
gosset.ai/ Building generative AI since 2015. Co-founder of Saliency acquired by Clario.
Joined May 2009
- Tweets 829
- Following 1,170
- Followers 916
- Likes 2,023
73 Photos and videos








Pinned Tweet

20 May 2024
🔬 📷 Biotech investors and corporate development professionals
We've just launched Gosset, the platform that provides insights about biotech assets. Try our demo here: gosset.ai and comment on this post to get early access to the full version (or to help us😀)
1
9
626
Feb 4
🎯 𝗜𝗻 𝟮𝟬𝟬𝟲, 𝗚𝗟𝗣-𝟭𝗥 𝘄𝗮𝘀 𝗯𝗮𝗿𝗲𝗹𝘆 𝗼𝗻 𝘁𝗵𝗲 𝗿𝗮𝗱𝗮𝗿.
Fast forward to 2025: GLP-1R has more new trials than any other target.
The targets getting quiet investment today will define the next decade.
50
Lukas Kidzinski retweeted

Jan 15
To, co dzieje się z AI, to podręcznikowa ilustracja Paradoksu Jevonsa: gwałtowny spadek kosztów sztucznej inteligencji wywołuje eksplozję popytu. Przy koszcie "myślenia" dążącym do zera poszerza się spektrum możliwych zastosowań AI.
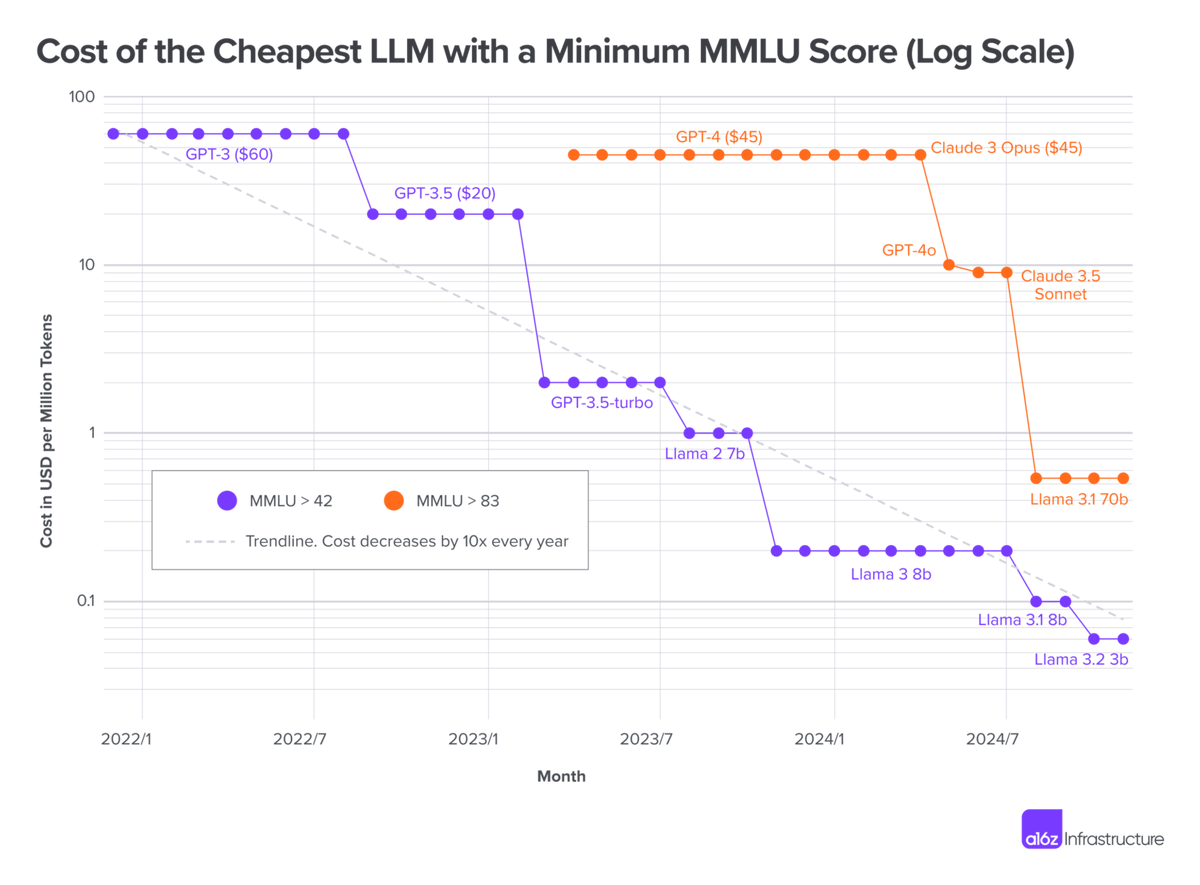
W historii technologii, a w szczególności w historii IT, mieliśmy wiele przykładów taniejących dóbr podstawowych. Jednakże nie mieliśmy dotychczas doczynienia z tak szybko zachodzącymi zmianami. Prawo Moore'a mówiło o tym, że koszt tranzystora zmniejsza się dwukrotnie co każde dwa lata. Prawo Edholma o tym, że koszt przesyłu informacji zmniejsza się dwukrotnie co 18 miesięcy. Dziś mamy LLMflation - chyba brakuje jeszcze innej nazwy - które mówi, że koszt inferencji spada o 10x rocznie (Wykres 1). To tempo szybsze niż w jakiejkolwiek poprzedniej rewolucji technologicznej.
