
Assistant professor at POSTECH GSAI/CSE | Prev. UNIST @unc @unccs @uncnlp @AdobeResearch @AmazonScience
Joined September 2009
- Tweets 830
- Following 518
- Followers 405
- Likes 668
18 Photos and videos
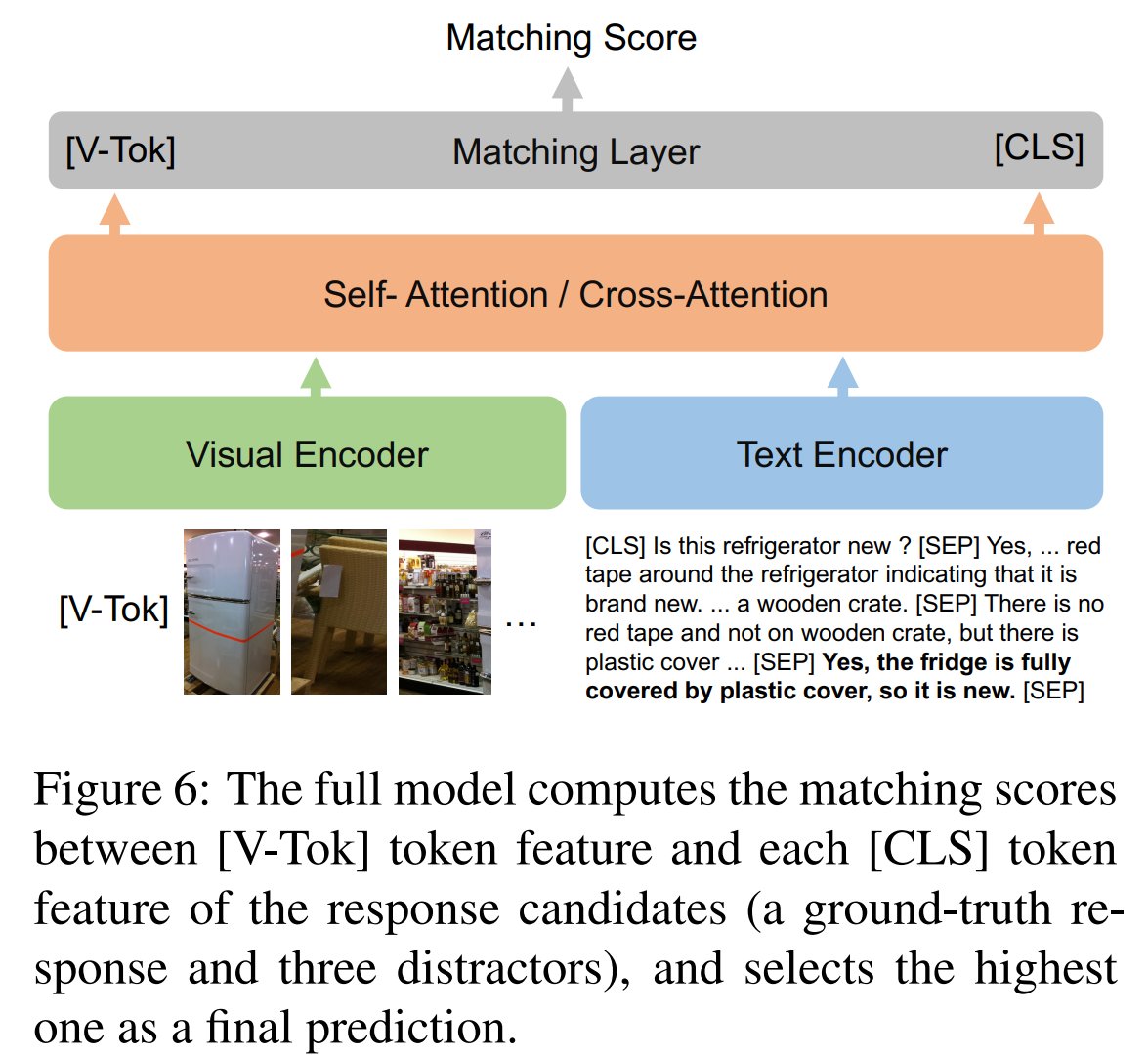








