
NLP researcher (question answering, information extraction)
Joined April 2018
- Tweets 1,534
- Following 260
- Followers 366
- Likes 2,178
37 Photos and videos
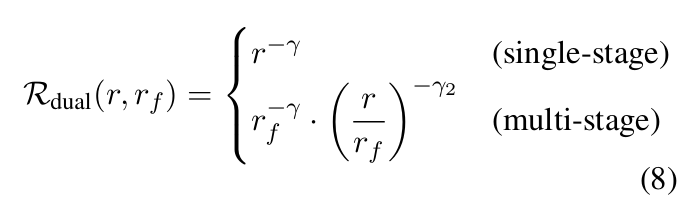
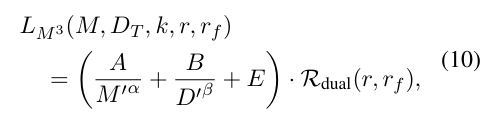






Pinned Tweet

Jun 3
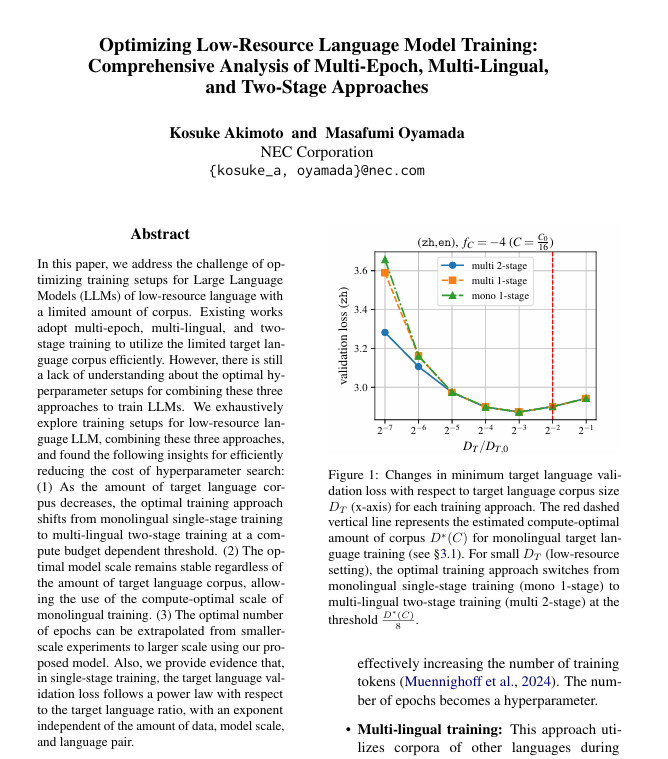
We just posted our paper: “M^3 Scaling Law: Optimizing Multi-Epoch, Multi-Lingual, and Multi-Stage Training for Low-Resource Language Models.”
Joint work with @kanaheinousagi and @stillpedant.
