
still somewhat loves computers • some exp with llms
Joined June 2025
- Tweets 283
- Following 233
- Followers 99
- Likes 11,606
42 Photos and videos














Pinned Tweet

Jun 6
Visualizing vision token compression for VLM using Pixel Shuffle
5
5
80
7,687
Jun 15
when you finally get Fable access through a shady token broker but Dario intercepts you:

现在有些中转站还能使用 Fable 5
用户:阿姨,你们的 Fable 5 怎么还能使用
中转站阿姨:我们有内部渠道
中转站阿姨:我们有存货
用户:知道了,谢谢中转站阿姨

1
3
152
Jun 14
summary instructions in papers brought to you by deepmind (:

"From AGI to ASI": new paper from our team.
This report investigates how AI might develop beyond AGI. It describes theoretical limits, potential pathways, and potential bottlenecks.
arxiv.org/abs/2606.12683
3
15
1,648
Jun 14
might've done the opposite of catching the last chopper out of nam last year
58
Jun 13
singularity what if: text diffusion break out came before transformers
1
4
404
Jun 12
memory startups are not slopshops but these would be just open-source libraries if not for da bubble
Jun 10

Memory startups are a complete tarpit and I’m surprised YC hasn’t figured this out sooner
105
Jun 10
uh i want to hot swap codex "auto-approval" with an advisor like agent
84
Jun 8

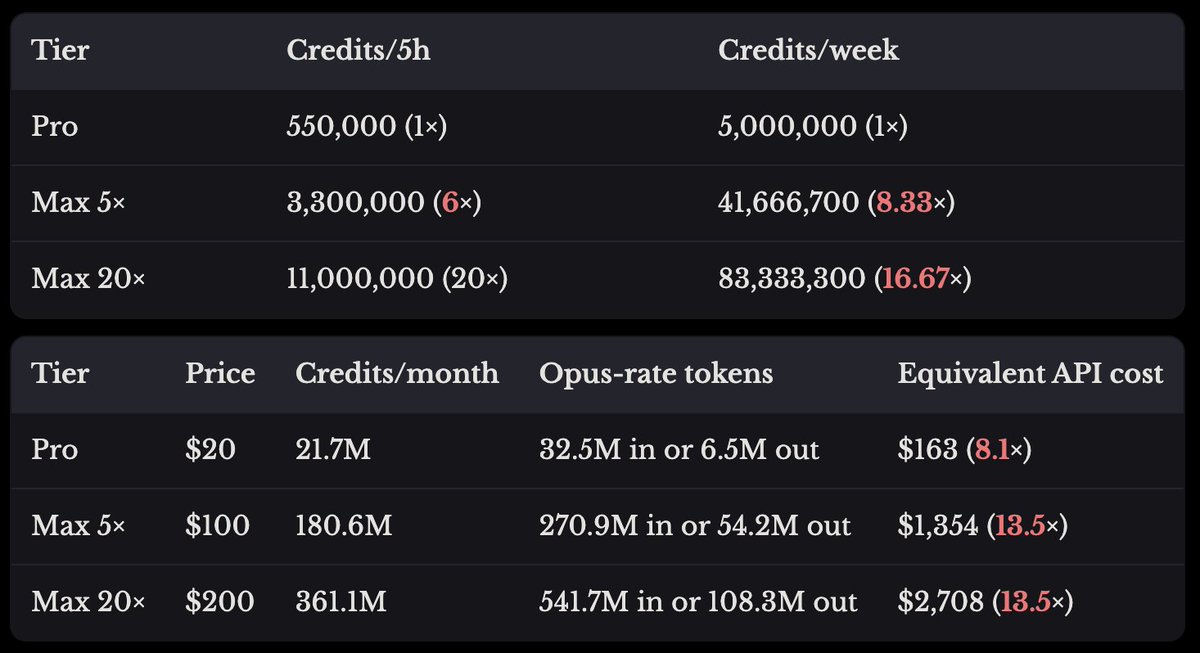
suspiciously precise floats, or,
how I got Claude's real limits
link below
2
138
Jun 7
curious about these problems with such low pass rate