Pinned Tweet

10 Oct 2024
A new #EMNLP2024 paper on creative long story generation!
Collaborative critics, guided by a leader, can significantly enhance the creativity of storytelling.
Interesting work by @minwookbae!
10 Oct 2024

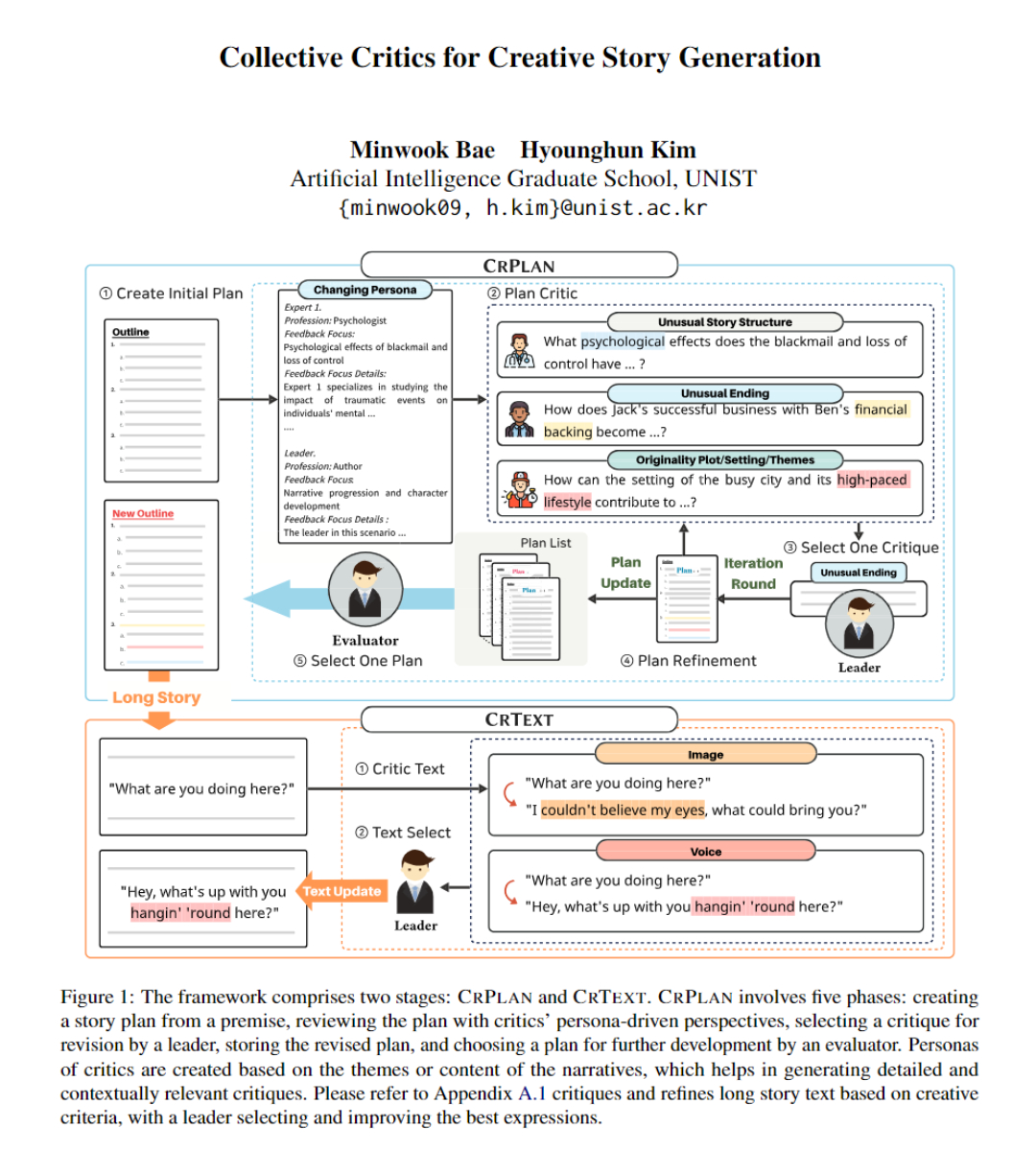
📖 Excited to present our novel long-story generation framework, Collective Critics for Creative Story Generation (CritiCS)!
Previous long-story generation research mainly focused on coherence, overlooking creative and captivating storytelling. However, what we truly want is to generate stories that captivate readers. Therefore, we developed CritiCS—a framework designed to foster creativity and produce captivating long-form stories through a collective critique mechanism.
Thanks to @khsquared and the amazing Language & Intelligence Lab family for their invaluable insights and continuous support!
1
9
1,338
Hyounghun Kim retweeted