In this thread, I’ll explain the main idea and key findings. (1/N)
1
5
15
4,294
Jun 12
知能じゃなくて実験を回すラボリソースが当面ボトルネックになる(というか最近自分に関してはそうなってきた)から、制御不能なモデルの自律進化は懸念されてるようなコミュニティではなくハイパースケーラーからしか出てきようがない気もする。
既存モデル自体の悪用は当然別だろうけど。
101
Jun 3
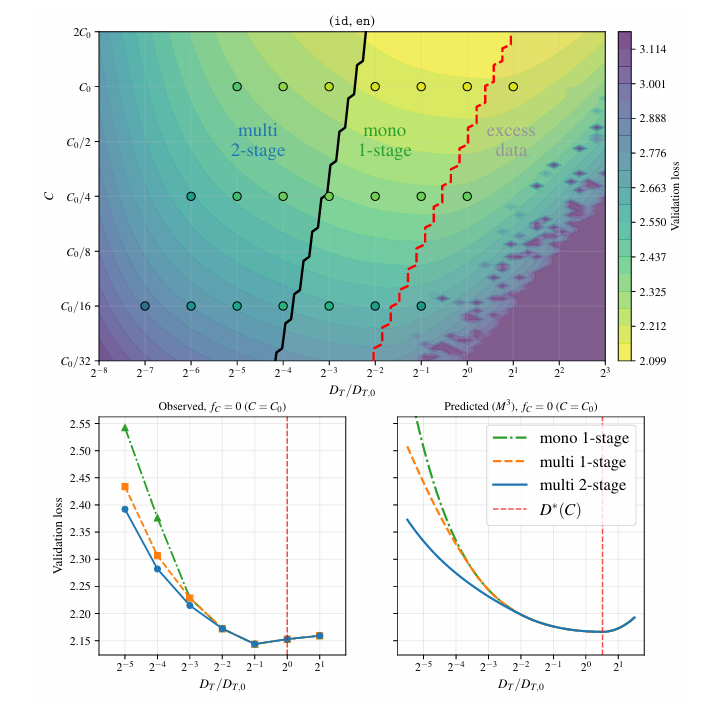
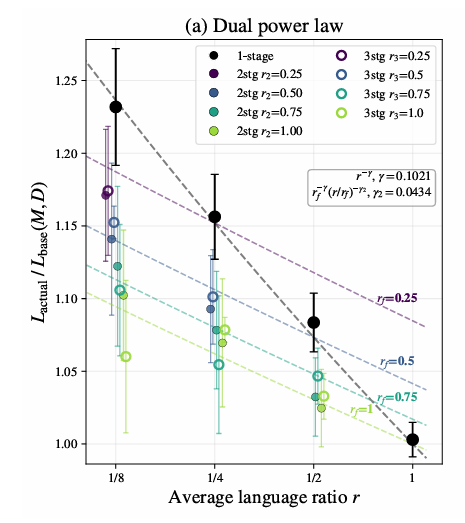
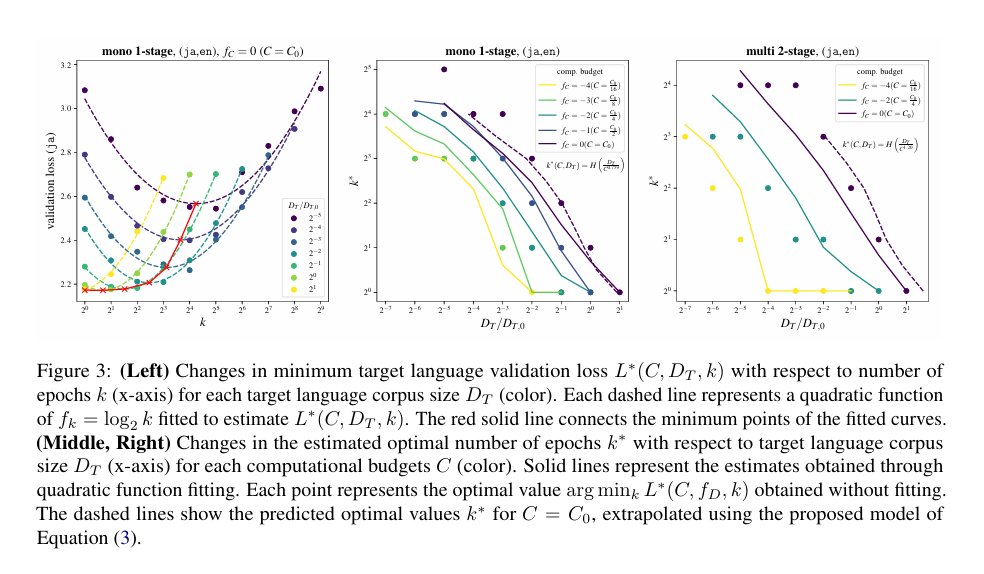
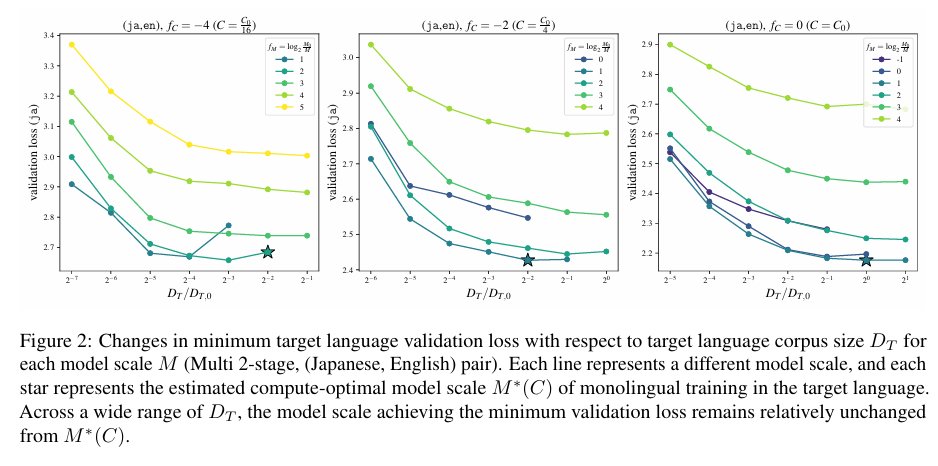
複数エポックや多言語学習の効果に加えて、多段階学習の効果もモデリングする"M^3 Scaling Law"を新しく提案しました!📈
多段階学習の効果は①平均言語割合と②最終言語割合「だけ」に依存するdual power lawでよくモデル化できる、という面白い観察結果も得られています!
