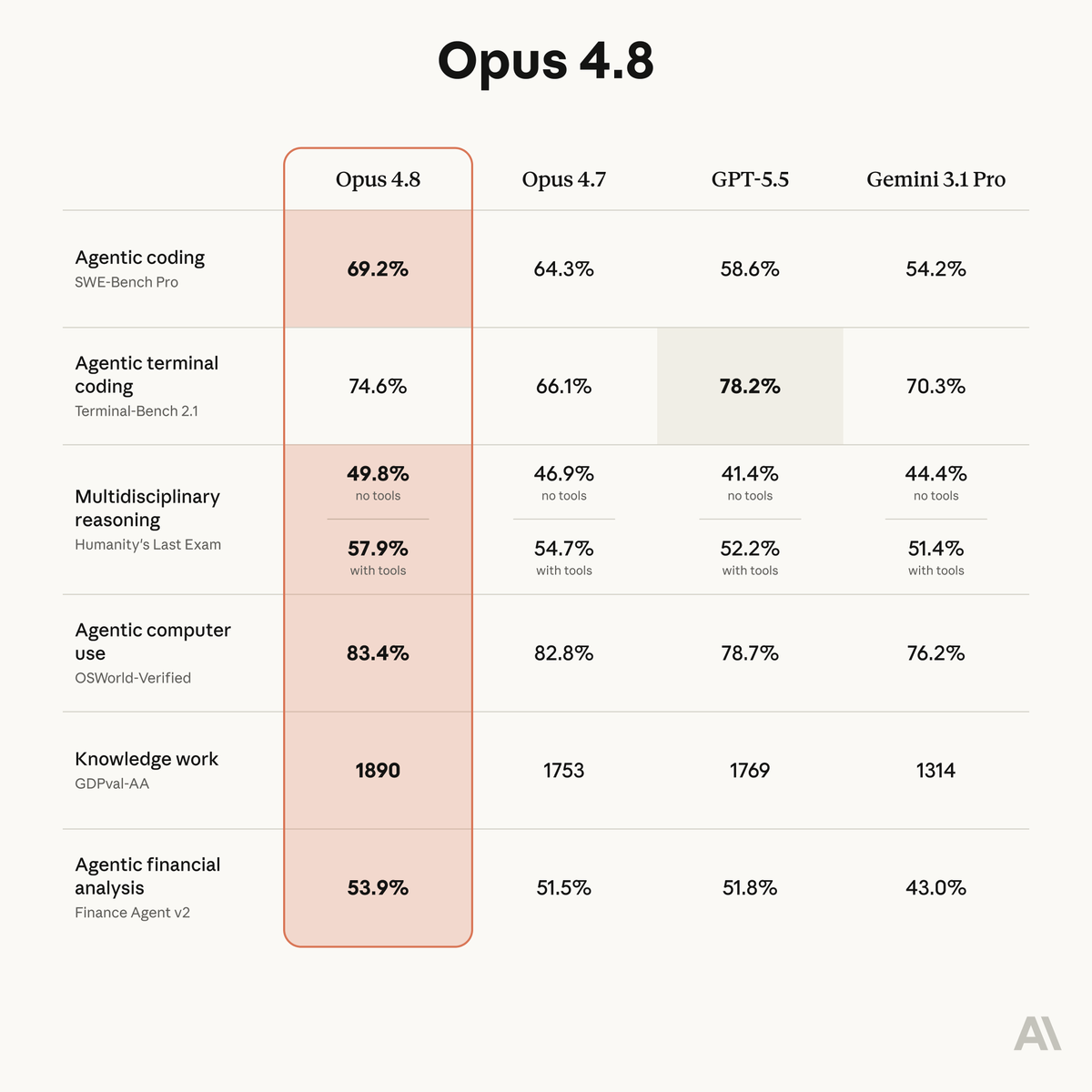
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
8
41
285
21,834
May 27
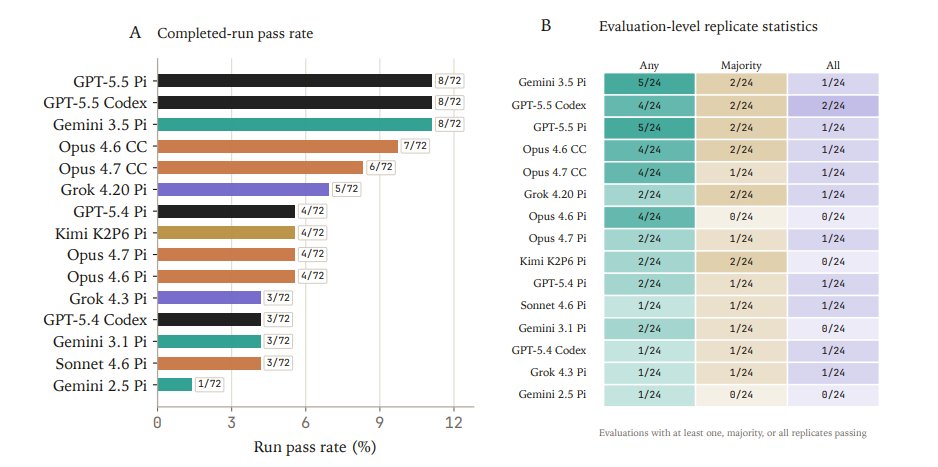
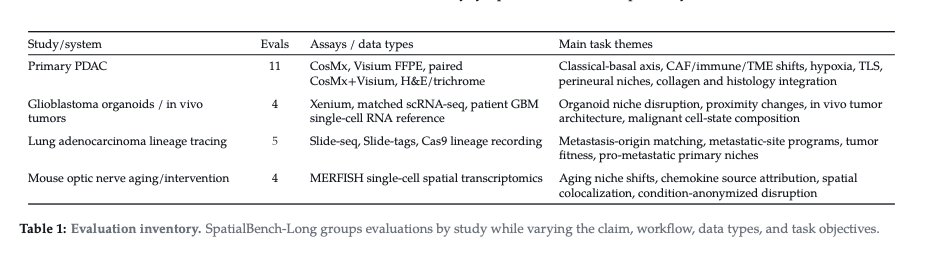
