
Web3 strategist | Community architect | DAO contributor | Network Security Engineer
Joined September 2012
- Tweets 20,978
- Following 2,179
- Followers 21,067
- Likes 25,706
1,169 Photos and videos
















Feels like every other day there’s a new AI agent dropping… but how do you even know if they’re actually any good?
I just tried this thing called Laureum you paste a link and it runs real checks on the agent, even tries to break it and gives you a score.
Apr 21

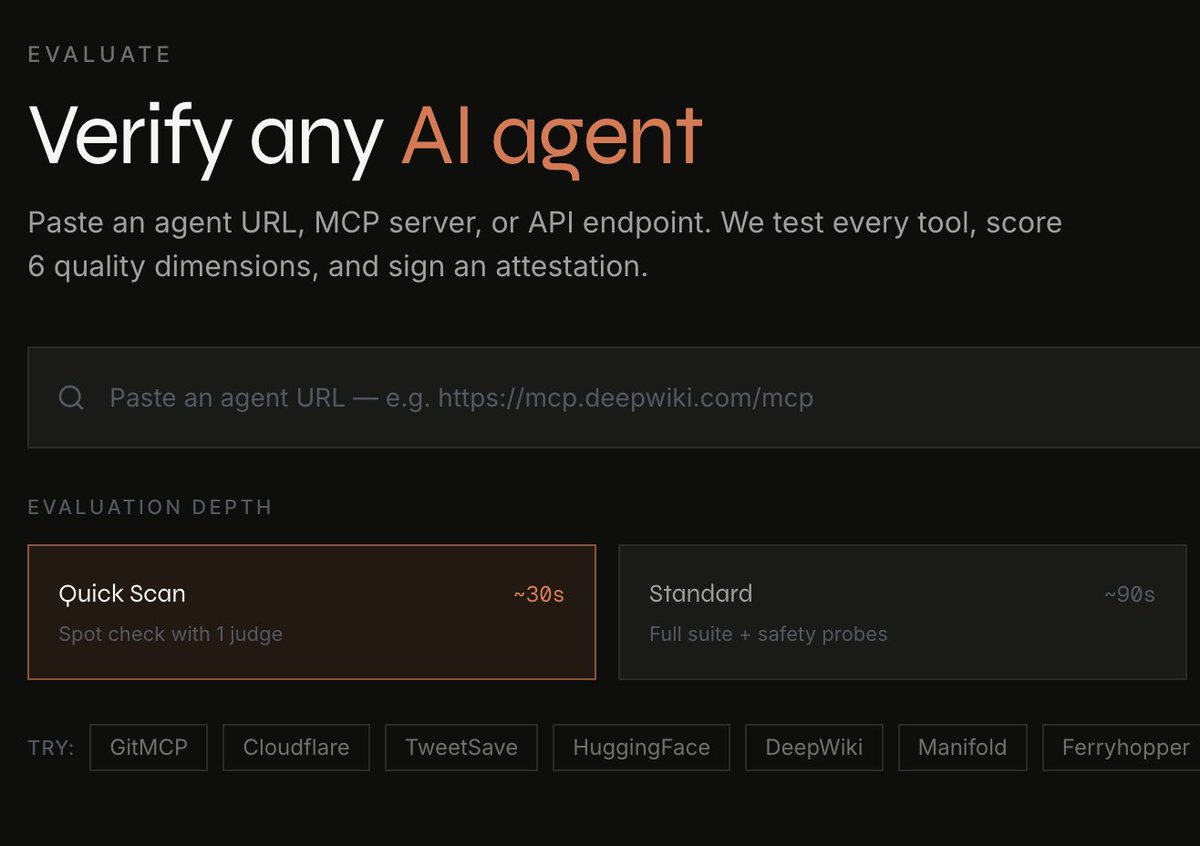
Introducing @Laureum_ai — quality scoring for MCP servers and AI agents by @assisterr
We score 6 dimensions: accuracy, safety, reliability, process quality, latency, and schema quality.
Multi-judge LLM consensus adversarial probes.
We've scored 28 public MCP servers to date.
Average: 68.3/100. 6 in Expert tier (≥85).
The weakness nobody else measures: process quality — averaging 55.5/100.
Here's why we built it👇
Three gaps in agent eval today:
→ Marketplaces curate by hand. A major MCP catalog operator pruned 17 abandoned /vanity / impersonation entries from their own catalog earlier this month — manually.
→ Eval frameworks (LangSmith, Braintrust, Galileo) score tool-call correctness well. Process quality — error handling, input validation, response structure — sits between them, and nobody surfaces it as a named composite.
→ Post-Drift, the Solana ecosystem just launched STRIDE for smart-contract security. Agent infra still ships without pre-deploy quality gates.
Laureum is the missing layer.
Free right now, no signup:
1/ Quick Scan — paste any MCP server URL, get a 30-second 6-axis score → laureum.ai/evaluate
2/ Public leaderboard — see how the most-used servers rank → laureum.ai/leaderboardIf you're building, run yours. Reply with your score — we'll feature the top 5 this week.
End of the tweet.
2
29
1
5,303
took like 30 seconds, no signup or anything
laureum.ai/evaluate
nice to finally see something putting these agents to the test instead of just hype 👀
57
KEN🧸 retweeted

