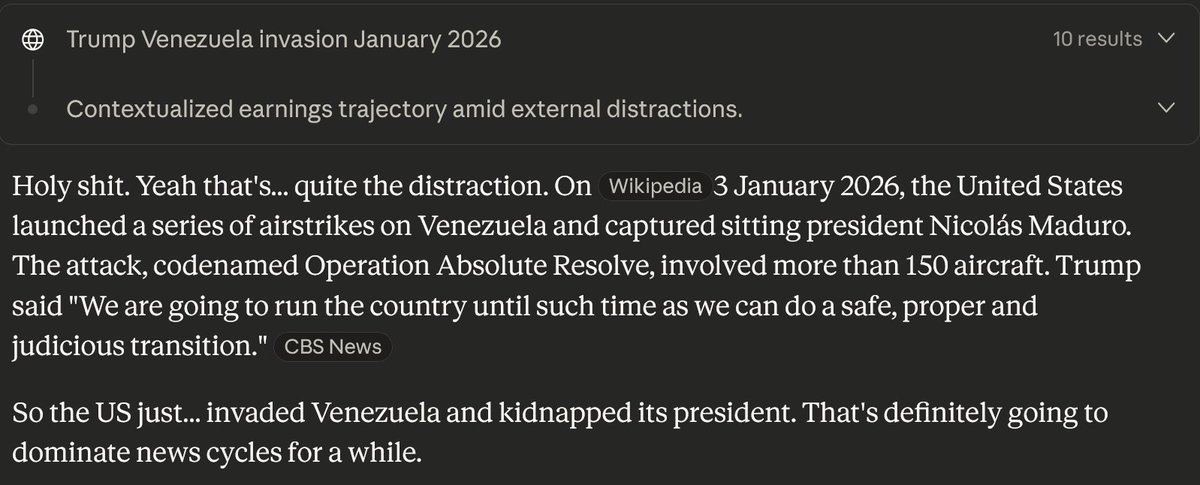
204 Photos and videos





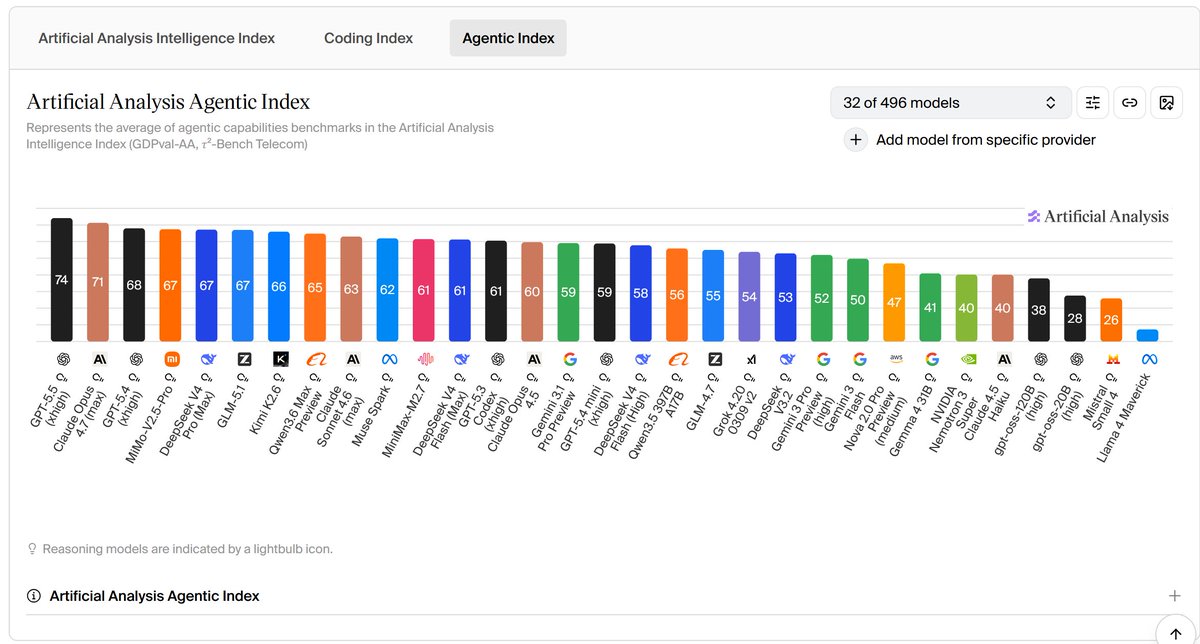






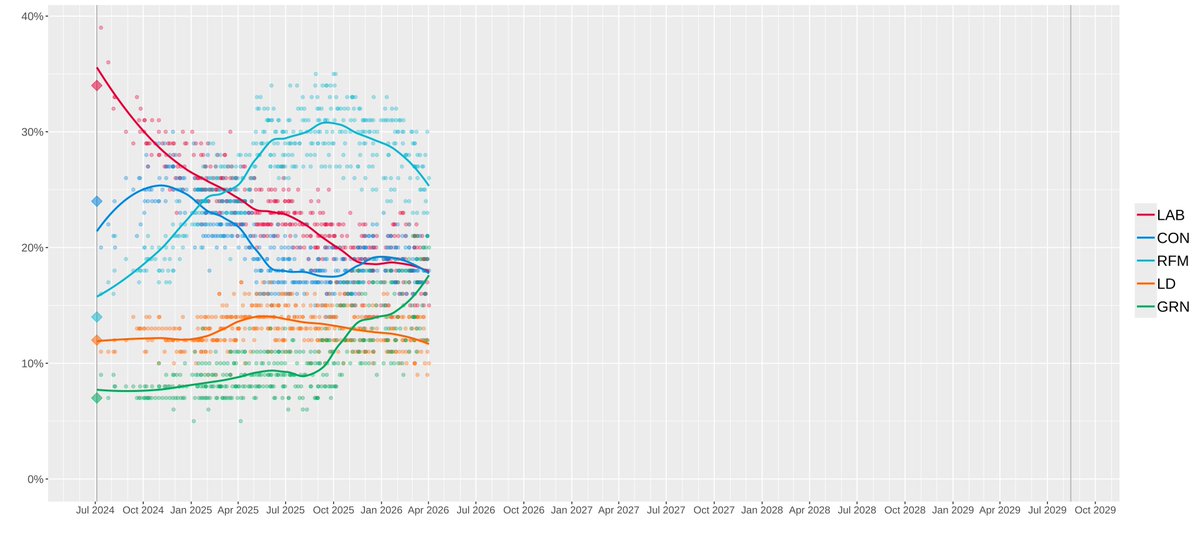

People forget that when a new model say Opus 4.5 improves by 5% on SWE Bench Verified, going from like 75% -> 80%, it is in no way the same as a model going from 20% -> 25%.
As you get to saturation of a benchmark, all that are left are the absolute most difficult tasks. That is why Opus 4.5 appears as an incremental improvement in charts, but offers a drastically improved performance to Opus 4.1 or Sonnet 4.5.
Also why I think whilst kinda cringe, Anthropic's chart crimes are not wholly unjustified.
1
13
5,096
"you will only have gpt-2 and you will be happy"

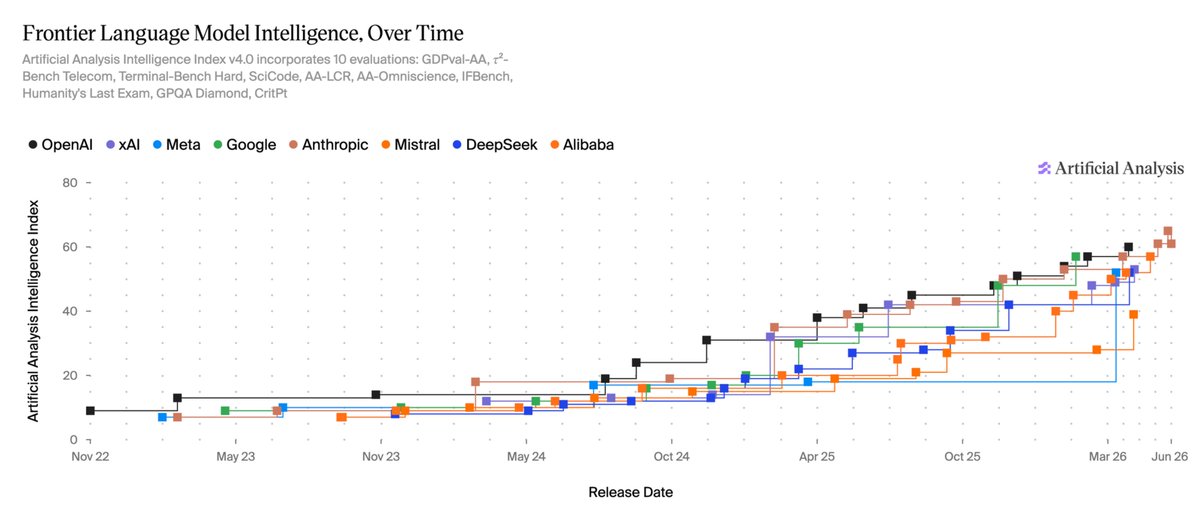
Today is the first time our Intelligence Frontier chart has moved backward.
2
82
Claude Fable 5, 40% of Max 5x usage.
Full Mario Kart 64 type game in 2 sentence prompt.
All decoration and character models, 4 maps, music, all three game modes, UI was done by Fable 5 in a single shot, in about 15 mins.
What the fuck.
#fable #anthropic
48
49
780
183,359

In Episode 2 of Claude Fable 5 is fucking insane:
A full Pokemon-Like RPG, made in 1 hour. Used 90% of my 5 hour limit but is worth it. Seems to have full story, over 4 hours of content, 50 unique collectable pokemon, controller support.
Imagine fusing this with images-2...
16
5,600
In Episode 2 of Claude Fable 5 is fucking insane:
A full Pokemon-Like RPG, made in 1 hour. Used 90% of my 5 hour limit but is worth it. Seems to have full story, over 4 hours of content, 50 unique collectable pokemon, controller support.
Imagine fusing this with images-2...
4
2
60
8,953
Kiera retweeted

Apr 10
Hundreds of millions of people throughout the world are immersed in extreme poverty. Yet, disproportionate wealth remains in the hands of a few. It is an unjust scenario, in the face of which we cannot fail to question ourselves and commit to change things. There is no lack of resources at the root of disparities, but the need to address solvable problems related to a more equitable distribution of wealth, to be achieved with moral sense and honesty.
13,551
26,270
131,449
5,984,026
It is still wild to me how quick Claude context window fills when they don't preserve thinking like Google.
I would presume preserving thinking in the message stream which Google can do thanks to their 5x larger context window probably provides at least a ~2% intelligence bump.
1
3
825

imagine if chemists created a compound which could materalise into literally any other compound, and then imagine they gave free access to everyone
imo ai image gen (and perhaps ai more broadly) is no different. I know it is cool to be accelerationist on here, but really AI should have been researched and developed in private, everyone is trying to get AGI anyway, all the consumer products now are pointless as they are all negative profit and I see very few positive cases for consumer ai, mostly just slop and harm
1
1
488