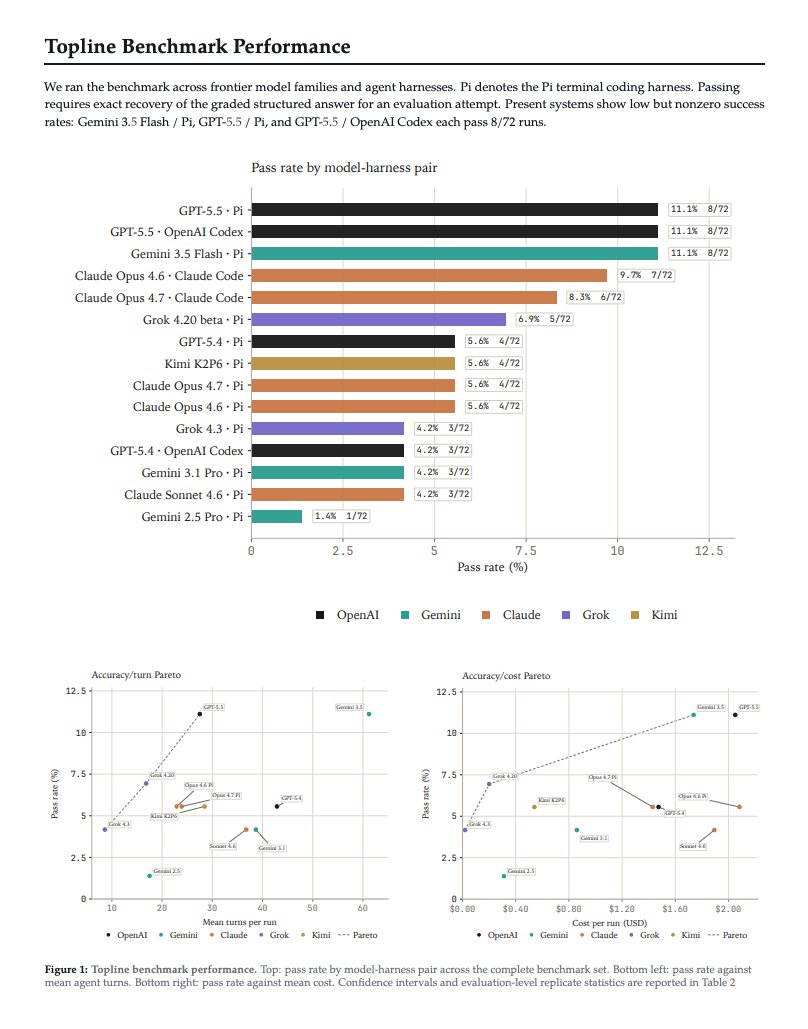
Introducing SpatialBench-Long, a benchmark for long-horizon spatial biology. Agents must recover biological claims from raw data and realistic experimental context without prescribed methods.