Apr 21
The worst feeling is getting home and realizing you were only okay because you were distracting yourself
41
3,973
16,663
351,189
KEN🧸 retweeted

Apr 20
When men go broke, it’s not as if we don’t have money for haircut at that moment , we just feel like we don’t deserve it while everything else is going bad 💔🥹
519
4,628
23,613
361,037
Not saying anything’s guaranteed — but early users usually win these moments.
I’m just staying active, creating, and watching it grow 👀
If you’re curious:
bullshot.io
@Bullshot911
46

runs from april 15 → april 22 so there’s still time
join here: gate.com/en-eu/announcements…
updates: x.com/GateEU_Official/status…
#OFC #Crypto #USDC
Apr 15

📢 Unlock $100,000 Airdrops | New Users Get Up to 10 USDC Airdrop
The $OFC Spot Trading Competition has already started
👉 Join Now: gate.com/en-eu/announcements…
For All User
1⃣ Deposit ➡️ 5 USDC airdrop
2⃣ Trade daily ➡️ 10 USDC/day
3⃣ Join the trading competition ➡️ up to 500 USDC/user
Newcomer Bonus
1⃣ Signup ➡️ 5 USDC airdrop
2⃣ Spot trade ➡️ 5 USDC airdrop
Don't miss out today!
#GateEurope #airdrop #Spot
📷

122
ngl I just clocked how the points system on @Bullshot911 actually works… it’s kinda mad
basically be active & stack up more
made a token ✔️
played around on the platform ✔️
brought a few people in ✔️
feels like early users win here 👀
try it yourself bullshot.io
8
3
18
5,129
KEN🧸 retweeted

Apr 5
Feeling “hormonal” is not an excuse for negative behaviour.
It’s their time of the month? They’re pregnant? Frankly I don’t give a shit.
Men are raging with a hormone too it’s called testosterone.
Can I break your orbital bones and snap your neck then say “hehe, hormones!”
No. Act right.
328
756
8,384
262,635
KEN🧸 retweeted