14 Dec 2025
Deeply happy and honored to be elected as an ACL Fellow -- and to be a part of the respected cohort of this past years' fellows (congrats everyone)! 🙏
All the credit (and sincere gratitude) to all my amazing students, postdocs, collaborators, mentors, and family! 🤗💙

25
34
178
43,636
Hyounghun Kim retweeted

16 Jun 2025
🚨Our paper "Enabling Chatbots with Eyes and Ears" has been accepted to #ACL2025NLP!
👀👂We explore how chatbots can integrate visual, auditory, and textual modalities to support multi-party, multi-session, real-world immersive conversations.
🧵👇

1
8
8
646
Hyounghun Kim retweeted

5 May 2025
Extremely excited to announce that I will be joining @UTAustin @UTCompSci in August 2025 as an Assistant Professor! 🎉
I’m looking forward to continuing to develop AI agents that interact/communicate with people, each other, and the multimodal world. I’ll be recruiting PhD students for Fall 2026 across a range of connected topics (details: esteng.github.io/) and plan on recruiting interns for Fall 2025 as well.
A huge shoutout to my mentors who have supported and shaped my research! Especially grateful to my postdoc advisor @mohitban47 for helping me grow along the whole spectrum of PI skills, and my PhD advisor @ben_vandurme for shaping my trajectory as a researcher, and of course the amazing students/collaborators from @uncnlp and @jhuclsp 🙏

92
63
461
57,942
Hyounghun Kim retweeted
21 Apr 2025
In Singapore for #ICLR2025 this week to present the papers keynotes below 👇, and looking forward to seeing everyone -- happy to chat about research, or faculty postdoc phd positions, or simply hanging out (feel free to ping to set up a meeting)! 🙂
Also meet several of our awesome students/postdocs/collaborators who will be presenting this exciting batch of papers (incl. oral spotlight)!

5
31
179
16,616
Hyounghun Kim retweeted
27 Jan 2025
🎉 Congrats to the awesome students, postdocs, & collaborators for this exciting batch of #ICLR2025 and #NAACL2025 accepted papers (FYI some are on the academic/industry job market and a great catch 🙂), on diverse, important topics such as:
-- adaptive data generation environments/policies
-- adapting diverse controls to any diffusion model
-- balancing fast and slow system-1.x planning
-- balancing agents' persuasion resistance acceptance
-- multimodal compositional modular video reasoning
-- reverse thinking for stronger LLM reasoning
-- lifelong multimodal instruction tuning via dynamic data selection
-- safe T2I/T2V generation
-- generative infinite games
-- procedural predictive video representation learning
-- bootstrapping VLN via self-refining data flywheel
-- automated preference data synthesis
-- diagnosing cultural bias of VLMs
-- adaptive decoding to balance contextual parametric knowledge conflicts
-- positional bias of faithfulness for long-form summarization
-- improving generation faithfulness via multi-agent collaboration
(PS. Also a big thanks to ACs reviewers for their effort!)

5
33
179
19,038
Hyounghun Kim retweeted

24 Jan 2025
Thrilled to announce that Unbounded has been accepted to #ICLR2025 @iclr_conf! 🎉
Experience our character life simulation game, powered entirely by generative models.
We tackle two key challenges:
1️⃣ Ensuring character and environment consistency with a dynamic regional IP-Adapter.
2️⃣ Enabling real-time interaction using a latent consistency model and a distilled specialized LLM.
Check out our work to see the game in action!
See you in Singapore! 🇸🇬
25 Oct 2024