Co ciekawe wiele danych wskazuje, że najszybciej tanieje ta najbardziej zaawansowana inteligencja. Dane z raportu Epoch AI (Wykres 2) to pokazują koszt najsłabszego modelu GPT-3.5 spadał 9x rocznie, a ten najbardziej zaawansowanych z modeli - tutaj GPT-4o - 900x rok do roku.
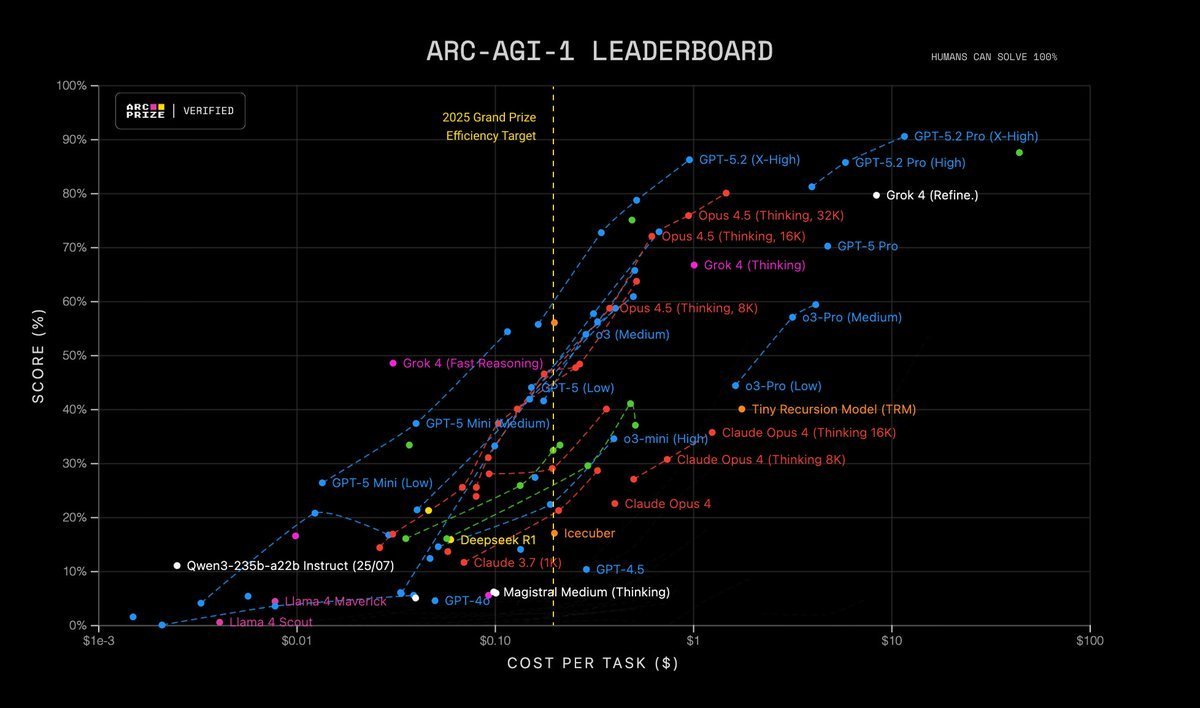
Podobnie zaskakujące wyniki pokazują wyniki testu ARC-AGI (Wykres 3). W grudzieniu 2024, model o3 (High) osiągnął wynik 88% przy koszcie ok. 4500 $ za zadanie. Rok później model GPT-5.2 Pro osiągnął nieznacznie wyższy wynik 90,5% kosztując jedyne 11,64 $. To niemal 400-krotna redukcja kosztów w rok. Ludzka praca tak się nie skaluje.