For days, many folks here are citing DeepSWE as the benchmark that restores reality only because it shows GPT 5.5 on top. But actually, it almost gets a single entry right: the top one, and all the rest is shuffled.
2
279
Jun 6
they have completely killed the reach for small account

8
84
5,449
Jun 6
Visualizing vision token compression for VLM using Pixel Shuffle
5
5
80
7,687
Jun 6
Yes, It's live: ctx-0.github.io/pixel-shuffl…
Yes, that's fumo.
Here's the repo: github.com/ctx-0/pixel-shuff…
1
3
529

Jun 4
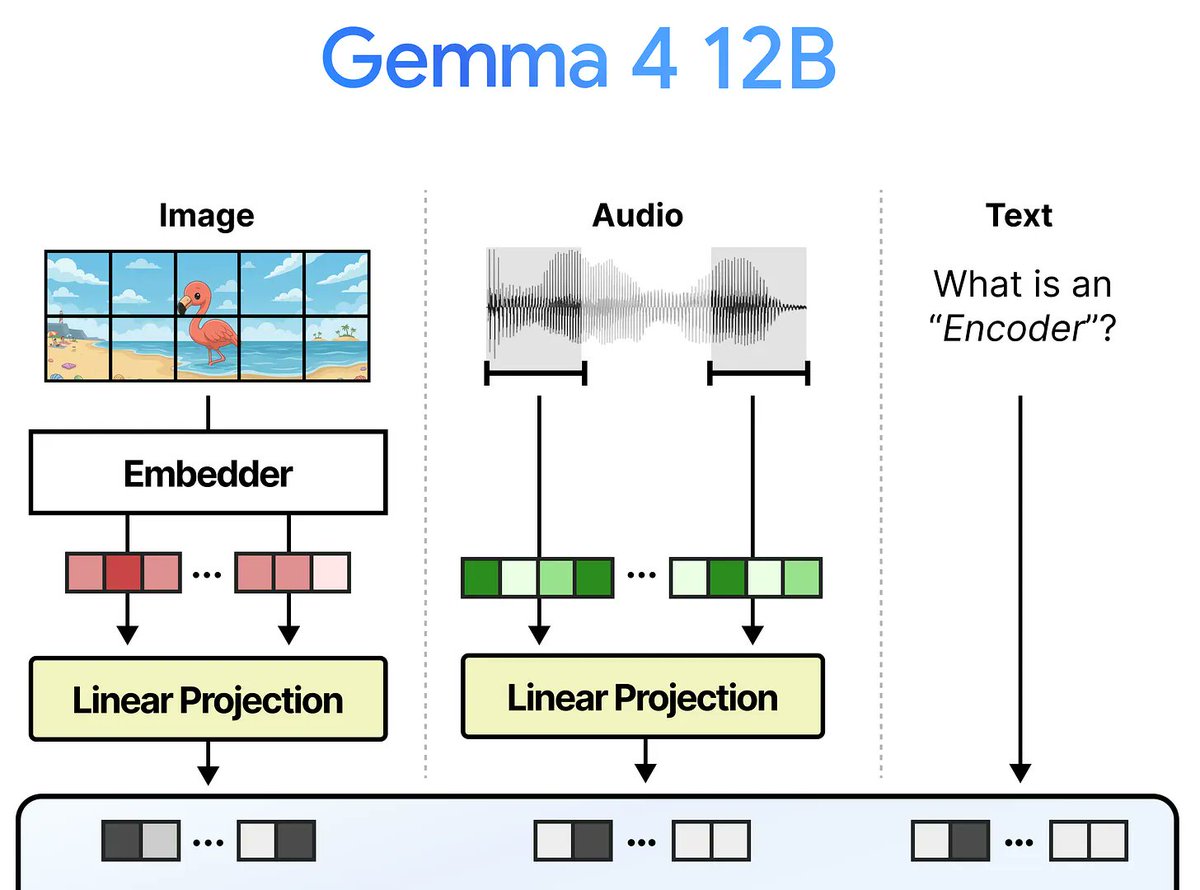
are we never getting a unified encoder multimodality

For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/
3
256