🎉Excited to introduce our new paper: Unbounded: A Generative Game of Character Life Simulation!
We build a game of character life simulation that is fully encapsulated in generative models.
🌟We achieve this with:
▶️ A specialized, distilled LLM that dynamically generates game mechanics, narratives, and character interactions in real-time.
▶️ A dynamic regional IP-Adapter for vision models that ensures consistent yet flexible visual generation of a character across multiple environments.
🧵

5
24
96
11,535
31 Jan 2025
I am joining POSTECH after spending a couple of years at UNIST. I really appreciate the strong support from UNIST and am excited for this new journey at POSTECH🚀
Thanks to @mohitban47 for the always-thoughtful advice🙏
6
13
45
4,238
Hyounghun Kim retweeted

31 Jan 2025
Complex evaluation is in parts planning and in parts reasoning. Hence, we trained an LLM to think before producing a judgment.
My first work since joining this awesome team 😄
31 Jan 2025

💭🔎 Introducing EvalPlanner – a method to train a Thinking-LLM-as-a-Judge that learns to generate planning & reasoning CoTs for evaluation.
Strong performance on RewardBench, RM-Bench, JudgeBench & FollowBenchEval.
Paper 📄: arxiv.org/abs/2501.18099

4
16
76
7,678
Hyounghun Kim retweeted
21 Jan 2025
Many thanks @RealAAAI for selecting me as a #AAAI Fellow! Very humbled excited to be a part of the respected cohort of this past years' fellows (and congrats everyone)! 🙏
PS. 100% of the credit goes to all my amazing past & current students postdocs collaborators for all their work in these AI areas (& thanks to my mentors family)! 💙
aaai.org/about-aaai/aaai-awa…
21 Jan 2025

🎉Congratulations to Prof. @mohitban47 on being named a 2025 @RealAAAI Fellow for "significant contributions to multimodal AI foundations & faithful language generation and summarization."👏
16 fellows chosen worldwide by cmte of 9 past fellows & ex-pres: aaai.org/about-aaai/aaai-awa…

23
25
182
25,338
Hyounghun Kim retweeted
15 Jan 2025
Deeply honored and humbled to have received the Presidential #PECASE Award by the @WhiteHouse and @POTUS office!
Very grateful to my amazing mentors, students, postdocs, collaborators, and friends family for making this possible, and for making the journey worthwhile beautiful 💙 🙏
(Also congrats to all the winners from the last 4-5 years/batches glad this has been finally announced officially 🙂)
15 Jan 2025
🎉 Congratulations to Prof. @mohitban47 for receiving the Presidential #PECASE Award by @WhiteHouse, which is the highest honor bestowed by US govt. on outstanding scientists/engineers who show exceptional potential for leadership early in their careers!
whitehouse.gov/ostp/news-upd…

ALT Parker Distinguished Professor Mohit Bansal received the Presidential Early Career Award for Scientists and Engineers
58
28
348
30,005
Hyounghun Kim retweeted

11 Dec 2024
🚀 New paper out! 📜 Tackling a long-standing challenge in text summarization: How do we properly conduct human evaluations to improve its systematicity, granularity, and scalability? 🤔 Let’s dive in. 🧵👇
📖 Read the full paper here: arxiv.org/abs/2412.07096

3
29
63
10,988
Hyounghun Kim retweeted

7 Dec 2024
🚨 I’m on the 2024-2025 academic job market!
j-min.io
I work on ✨ Multimodal AI ✨, with a special focus on enhancing reasoning in both understanding and generation tasks by:
1⃣Making it more scalable
2⃣Making it more faithful
3⃣Evaluating and refining multimodal generation
I’m completing my PhD at @uncnlp with @mohitban47 🙂
I'd love to connect ( I’ll also be at #NeurIPS2024)
Check the summary of my research: 👇🧵

6
42
215
63,716
Hyounghun Kim retweeted
27 Nov 2024
Looking forward to giving this Distinguished Lecture at StonyBrook next week & meeting the several awesome NLP CV folks there - thanks @b_niranjan all for the kind invitation 🙂
PS. Excited to give a new talk on "Planning Agents for Collaborative Reasoning and Multimodal Generation" ➡️➡️ diverse, adaptive, and uncertainty-calibrated AI planning agents that can communicate and collaborate for:
(1) robust and grounded multi-agent reasoning and actions (on math, commonsense, coding, games, etc.)
(2) interpretable, controllable planning/programming for multimodal generation (across text, images, videos, audio, layouts, environments).
Detailed abstract in the link below 👇👇👇 (feel free to join)