Jun 3

We just posted our paper: “M^3 Scaling Law: Optimizing Multi-Epoch, Multi-Lingual, and Multi-Stage Training for Low-Resource Language Models.”
Joint work with @kanaheinousagi and @stillpedant.
In this thread, I’ll explain the main idea and key findings. (1/N)
1
16
2,652
Jun 3
We just posted our paper: “M^3 Scaling Law: Optimizing Multi-Epoch, Multi-Lingual, and Multi-Stage Training for Low-Resource Language Models.”
Joint work with @kanaheinousagi and @stillpedant.
In this thread, I’ll explain the main idea and key findings. (1/N)
1
5
15
4,294
Jun 3
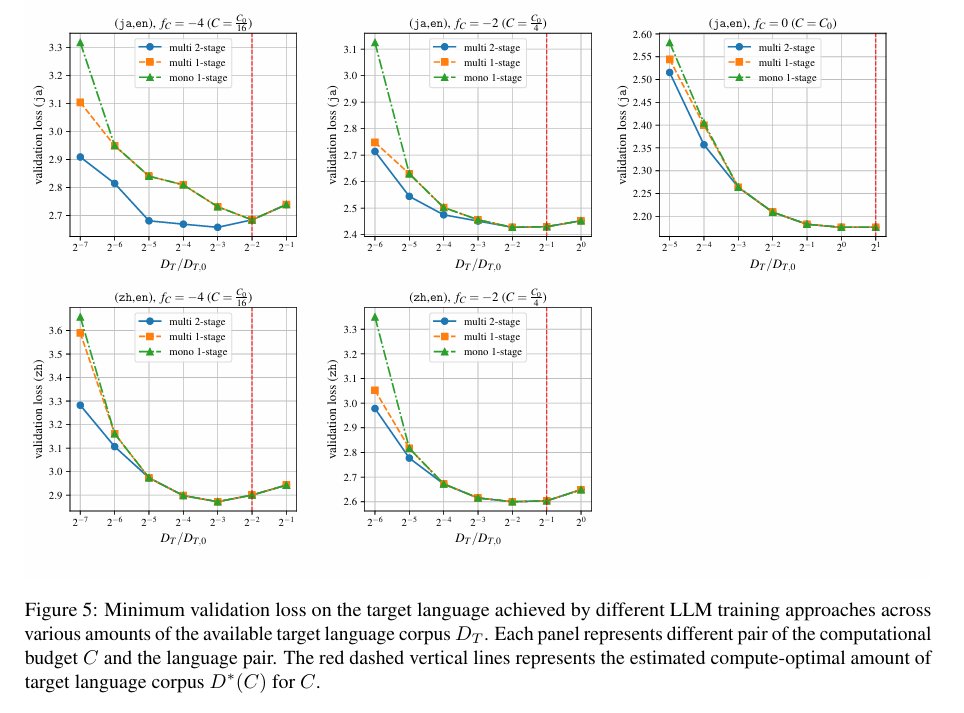
M^3 gives a scaling-law explanation for why late target-heavy stages can be effective in continued pretraining and mid-training.
It predicts when this should be preferred under fixed compute and target-data budgets. (10/N)
1
1
78
Jun 3
Overall, M^3 adds multi-stage training to scaling-law recipe design.