24 evals span primary tumors, organoids, xenograft models, lineage-tracing systems, and aging/intervention biology. The best agents score 11.1%.
1
17
67
8,465
May 27
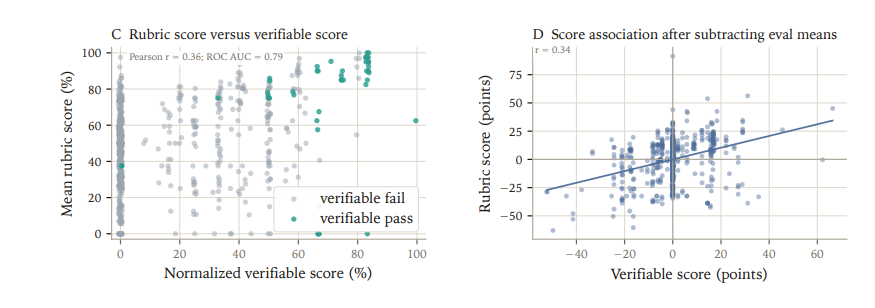
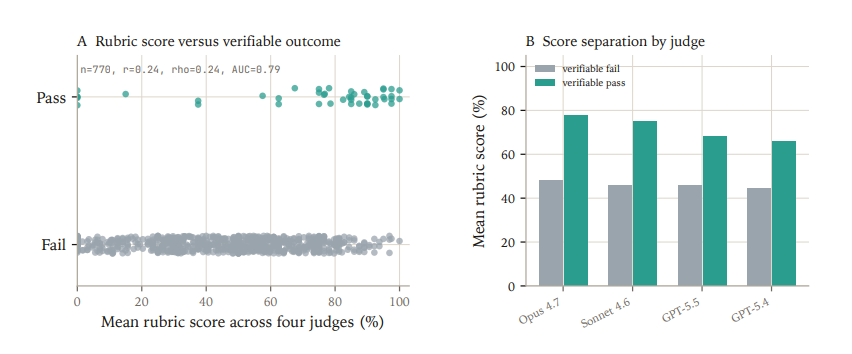
Pairing manual trajectory review with rubric and verifiable scores provides more tools to interpret model failures.
In-practice, manual trajectory inspection is a first-class tool to interpret this low pass rate benchmark data. Eval authors maintain reproduction notes to provide a record for future benchmark updates, especially as stronger models may solve tasks through unanticipated but valid analysis paths that challenge current grading assumptions.
1
400
May 27
Results suggest compounding local analysis errors prevent reliable long-horizon scientific reasoning.
Before models can reliably reason about disease mechanisms, drug response, or other deep results in biology, they must become procedurally competent in local steps.
But the few task completions we observed were very impressive. It seems there is a realistic path to agents that behave a lot like scientists.
Manuscript: latch.bio/spatialbench-long
Leaderboard: benchmarks.bio/
1
3
376