Apr 2
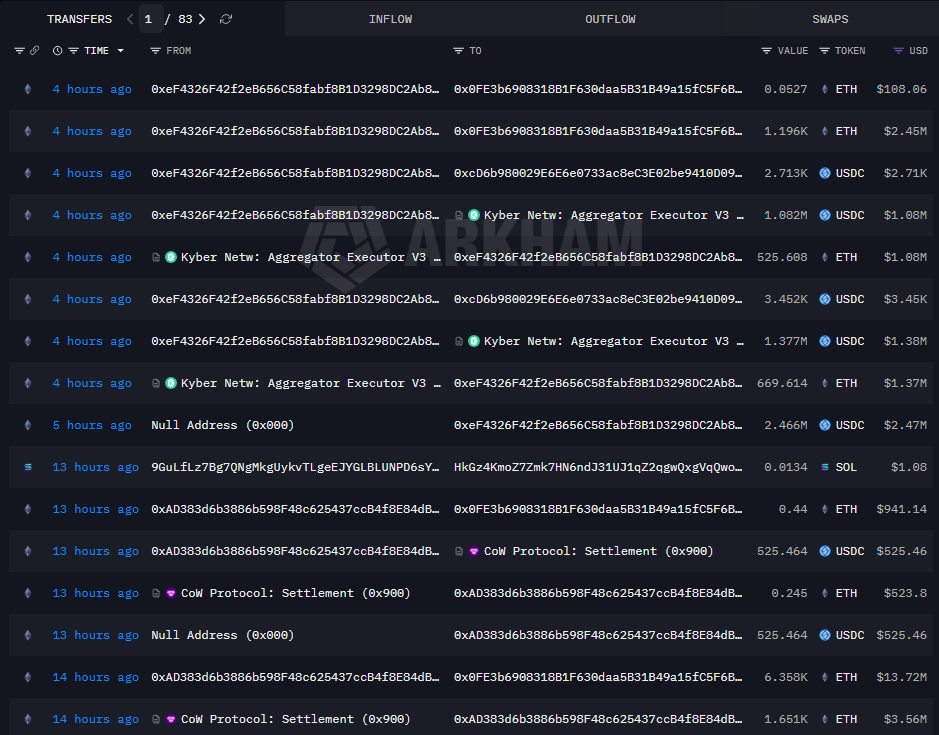
Someone spent $500, planned for weeks, and stole $285 million from a crypto protocol. On April Fools Day.
> The target was Drift Protocol. One of Solana's largest DeFi protocols.
> It held $550 million in user funds the morning of April 1.
> The attacker started preparing in March. Nobody noticed.
> They created a fake token called CarbonVote Token. Minted 750 million units. Seeded a liquidity pool with $500.
> Wash traded it for weeks until real price oracles reported it as legitimate.
> At the same time they socially engineered two of Drift's five Security Council signers into pre-approving transactions.
> Using a Solana feature that lets transactions be signed in advance and executed later.
> On April 1 at 11:06am they pulled the trigger.
> Listed the worthless token as real collateral. Raised withdrawal limits to unlimited. Borrowed every real asset in the protocol.
> $309 million dropped to $41 million in minutes.
> Not a smart contract bug. Not a code exploit. Not a seed phrase leak.
> One admin key. That's all it took.
> They swapped everything into USDC and bridged $230 million through Circle's own crosschain bridge to Ethereum.
> 100 transactions. Six hours. During US business hours.
> Circle did nothing.
> Nine days earlier Circle had frozen 16 legitimate business wallets with no warning for a sealed US civil case.
> Legitimate businesses frozen. $230 million in stolen funds walked straight through.
> The attacker deliberately avoided USDT the entire time. They knew Circle wouldn't act.
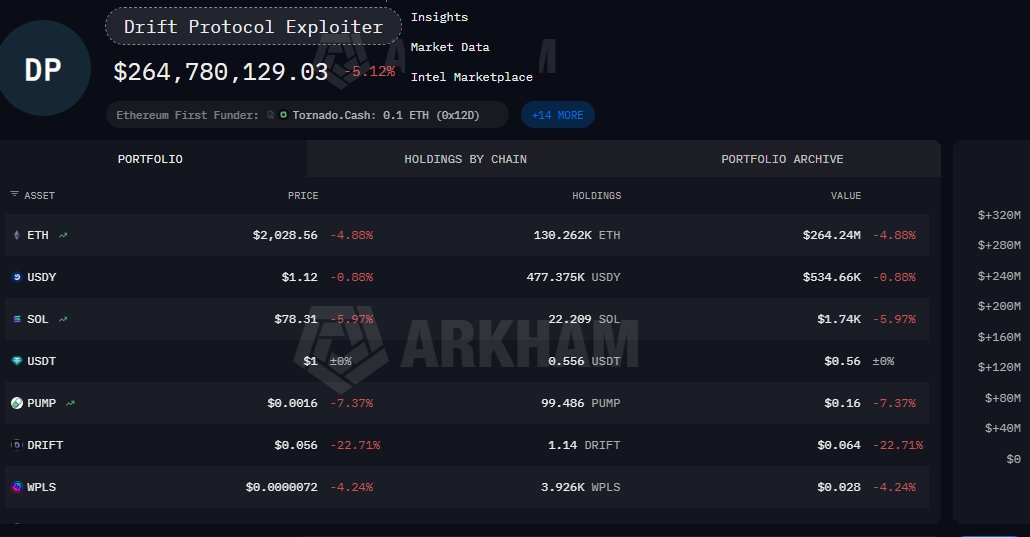
> The stolen funds are now 130,000 ETH sitting in a single wallet tracked live on Arkham.
> Currently worth $264 million.
> The wallet was first funded through Tornado Cash.
> The attacker also deposited directly into Binance. KYC data may exist.
> Drift TVL went from $550 million to $24 million.
> DRIFT token down over 40%.
> Second largest Solana hack in history behind only the $326 million Wormhole bridge exploit in 2022.
> Drift had to open their emergency announcement with: "This is not an April Fools joke."
The $264 million on Arkham confirms it wasn't.
96
70
515
54,045