Beyond “how often should we repeat target data?” or “how much high-resource data should we mix?”, it additionally asks whether a staged recipe should be used or not! (11/N)
1
64
May 31
同期とか年下の人が出ていくよりも、先輩だった人が退職する方が、自分にとっての「職場の空気」が変質するという意味で心理的影響はでかいな。
入社した時に周りにいた人たちっていうのはなんだかんだ自分のルーツの一部になってるのか。
2
162
K. Akimoto retweeted

May 26
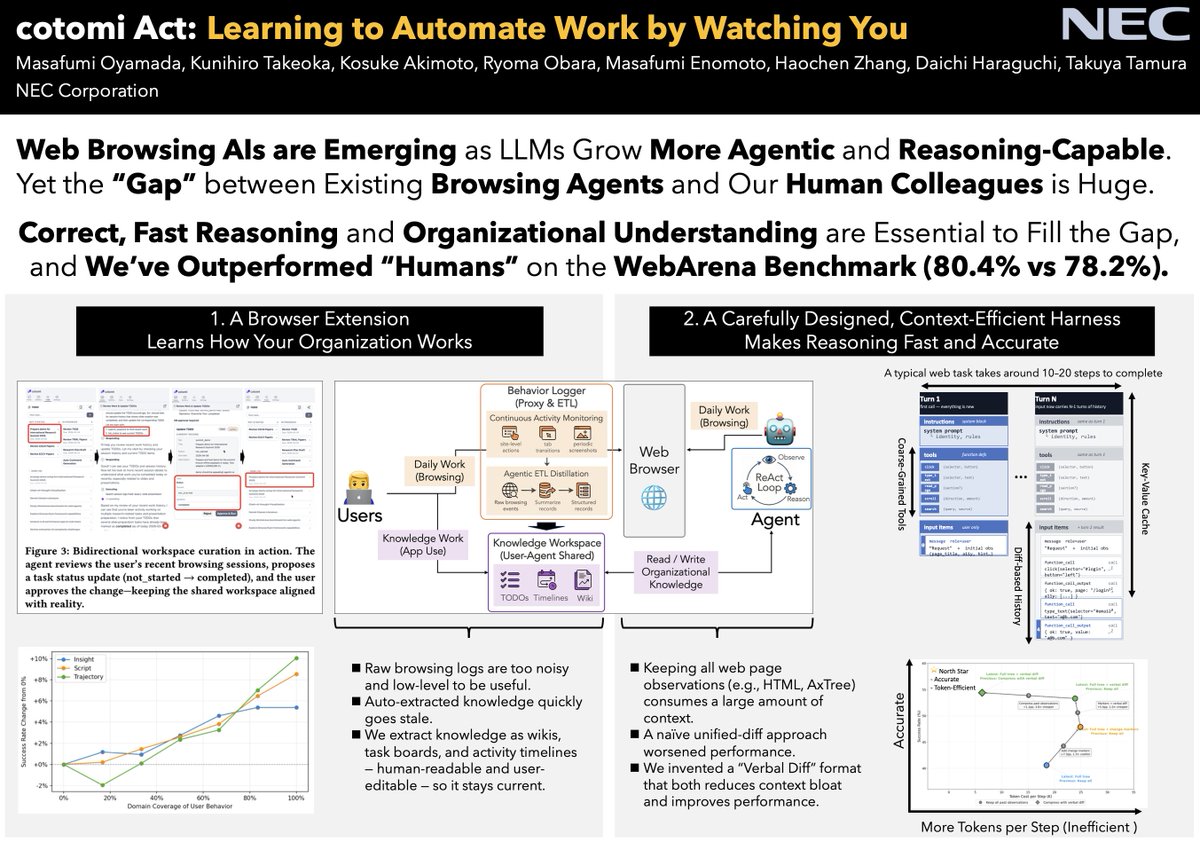
We’ll demo cotomi Act on May 27—come say hi!
alphaxiv.org/abs/2605.03231
cotomi Act is a web browsing copilot built from two ingredients:
(1) a carefully designed, context-efficient browser harness
(2) a brand-new “big sibling” that watches your daily work and learns from it
1
3
4
774
May 11
LLMが賢くなってある分野で自分が抜かされて自信を無くすみたいなことあるけど、LLM+自分のチームで考えると自分の能力スタックで足引っ張ってた所が順次底上げされていく感じだから、自分が一番輝ける能力で抜かされるまではむしろ自分でやれる質が上がって自信が深まるのもありそうと思い始めた
3
232