Join the Dept of #ComputerScience on December 6th at 2:30 PM to welcome Mohit Bansal, UNC Chapel Hill, who will lecture on "Planning Agents for Collaborative Reasoning and Multimodal Generation." Learn more here: tinyurl.com/jkmex3e9
@AI_SBU @CEASSBU @stonybrooku

3
25
107
22,502
Hyounghun Kim retweeted
16 Nov 2024
And it's a wrap...signing off now 😴😴
Thanks everyone for joining us at #EMNLP2024 & making it memorable engaging -- hope y'all enjoyed the program 🤗 ❤️
PS. A big thanks again to @thamar_solorio, @yunnungchen, yaser all the awesome committee members for all their effort!


13
17
253
16,666
Hyounghun Kim retweeted
22 Oct 2024
🚨 How to train LLMs to be persuaded *the right amount* (i.e., not be over-stubborn nor over-gullible)?
Balancing: 1⃣ defending against negative persuasion (makes answers worse / misinfo, jailbreaking, etc.) with 2⃣ accepting positive persuasion (makes answers better)? ➡️➡️➡️ Our multi-agent method, Persuasion-Balanced Training (PBT) recursively creates positive/negative persuasion RLHF data from generated dialogue trees and then trains LLMs to be persuaded when appropriate!
Across 3 models of varying sizes, PBT:
-- improves resistance to misinformation
-- reduces flipflopping
-- obtains best performance on balanced data
-- makes models better teammates
-- improves robustness to ordering sensitivity in multi-agent discussion!
👇👇👇
21 Oct 2024

🚨 Excited to announce “Teaching Models to Balance Resisting and Accepting Persuasion”
LLMs need to be able to reject negative persuasion (e.g. misinfo, jailbreaking, etc)... BUT we argue that they also need to accept positive persuasion (e.g. when they are wrong/unsafe) to be helpful!
We take a 1st step in balancing: 1⃣ defending against negative persuasion (makes answers worse) with 2⃣ accepting positive persuasion (makes answers better), training LLMs to accept persuasion when appropriate.
Our multi-agent method, Persuasion-Balanced Training (PBT) recursively creates RLHF training data from generated dialogue trees and then trains models on positive/negative persuasion.
Across three models of varying sizes, PBT
-- improves resistance to misinformation
-- reduces flipflopping
-- obtains best performance on balanced data
-- makes models better teammates/robust to ordering in multi-agent discussion
When pairing 2 LLMs in a multi-agent debate, we find that pairs generally have a lot of order-dependence. Depending on whether the stronger or weaker model goes first, the team lands on the stronger or weaker answer. PBT reduces this variability and improves team performance.
🧵👇