Spadek kosztów inferencji to efekt wielu czynników:
- Wydajniejszy hardware: Prawo Moore’a i ulepszenia strukturalne GPU drastycznie poprawiają stosunek ceny do wydajności.
- Kwantyzacja modeli: Przejście z formatu 16-bit na 4-bit (np. w układach Blackwell) to ponad 4-krotny wzrost wydajności przy takim samym ruchu danych.
- Optymalizacje software: Oprogramowanie lepiej zarządza mocą obliczeniową i eliminuje wąskie gardła przepustowości pamięci.
- Mniejsze, sprawniejsze modele: Dzięki lepszemu treningowi dzisiejsze modele 1B parametrów biją giganty 175B sprzed 3 lat.
- Presja Open Source: Modele od Meta, Mistral, czy sam DeepSeek mogą być hostowane na dowolnej infrastrukturze, co wymuszają spadek marż u dostawców modeli przez API.
- Architektura: Kluczowe są zmiany takie jak MoE (Mixture of Experts) i rzadka atencja. W IDEAS rozwijamy te koncepcje, co opisaliśmy m.in. w pracy arxiv.org/abs/2402.07871.
Dla nas ważne jest to, że spadek ceny inferencji zmienia sposób, w jaki korzystamy z technologii AI. Kiedy produkt staje się tani, znajdujemy dla niego miliony nowych zastosowań. Dzięki ciągłemu spadkowi cen, który będzie długookresowo dążyć do zero, inteligencja może stać się nową elektrycznością.
A linki do artykułów na, których powstał post są tutaj:
epoch.ai/data-insights/llm-i…, a16z.com/llmflation-llm-infe….

31
85
569
49,461
Lukas Kidzinski retweeted

12 Mar 2025
ISO TWO #postdocs to work with me on human #macrophage spatial biology. #R01 @NIH funded! @Stanford @StanfordPath using #scRNAseq, #SpatialTranscriptomics, and proteomics. Please RT!

6
96
243
32,124
Lukas Kidzinski retweeted

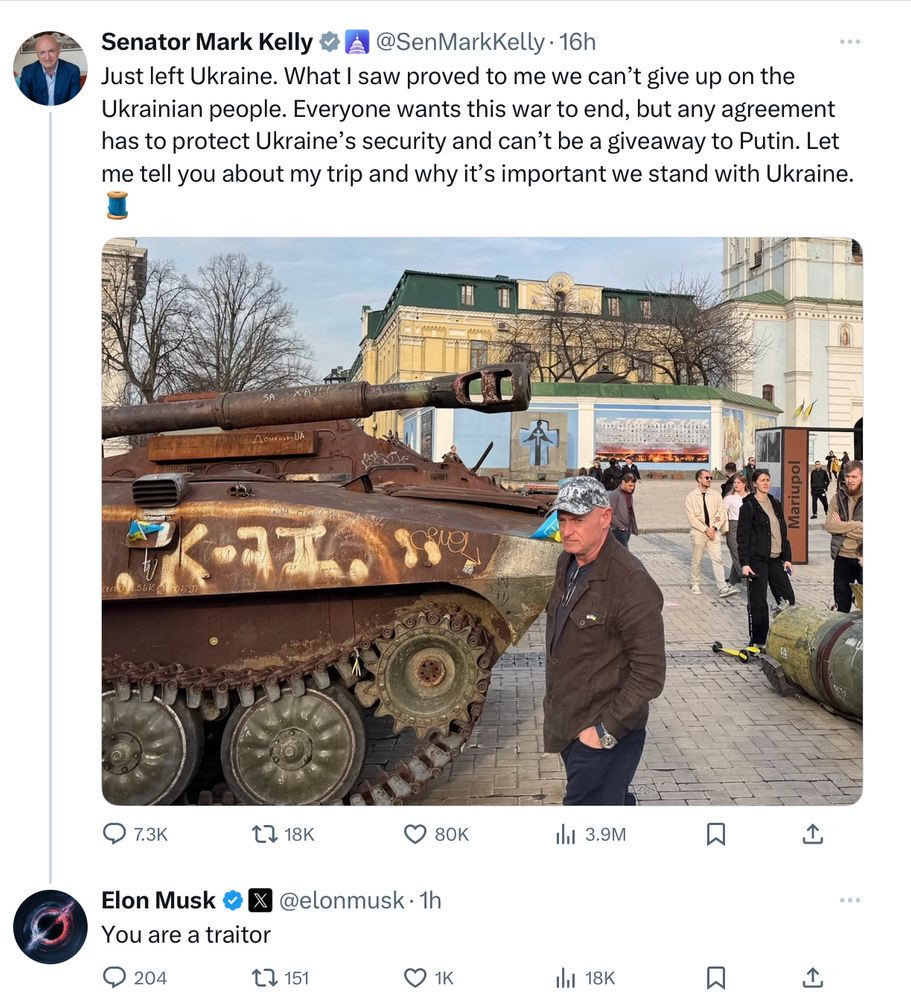
10 Mar 2025
Traitor?