14
29
3,891
Hyounghun Kim retweeted
17 Oct 2024
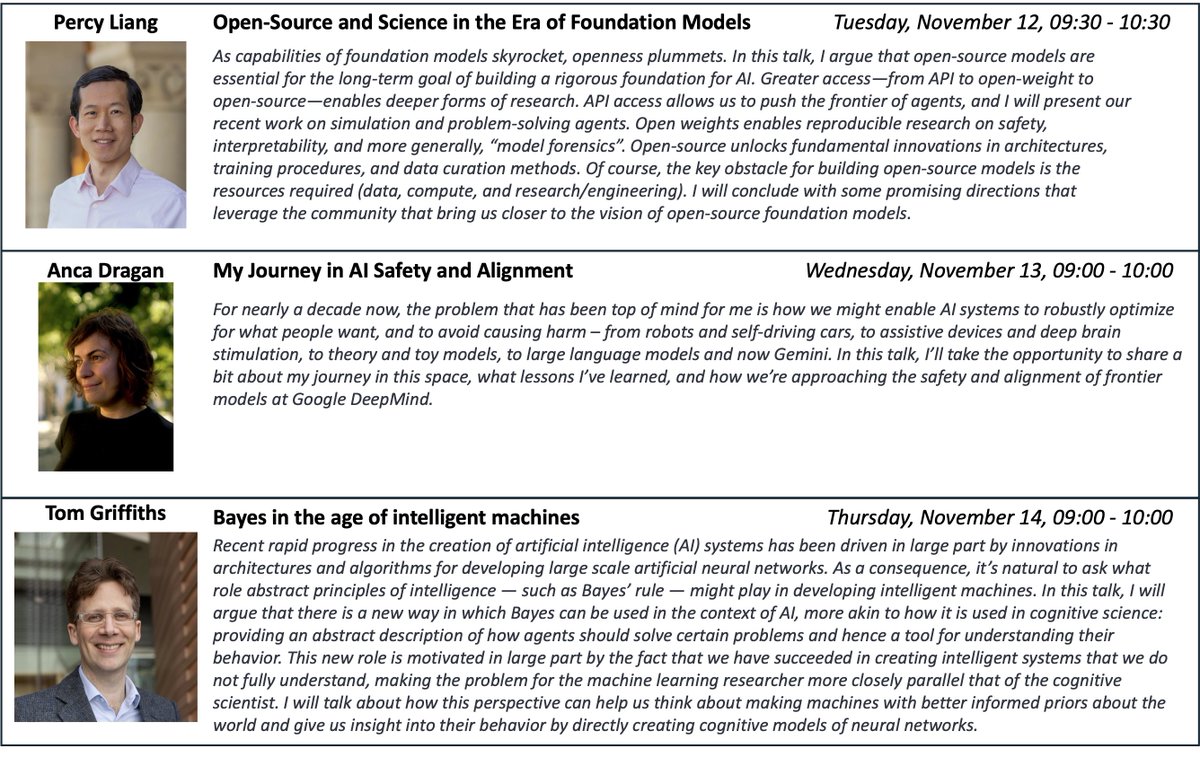
🌴🚨 Join us in Miami (Nov 12-14) for 3 insightful #EMNLP2024 keynotes by @percyliang, @ancadianadragan, and @cocosci_lab on open-source science, safety alignment, and Bayes AI ➡️➡️ 2024.emnlp.org/program/keyno…
PS. Stay tuned -- we are also going to announce an exciting panel soon! 🔥
👇👇👇
17 Oct 2024

🚨 We’re thrilled to announce our exciting keynotes for #EMNLP2024 2024.emnlp.org/program/keyno…
1⃣ 11/12: Percy Liang: open-source science
2⃣ 11/13: Anca Dragan: safety alignment
3⃣ 11/14: Tom Griffiths: Bayes AI
See you in Miami! 🌴
@percyliang @ancadianadragan @cocosci_lab
3
29
112
13,309
17 Oct 2024
Multi-session Multi-party = Mixed-session Conversation🧑🤝🧑
Check out the new #EMNLP2024 Findings paper from @jihyoungjang and @kty4119!
17 Oct 2024

Excited to share that "Mixed-Session Conversation with Egocentric Memory" has been accepted to #EMNLP2024 Findings🎉🎉🎉
Special thanks to @kty4119 and @khsquared for their collaboration!
arxiv.org/abs/2410.02503

1
5
12
1,237
Hyounghun Kim retweeted

15 Oct 2024
🎉Final work from my PhD; we explore multimodal instruction tuning in a lifelong learning setting and propose a data selection recipe for effective (re)learning of past and new skills!
On that note, I have joined the amazing team at Databricks @DbrxMosaicAI :)
15 Oct 2024

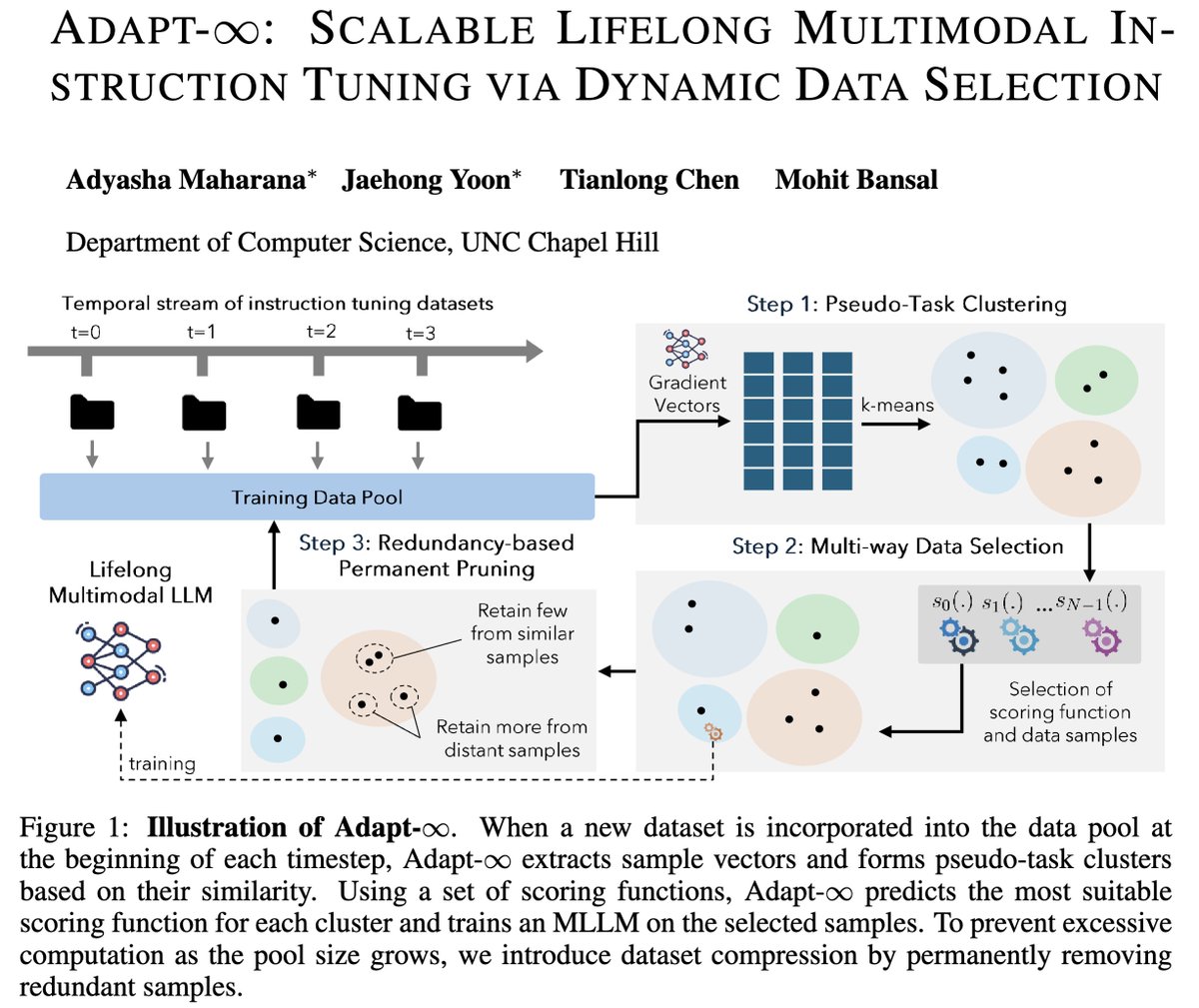
🚨 Introducing Adapt-♾: Scalable Lifelong Multimodal Instruction Tuning via Dynamic Data Selection!
▶️ New multimodal instruction tuning datasets are continuously released, often containing redundant/similar content or targeting highly varied skills (i.e., tasks).
▶️ How can we enable scalable, lifelong instruction tuning for MLLMs, where a temporal stream of multi-task, multimodal instruction-tuning datasets are continually added to the existing training pool?
▶️ We present Adapt-♾, a scalable and adaptive data selection strategy that facilitates the effective learning of MLLM on new skills while reinforcing previously learned skills over time.
📖: arxiv.org/abs/2410.10636
Thread 🧵👇
2
13
55
8,765
Hyounghun Kim retweeted

9 Oct 2024
Exciting work by our @convai_uiuc team!
9 Oct 2024

Congratulations @sumukx @AbhinavChinta10 @VaibhavS2099 @dilekhakkanitur looking forward to your presentation in Miami 🎉
3
7
950