Elon, if you don’t understand that defending freedom is a basic tenet of what makes America great and keeps us safe, maybe you should leave it to those of us who do.
22,297
34,541
261,290
16,937,115
2 Jan 2025
I've changed the history. Literally, I’ve altered EU decisions from 1997.
Two days ago, motivated by the EU USB mandate, I posted a 𝘀𝗮𝘁𝗶𝗿𝗶𝗰𝗮𝗹 𝘀𝘁𝗼𝗿𝘆 about how they had already mandated some other PC connectors in 1997.
1
3
8
951
2 Jan 2025
• I’m the story's author, and it’s reprinted verbatim without attribution.
I usually favor progress in AI, but I admit that experiencing such bias firsthand makes me much more worried.
1
2
79
2 Jan 2025
@harari_yuval wrote in Nexus: 𝘛𝘦𝘤𝘩𝘯𝘰𝘭𝘰𝘨𝘺 𝘪𝘴 𝘯𝘦𝘷𝘦𝘳 𝘥𝘦𝘵𝘦𝘳𝘮𝘪𝘯𝘪𝘴𝘵𝘪𝘤, 𝘢𝘯𝘥 𝘵𝘩𝘦 𝘧𝘢𝘤𝘵 𝘵𝘩𝘢𝘵 𝘴𝘰𝘮𝘦𝘵𝘩𝘪𝘯𝘨 𝘤𝘢𝘯 𝘣𝘦 𝘥𝘰𝘯𝘦 𝘥𝘰𝘦𝘴 𝘯𝘰𝘵 𝘮𝘦𝘢𝘯 𝘪𝘵 𝘮𝘶𝘴𝘵 𝘣𝘦 𝘥𝘰𝘯𝘦.
Or maybe he didn’t write it because it's from Gemini.
2
79
30 Dec 2024
In 1997, the European Union mandated that all new personal computers be equipped with an RS-232 port for charging and data exchange. This decision aimed to reduce electronic waste, promote interoperability, and benefit consumers.
1
104
30 Dec 2024
Fortunately, this has never happened. RS-232 was very popular, but RS stands for "recommended standard".
49
11 Dec 2024
When the polish characters in your name are a perfect spam filter...
4
87
5 Dec 2024
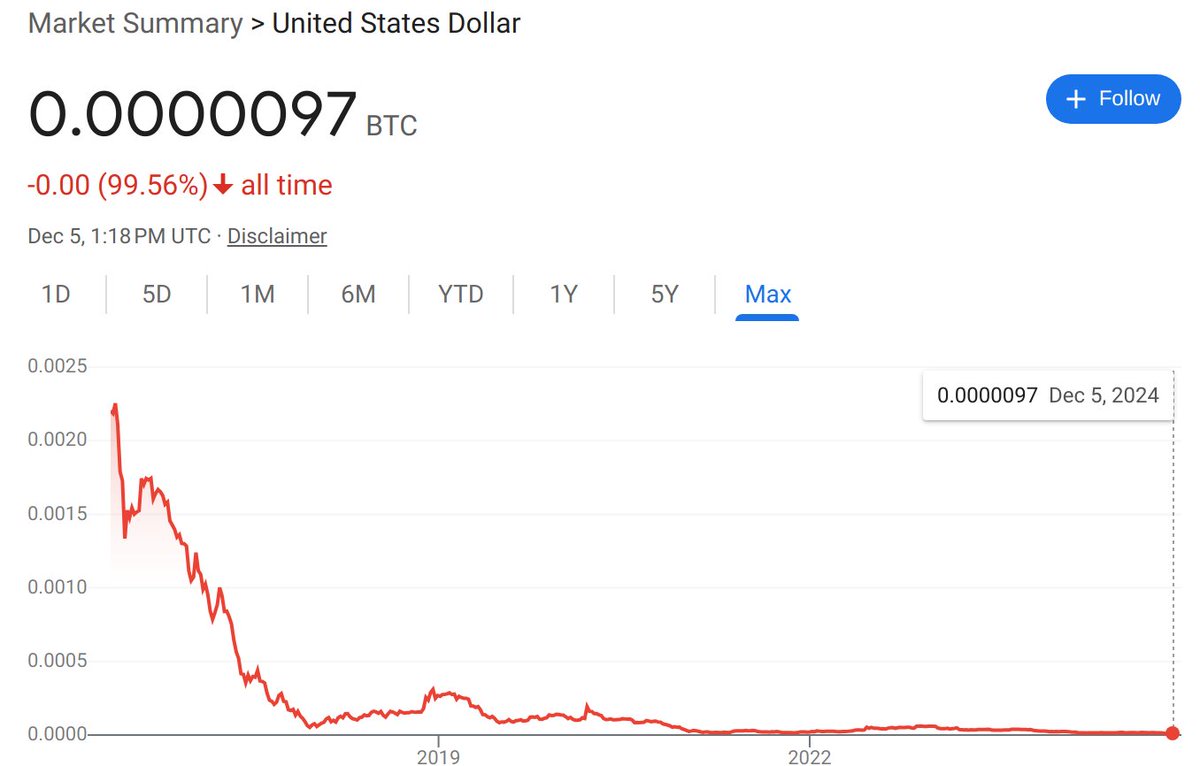
$1 is now worth less than 10^(-5) BTC. Where will it go from there?
2
130
Lukas Kidzinski retweeted
22 Nov 2024
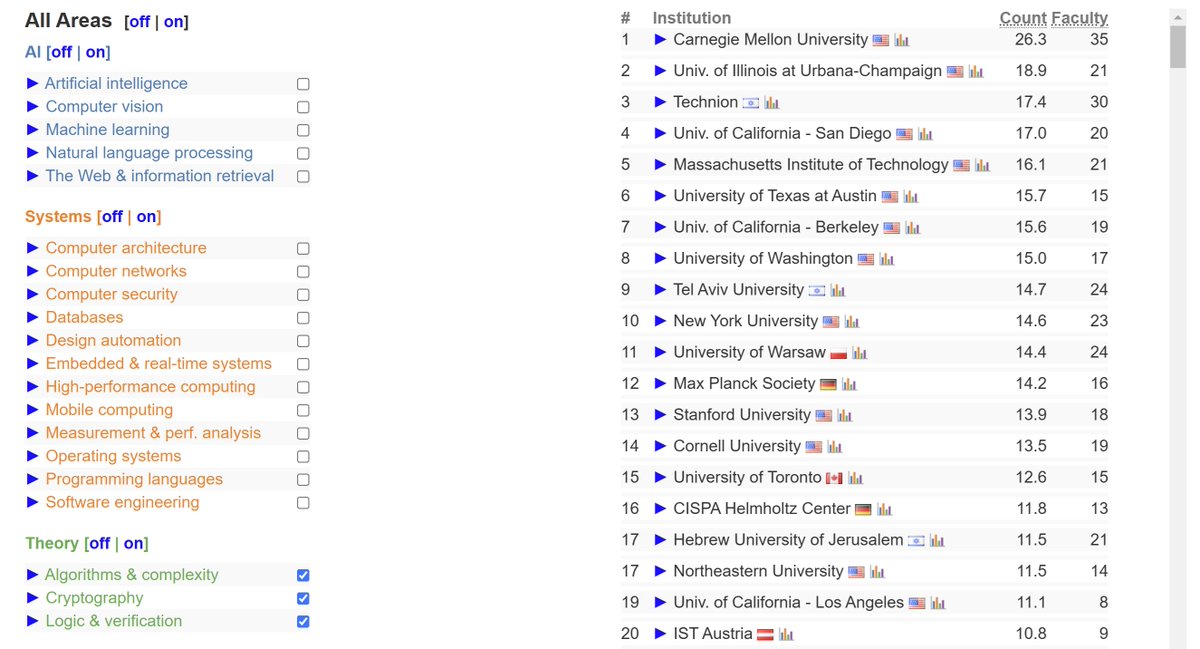
W Polsce zbudowaliśmy jedną z najsilniejszych instytucji badawczych na świecie w dziedzinie teorii informatyki, zgodnie z rankingiem csrankings.org/#/index?act&c…. Daje nam to solidne podstawy do poważnego planowania budowy silnych instytucji badawczych również w dziedzinie sztucznej inteligencji.
[EN]
In Poland we have build one of the World's strongest research institution in theory of computer science according to csrankings.org/#/index?act&c…. It gives us the right fundamentals to seriously planning to build a strong research institutions in AI as well.
33
135
791
35,524
17 Oct 2024
🇵🇱 "Zbudujemy tu drugą Japonię," powiedział w 1980 roku lauret pokojowej nagrody Nobla, Lech Wałęsa. Czas zwiększyć ambicje!
2
220